机器学习模型设计五要素
数据可能没什么用,但是数据中包含的信息有用,能够减少不确定性,数据中信息量决定了算法能达到的上限。
数据环节是整个模型搭建过程中工作量最大的地方,从埋点,日志上报,清洗,存储到特征工程,用户画像,物品画像,都是些搬砖的工作也被认为最没有含金量同时也是最重要的地方。这块跟要解决的问题,所选的模型有很大关系,需要具体问题具体分析,以个性化为例讲讲特征工程中的信息损失:
我们搭模型的目的是预测未来 -“以往鉴来,未卜先知 ”,进一步要预测每个人的未来,实时预测每个人的未来。要想做好这件事情,对过去、对用户、对物品越了解越好,首先需要采集用户的行为(什么人在什么时间什么地点以什么方式对什么东西做了什么事情做到什么程度
),然后进行归因找到影响用户点击的因素,构建用户兴趣图谱,最后在此基础上去做预测。
这个过程中,每个环节都会有信息损失,有些是因为采集不到,比如用户当时所处的环境,心情等等;有些是采集得到但是暂时没有办法用起来,比如电商领域用户直接感知到是一张图片,点或不点很大程度上取决于这张图片,深度学习火之前这部分信息很难利用起来;还有些是采集得到,也用的起来,但是因为加工手段造成的损失,比如时间窗口取多久,特征离散成几段等等。
起步阶段,先搞“量”再搞“率”应该是出效果最快的方式。
#2 f(x)
f(x)的设计主要围绕参数量和结构两个方向做创新,这两个参数决定了算法的学习能力,从数据里面挖掘信息的能力(信息利用率),类比到人身上就是“天赋”、“潜质”类的东西,衡量这个模型有多“聪明”。相应地,上面的{x,y}就是你经历了多少事情,经历越多+越聪明就能悟出越多的道理。
参数量表示模型复杂度,一般用VC维衡量。VC维越大,模型就越复杂,学习能力就越强。在数据量比较小的时候,高
VC 维的模型比低 VC 维的模型效果要差,但这只是故事的一部分;有了更多数据以后,就会发现低 VC 维模型效果再也涨不上去了,但高的 VC
维模型还在不断上升。这时候高VC维模型可以对低VC维模型说:你考90分是因为你的实力在那里,我考100分是因为卷面只有100分。
当然VC维并不是越高越好,要和问题复杂度匹配:
-- 如果模型设计的比实际简单,模型表达能力不够,产生 high bias;
-- 如果模型设计的比实际复杂,模型容易over-fit,产生 high variance;而且模型越复杂,需要的样本量越大,DL动辄上亿样本
模型结构要解决的是把参数以哪种方式结合起来,可以搞成“平面的”,“立体的”,甚至还可以加上“时间轴”。不同的模型结构有自身独特的性质,能够捕捉到数据中不同的模式,我们看看三种典型的:
LR:
只能学到线性信息,靠人工特征工程来提高非线性拟合能力
MLR:
与lr相比表达能力更强,lr不管什么用户什么物品全部共用一套参数,mlr可以做到每个分片拥有自己的参数:
-- 男生跟女生行为模式不一样,那就训练两个模型,男生一个女生一个,不共享参数
-- 服装行业跟3C行业规律不一样,那就训练两个模型,服装 一个3C一个,不共享参数
沿着这条路走到尽头可以给每个人训练一个模型,这才是真正的“个性化”!
FM:
自动做特征交叉,挖掘非线性信息
DL:
能够以任意精度逼近任意连续函数,意思就是“都在里面了,需要啥你自己找吧”,不想花心思做假设推公式的时候就找它。
#3 objective
目标函数,做事之前先定一个小目标,它决定了接下来我们往哪个方向走。总的来说,既要好又要简单;已有很多标准方法可以选,可创新的空间不大,不过自己搞一个损失函数听起来也不错,坐等大牛。
-
损失函数:rmse/logloss/hinge/...
-
惩罚项:L1/L2/L21/dropout/weight decay/...
P(model|data) = P(data|model) * P(model)/P(data) —> log(d|m) + log(m)

#4 optimization
目标有了,模型设计的足够聪明了,不学习或者学习方法不对,又是一个“伤仲永”式的悲剧。 这里要解决的问题是如何更快更好的学习。抛开贝叶斯派的方法,大致分为两类:
启发式算法,仿达尔文进化论,通过适应度函数进行“物竞天择,适者生存”式优化,比较有代表性的:遗传算法GA,粒子群算法PSO,蚁群算法AA;适合解决复杂,指数规模,高维度,大空间等特征问题,如物流路经问题;问题是比较收敛慢,工业界很少用。
拉马克进化论,获得性遗传,直接修改基因(w);比较有代表性的分两类:
-- sgd variants(sgd/Nesterov/Adagrad/RMSprop/Adam/...)
-- newton variants(newton/lbfgs/...)
#5 evaluation
怎么才算一个好的模型并没有统一标准,一个模型部署上线或多或少的都会牵扯到多方利益。以个性化场景为例,就牵扯到用户,供应商/内容生产方以及产品运营三者的博弈。总的来说,一个“三好模型”要满足以下三个层面:
-
算法层面:准确率,覆盖率,auc,logloss...
-
公司层面:revenue,ctr,cvr...
-
用户层面:用户体验,满意度,惊喜度...
#0 模型调优思路
拆解之后,模型调优的思路也很清晰了:
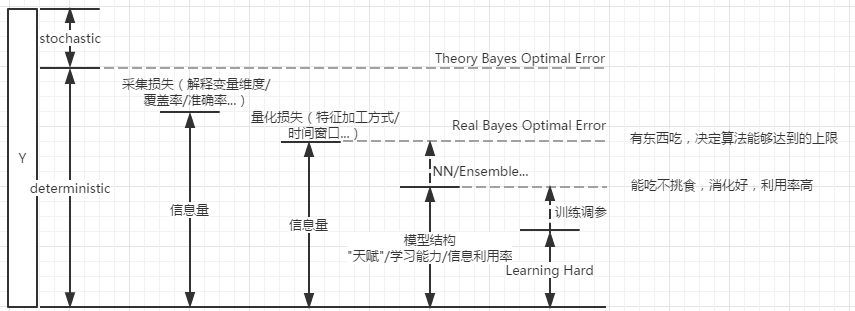
想长胖,首先要有东西吃;其次要能吃,啥都能吃不挑食;最后消化要好
用一条公式来概括:模型效果 ∝ 数据信息量 x 算法信息利用率
-
一方面,扩充“信息量”,用户画像和物品画像要做好,把图片/文本这类不好量化处理的数据利用起来;
-
另一方面,改进f(x)提高“信息利用率”,挖到之前挖不到的规律;
不过在大数据的初级阶段,效果主要来自于第一方面吧。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330