大数据使一个新时代应运而生
在“大数据”趋势的驱动下,企业具有更大规模的收集和处理数据的能力,越来越广泛的信息加速了各行各业决策的速率和准确率。而大数据的“大”,已成为存储业界目前所面临的严峻挑战。据IDC预测,到2015年,大数据技术和服务市场将从2010年的32亿美元增长到169亿美元,年复合增长率(CAGR)达到39.4%,几乎是整个信息和通信技术市场年复合增长率的七倍。快速的数据流转,动态的数据体系,以及越来越多样化的数据类型,面对如此海量的数据规模,尽管业界的专业人士不断的推崇“大数据”,但其所带来的复杂程度和处理难度,使得企业不得不去重新考虑存储基础架构的问题。
随着企业不断寻求通过各种方法创新并为客户构建更好的解决方案,他们面临的一个最大挑战是,如何使真正对社会具有深远意义以及可持续影响力的创新解决方案实现商业化。据 IDC 调查,到2014年,绝大部分数据将是非结构化数据。因此,在数据大爆炸或大数据的背景下,我们需要具备发挥非结构化数据巨大潜力的能力,以便生成新的可持续业务、从现有资产获取经济价值并提高用户生产效率。
大数据洞察,基础架构先行
大数据数量庞大,格式多样化。大量数据和信息由家庭和办公场所的各种设备生成。它的爆炸式增长已超出了传统IT基础架构的处理能力,给企业带来严峻的数据管理问题。
IDC认为传统的基础架构不能满足大数据需求和挑战。支持大数据部署的架构必须可以动态调整,并具备以下主要特性:
按需提供的容量和可扩展性,使基础架构能够在必要时根据容量和性能扩展或缩减规模。
维持“始终在线”的环境以及防止计划外停机的故障恢复能力。
内置数据管理,并且能够在每个处理阶段以及每个后处理常规运行阶段管理数据保护、监管达标、处置和同化。
针对大数据的容量需求,存储虚拟化是目前为止提高容量效率最重要最有效的解决方案,它为缺乏这些能力的现有存储系统拓展了自动分层和精简配置等存储效率的工具。拥有了虚拟化存储,便可以将来自内部、外部和多厂商存储的结构化和非结构化数据的文件、内容和块存储等所有的数据类型,整合到一个单一的存储平台上。当所有存储资产成为一个单一的存储资源池时,自动分层和精简配置功能就可以扩大到整个存储基础设施,从而可以轻松实现容量回收和利用最大化,甚至达到重用现有资产以延长使用,显著提高IT灵活性和容量效率,以满足非结构化数据增长的需求。目前,借助HUS中型企业可以在不影响性能的情况下能够扩展系统容量达到近3PB,自动更正性能问题,通过动态虚拟控制器实现快速预配置。此外,通过VSP的虚拟化,大型企业可以创建接近四分之一EB容量的存储池。
针对非结构化数据,传统文件系统中有限的索引节点总数导致文件系统可以容纳的文件、目录或其它对象的最大数量受到限制。而HNAS和HCP使用基于对象的文件系统,这使它们能够扩展到PB级,以及数十亿的文件或对象。位于VSP或HUS顶部的HNAS和HCP网关可以充分利用模块存储的可扩展性,同时享受到通用管理平台Hitachi
Command Suite带来的好处。HNAS和HCP为大数据文件和内容构建起了相应的架构。
除了可扩展性,大数据必须能够不受干扰地持续扩展并具有跨越不同时代技术的迁移能力。数据迁移必须保持在最小范围,且在后台完成。大数据应该只需要复制一次便可以恢复可用性;通过版本控制来跟踪变更,而不是为大数据发生的每一个变更备份整个大数据。大数据太大而无法整体备份。整个HDS的产品系列均可以实现数据的后台移动和分层,也可以增加VSP或HUS块数据池、HNAS文件系统或HCP租户的容量,并自动在新的容量中调整数据。旧的文件系统与块数据存储设备不支持动态扩展。为了使用新的存储容量,这些旧系统中的数据不得不从旧的块数据存储或文件系统中重新加载到新的存储容量中。
不论企业规模大小,信息过载都是长期以来难以解决的问题。企业需要高度集成的基础架构堆栈,以便统一地对所有来源的大数据进行汇聚、访问管理、分析和交付。这需要基础架构能够管理和理解信息。根据及时、相关、全面、准确的信息而非猜测来采取行动,企业也会因此赢得竞争优势。反之,则会在浩瀚的信息中受制于繁杂的数据、拘泥不前。
三步走,轻松驾驭大数据
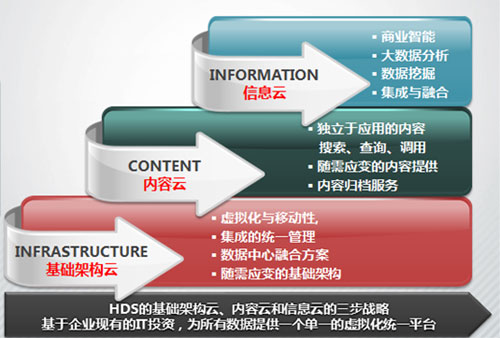
基于对云计算和大数据的深入研究,HDS提出了三步云战略,即基础架构云、内容云和信息云。三步云战略基于企业现有的IT设施,为企业的所有数据提供单一的虚拟化平台。其中基础架构云目的为提供动态基础架构,以实现支持所有数据的单一平台。而内容云则基于这一单一平台,借助智能工具,实现对所有类型数据的索引、搜索和发掘。让数据可以更容易地被发现、共享并且重新利用,因而也会变得更有价值。在信息云中,和大数据会更加关联,让各种信息分析工具和流程与底层基础架构完美集成。连接不同的数据集,揭示其中的规律,以为企业用户提供有价值的信息和商业洞察,帮助客户应对在医疗、生命科学、能源研究、社会基础设施等领域的挑战。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330