SPSS中两种重复测量资料分析过程的比较
在SPSS中,有两个过程可以对重复测量资料进行分析:一种是一般线性模型的重复度量;一种是混合线性模型,对于同样的数据资料,使用两种过程分析出的内容不大一样,注意是内容而不是结果,只要操作正确,结果应该是一致的,而输出内容的差异则反映了两种方法的侧重点不同,那么两种方法有何异同以及使用时该如何选择呢?可以从下几个方面进行探讨
一、基本思路不同
重复度量:重复度量的分析思路还是是基于传统的方差分析思想,即变异分解,只不过在分解时加入了对象间变异和对象间与时间交互作用的变异两部分,模型还是一般线性模型的范畴,这点从结果输出日志的标题中也可以看出,但是在SPSS操作中,并不需要选入因变量。
混合线性模型:混合线性模型是一般线性模型的推广,是专门用来解决因变量非独立的数据,也就是层次聚集性数据。而重复测量资料就是属于此类数据,因此混合线性模型对重复测量资料的数据分析是从纯粹的模型求解的角度出发,而不是变异分解,在SPSS操作中需要选入因变量。
二、结果中某些算法不同
实际上二者的算法并非完全不同,毕竟独属于多元分析,还是有类似的地方。
重复度量:从分析结果中可以看出,重复度量结果既包含一元分析也包含多元分析,并且以Mauchly球形度检验作为选择标准,实际上球形度检验就是将重复测量资料看做是配对t检验的推广,通过检验两两时间点之间差值的方差协方差矩阵来判断该资料因变量之间是否真的存在相关性。其多元分析结果部分,和多元方差一样使用了四种检验方法,都是基于矩阵计算的。在参数估计上,和一般线性模型一样,使用的是对比矩阵,以某一水平为参照,其余水平和其进行对比进行计算
混合线性模型:无论是参数估计还是其他结果的计算,都使用了更加稳健的多元分析方法,如极大似然法、迭代法、熵等
三、应用范围不同
重复度量:主要用来分析因素效应和交互作用对实验结果的影响,因素效应和交互作用是否存在时间趋势,以及进一步分析各因素水平间的两两比较等,在SPSS操作中并不涉及因变量,只是分析因素之间的关系,离不开一般线性模型的分析范畴,并且在重复度量中也没有办法加入随机因素
混合线性模型:既然是一般线性模型的推广,那么其应用范围肯定比一般线性模型要广,除了可以对层次聚集性数据进行分析之外,还可以加入随机效应,建立回归模型,并且可以指定协方差矩阵的类型,还可以对嵌套实验设计进行分析。可以说,重复度量能做的分析,混合线性模型都能做,而反过来则未必。
四、数据输入的格式不同
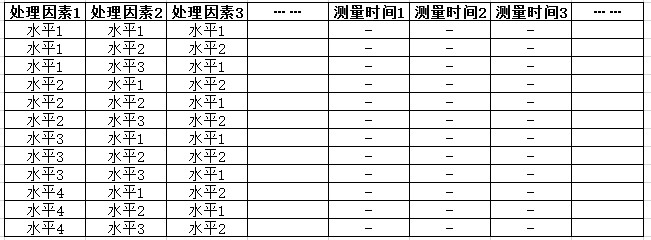
重复度量:由于重复度量是以方差分析为基础,将每次测量时间作为一种单独的因素看待(对象内变异因素),数据输入格式中,每次测量时间单独为一列变量,测量数据就输入在每次测量的时间下面,数据格式如下
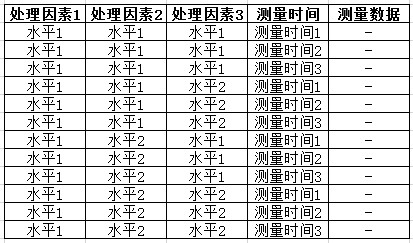
混合线性模型:将时间总的作为一种因素(变量),各个时间点为不同的水平,数据格式为标准的多水平模型,测量数据也单独为一个变量,与相应的测量时间对应,在分析时,测量数据一般作为因变量,时间作为协变量,具体数据格式如下
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330