如何面对PB级别数据的架构变迁?
面对PB级别数据存储,我们一路走来也踩过很多坑,这里就直接进入主题了,给大家分享一下监控宝系统架构变迁的两个比较重要的点。
一、Redis的扩展
我们面临的第一个的问题是redis的扩展,redis进程无法使用多核,我们当时的redis进程并发1.5W,单 core CPU占用率95%,偶发会达到100%,监控宝的任务调度会出现延迟现象。我们想到的方案如下:
方案1:改程序逻辑,基于任务ID的一致性hash支持redis多实例。 但是研发很忙(好吧,好像从来没有闲过)。此方案只能放弃。
方案2:redis cluster. 当时看到官方的架构图,我就直接将此方案放弃了。我们有大量的写操作,如果每个点都同步写操作,理论上瓶颈无法解决,不太适合我们的使用场景,而且大家的生产环境用这个的好像也不多。
redis cluster 的逻辑图如下:
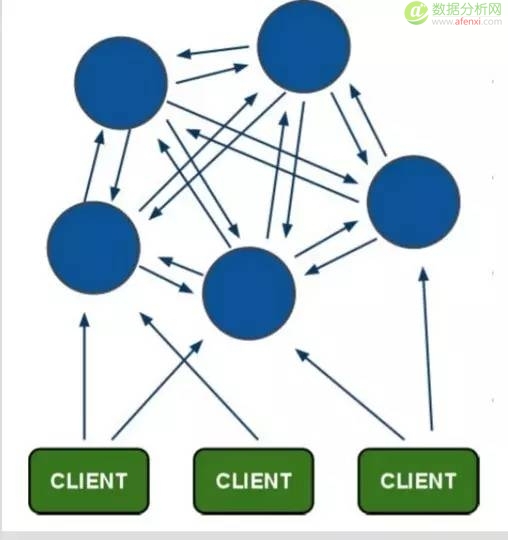
方案3:codis, Twemproxy.
最终我们选择了codis。借此机会感谢一下豌豆荚的刘奇同学,当时遇到了一些问题,请教了刘奇同学,总是能很快的得到解答,非常赞。目前codis 在线上稳定运行一年多,从未出现任何问题。QPS 已经达到15万次每秒。
架构概览
其架构图如下,整个架构每一层都支持扩展,并且无单点。
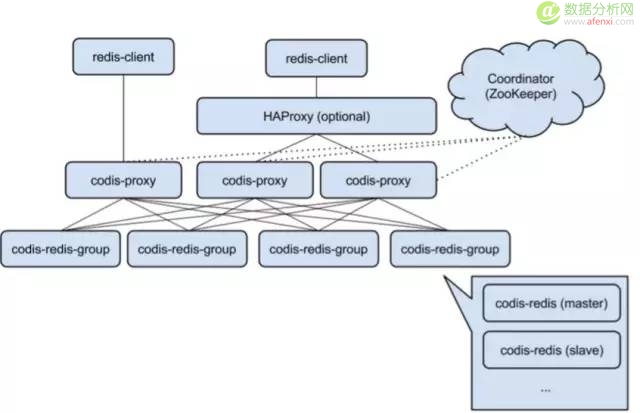
Codis有很多优点,让我们选择它的理由如下:
1、平滑迁移。Codis 提供了迁移工具,比较容易操作。我们生产环境已经验证,从redis迁到codis 对业务影响为0,不过redis有些命令是不支持的,迁移之前还是要仔细读下codis的文档,看是否适合自己的生产环境。
2、扩展容易。Codis将数据默认分了1024个slot, 看到这个当时就很开心,
以后基本不用担心数据量的问题了。理论上是可以扩展到1024个redis实例,扩展的时候,先把新的redis实例加入到集群中,再将部分slot迁移
至新的实例中就可以了,包括后面将要提到的Mycat 2.0 也会采用这种设计。
3、友好的管理页面,扩展的操作直接就可以通过管理页面做了。下面是迁移管理的图:
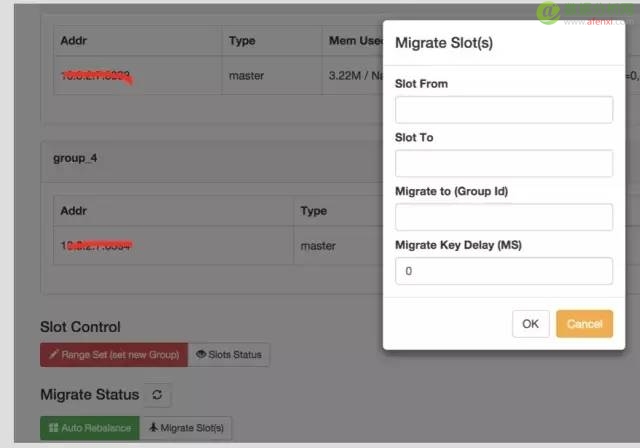
而上面这几点Twemproxy是不具备的。唯一的缺点就是稍稍复杂一些,入门的时候稍需要多花些时间。但相比其优点这些都微不足道了。
二、使用Mysql处理PB级别的数据存储
我们面临的第二个问题是PB级别的数据存储。
现实场景:以我们的网站监控为例简单的介绍下数据的情况。我们在全球分布有200+个监测点,这些监测点按用户设置的频率访问指定的网站页面,监测数据传到我们的数据中心。这个服务目前有30多万用户在使用,平均数据日增量在1T以上。
这部分数据类似于日志数据,使用Mysql来存这些数据并不是什么高大上的做法,如果大家使用过ELK的话,会推荐我们使用elasticsearch来存储这些日志数据。
好吧,的确是这样,我们的新产品:透视宝、压测宝、数据宝是有用到elasticsearch,也用到了hadoop、spark、suro、kafka,druid等大数据相关的框架应用。或者直接使用文件来存储也是可以的。
数据库的分库分表问题
但老系统的问题还是要解决的。使用Mysql做大量数据存储很容易就想到分库分表,提到分库分表自然就会想到Mysql的中间件。
大家在网站可以查到一些常用的分库分表的中间件,包括大家比较熟悉的Atlas、Mycat(cobar)、TDDL、HEISENBERG、OCEANUS、VITESS、ONEPORXY、DRDS等,先不谈这些中间件之间的区别,他们共有一个特性,只能在一个维度上对数据进行拆分或者说只能对数据进行一次拆分。
切分数据库分为垂直切分和水平切分,先介绍一个我们使用到的比较简单的垂直切分场景:
垂直切分
几个数据库在同一个Mysql实例中,但因数据库A 的IO相对较高,希望将其单独拉到另外一台服务器上。又不想让研发改动代码。
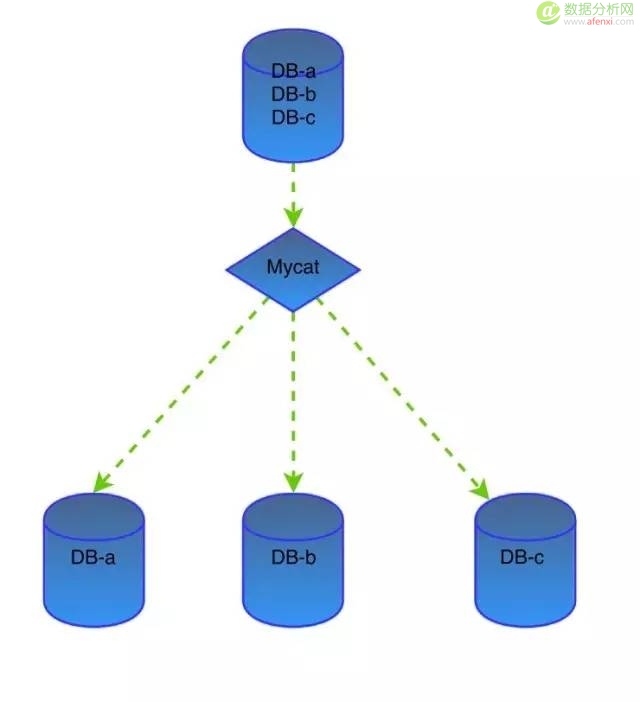
以前一直以为Mycat只能做水平切分,其实也可以垂直切分的,很实用,配置也很简单,因各种原因希望将原来一个Mysql实例中的多个库分布到多个实例中,直接使用Mycat就可以做到,对应用程序来看还是同一个实例,在拆分过程可以通过主从同步实现平滑迁移。
水平切分
接下来介绍水平切分,水平切分是指将某个表按照某个字段按某种规则来分散到多个表之中,每个表中包含一部分数据。
常用的根据主键或非主键的分片规则:
-
枚举法:
比如数据是按照地区省份来保存的,用户通过多级别划分的,本规则适用于这些特定的场景。
-
求模:
如果分片字段为数字,对分片字段进行十进制/百进制求模运算,数据可以均匀落在各分片内。也见过网友分享的对字符串hash取模,支持存在符号字母的字段的分片。
-
范围约定
对分片字段约定一个范围,比如ID 100001~200000为一个分片,ID 200001~300000为一个分片
-
按日期
可以按月,按天,按小时分片
-
一致性hash
一致性hash算法有效解决了分布式数据的扩容问题。这个大家可以查下具体的算法实现。
以上是常用的几种方式,也有一些分片方式是根据上面5种变化得来,比如对日期字段hash再分片的。
单独使用一种分片规则是很难支撑大量数据的存储,哪怕使用一致性hash在生产环境中也是很麻烦的事情,光是数据迁移就是一件让运维头疼的事了,这时候我们需同时采用垂直分片和水平分片,甚至多次水平分片,下面聊一下我们在实际生产中如何使用这些分片规则的。
实例:
以我们API监控为例, 看下应用场景。
现在我们手机里安装的是各种APP,其架构中必然存在大量的API,我们的用户不但要监控单个API请求,还要监控连续请求构成的事务,监控宝API监控的正确性是以断言来判断的。每个监测点都会对用户的API做出请求,请求数据及断言的结果都将被存储到数据中心。
我们借助于cobar, 对数据做了两次分片。分片逻辑图如下:

首先我们是通过cobar 采用枚举法按监测点ID对DB这层进行了数据分片,这样做的话物理上同一个监测点的数据在一起,业务上也是好理解的。
其次,在程序逻辑中按天对表进行了分片。每天都会有脚本将一月之内的表都创建好。
扩展衍生问题
从上图中大家可以看到,这里扩展上是存在问题的!
-
我们一共有200多个监测点。在第一阶段,数据量没有那么大的时候,为了节约成本,我们仅使用了10台机器做存储,一台机器存有多个监测点的数据
-
随着数据量增大,发展到第二阶段,当某台机器硬盘快存满的时候,我需要将一些监测点的数据迁移至新增进集群的机器中,按这个架构,最多我们可以扩展到200+台机器。
-
在生产环境中用户对北上广的监测点是最有兴趣的,所以这些监测点的数据量是最大的。 这样就会发展到第三阶段,部分监测点的数据量大到单台机器的硬盘存不下了。
这时候如何解决问题呢,我们来分析一下数据,单个数据库中是按日期来分表的,而大于3个月的历史数据较少有人查询,用户也可以接受历史数据查询时间稍长一些,于是我们选用了TokuDB来压缩历史数据,基本上1T的数据压缩之后在100G左右。
1:10的压缩例,即使这样,理论上最多也只能存储4P左右的数据(数据放在UCLOUD上,云主机支持的最大硬盘为2T)。
解决方案
我们在网站监控的数据分库中解决了这个问题,逻辑图如下,我们从4个维度对数据进行了分片。

1、按日期为第一维度对数据库分片,必须按日期做第一次分片,并且分片时间点可以在配置文件中自定义。
2、按监测点ID为第二维度对数据库分片
3、按实际分片数量对任务ID动态取模为第三维度对数据库分片。
4、对任务ID 100取模为第四维度对数据表分片。
创建后的数据库类名似于db-201501-monitor01-01、 db-201501-monitor01-02 …… 每个库是有100张表。这样可以的好处:
1、冷热数据自然分离。
2、可以根据日期无限次分片。
3、在同一个时间段里实际分片数可以自定义。
注意:理论上可以无限次分片。每次分片服务器的数量是可控的,并且下次分片的时间也变的可预期。可以在最大程度是节约成本。
4、数据无需迁移
细心的同学会发现这样对数据分片造成一个小问题,我们对任务ID做了两次取模。会造成部分实例中的某些表中数据是空的,不过并不影响应用。
互动问答
Q1:这么多次分片,都是mycat分的吧?请问总共有多少记录量?
并不都通过mycat分片,有些是程序支持的,特别是第一次分片,我们需要能在指定的时间点分片。 总记录量我们没有统计,我们知道目前每秒的写入为2万QPS。
Q2:一致性hash中 rehash对业务影响?
我们的业务中并没有用到一致性hash,主要是评估迁移量的时候,觉得数据量太大,不太适合我们的应用场景。
Q3:为了提高IO并发,每个DB都是用单独的磁盘吗?RAID5?RAID10?
我们使用的是UCLOUD的云盘,他们的IOPS可以支持到 随机写1600QPS,据我了解,他们的底层是通过8块硬盘作raid10.
Q4:codis group中master slave的作用是什么?为什么这么用?
作用是为了保障高可用性,当某个redis实例节点出现故障可以实现master-slave的角色切换,我们当时用到的版本中切换是需要手动触发的。他们也提供了一个脚本来实现。
Q5:所有的数据库全存放在一个物理机房吗?机房出故障的情况怎么应对?
对于跨机房容灾的问题,我们是借助于云平台来做的,目前的知名云平台都有多个机房,并且之间都是光纤打通的。PING值在10ms以内,基本可以当内网使用。另外,我们从年前开始启用了多云布署的方案,多云布署,聊起来有点长了。
Q6:后期codis会实现如果group中一个redis实例挂掉,会不会自动踢出该实例啊
这个问题在问题4中已经回答了。我使用的版本还不会自动切换和踢出集群。但当时刘奇说过要在后面的版本实现,因为我们有自己做调用他们提供的切换脚本了,就没在关注后面的版本。大家关心的话,可以看下codis 的官方文档。
Q7:codis中的master和slave并不是实质上的主从吧,只是切换的一种状态而已,底层redis实例是需要进行主从设置的?
codis本身是通过redis的一个版本二次开发的,本质上这个主从关系就是通过redis的主从功能实现的。
Q8:master slave切换能说的稍微详细吗?高可用?怎么做的?
这个问题还是接上图吧。
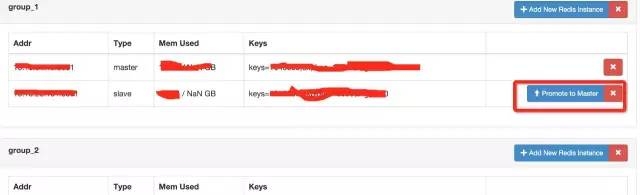
这个是操作界面上的可以手动操作。另外还有一个脚本可以实现。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330