“世界第一行销之神杰亚伯拉罕的《选对池塘钓大鱼》一书中,把不同的客户群描述成鱼,而不同的客户群的集合就是不同的池塘,企业应该根据自己的目标客户,去思考怎样借助从别人已经建立起来的池塘中快速找到目标客户。”

大数据分析挑战无限Gartner 调查显示:55%的组织正在实施大数据方案来提升客户体验,49%的组织使用大数据方案来改进流程效率;42%的企业正在寻找新产品、建立新的业务模型。然而,大数据分析却是企业现今面临的一大挑战,因为他们不仅需要管理不断增长的原生数据;而且,在物联网高度发展的今天,由于巨大数据量来源不同,有的来自传感器、机械设备,还有的来自社交媒体等等,多种多样的数据来源又给企业的大数据分析竖起一座屏障。
解决上述难题的条件,是企业必须要选择正确的大数据分析平台,即要选对池塘,只有这样才能钓出少量数据中的“大鱼”。
戴尔Cloudera数据分析应有尽有谈到大数据分析,毫无疑问,Hadoop是最受企业欢迎的数据分析平台。但Hadoop集群的安装、配置及运行,却有许多地方需要慎重考量。如软件方面,如何选择合适的Hadoop分布式与扩展软件和监测与管理软件?在硬件方面,如何分布Hadoop服务的物理节点?如何选择合适的服务器?在功能方面,Hadoop平台的性能与扩展性表现如何?等等。
针对Hadoop所存在的这一系列问题,戴尔联合Cloudera推出了Dell Cloudera大数据解决方案。
Dell Cloudera提供了包括硬件、软件、资源和服务在内所有Hadoop所需的东西。使用该解决方案,可帮助用户轻松解决与Hadoop部署、管理等相关的各种问题,快速从海量数据中的提取价值。
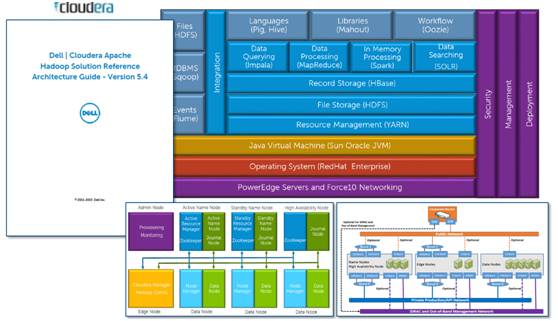
戴尔Cloudera软硬件兼施戴尔Cloudera是由Cloudera服务以及Cloudera管理套件组成的一个参考架构,可以让开源Hadoop在数据驱动的企业在生产环境中高效运行。
硬件结果处理更快速硬件方面,戴尔的PowerEdge C2100机架服务器和PowerConnect 6248以太网交换机都已经在大数据部署中成功应用,而戴尔Cloudera解决方案正是基于这个组件。Dell PowerEdge C2100服务器可让用户同时拥有内存和磁盘容量,它专门设计用于最大化数据中心中空间、电力和成本效益的。其中内存及存储的密度对数据中心至关重要,PowerEdge C2100可容纳18个DDR3内存插槽,最高支持144GB的内存容量,企业可以更快的速度获得数据分析结果。同时PowerEdge C2100机架服务器为MapReduce、Web analytics和数据库提供了内存以及磁盘。另外,Dell PowerConnect 6248提供了完整的48千兆以太网及3层交换机,支持更高效的机架密度以及核心交换的高级功能。

软件Hadoop管理更透明软件方面,在Hadoop集群内部以及Hadoop集群之间交付高能见度。戴尔Cloudera通过结合专家支持以及交付透明管理控制的软件,允许Hadoop维护人员以高效的方式进行集群资源的精确部署及管理。同时,戴尔Cloudera允许将与现代IT管理相似的业务指标以可支付的成本在生产环境中运行Hadoop集群,达到资源利用最优化。其内置的可预测功能能够预见Hadoop基础设施的改变,从而确保了操作的可靠性。
此外,戴尔还为Cloudera大数据解决方案提供服务及支持。保证企业的解决方案由专业的软硬件团队支持,根据企业特定的需求进行量身定做。
戴尔Cloudera内存式大数据解决方案的惊人表现戴尔中国和SAP中国为某石油客户在SAP HANA数据库+Compellent存储全闪存技术的BI分析系统的性能:
•星形模型设计,包含2个事实表数据,明细数据模型、指标汇总模型•6个维度表数据,编号维表、ID维表、组织维度表、人员姓名、三级单位名称、分公司名称•主表包含180亿条记录,数据分析量超过60TB容量!
原有系统,2小时以上计算出结果,且易发生中断……采用戴尔Compellent存储全闪存技术在SAP HANA的新商业智能架构,单个查询缩短到20秒以内,400并发查询运行缩短到10分钟以内。
戴尔自身就是这一内存式“大数据”方案的使用者,用于企业内部的“精准营销” 智慧决策和分析系统。在2015年,戴尔更获得了"SAP HANA Innovation Award-2015"第一名的殊荣。
结语“鱼是游动的,机会也是在变化的,我们必须不断变化位置来寻找大鱼,并且在其饥饿的时候投下鱼饵,将其钓上来。”——《选对池塘钓大鱼》
在这个数据颠覆一切的时代,企业的数据不断变化,企业也要以不断发展的眼光挑选出适合自己的数据分析平台。选对平台,才能钓出数据池塘之下的大鱼——大价值。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330