SPSS中如何对数据文件结构进行重组分析_数据分析师考试
不同的分析方法需要不同的数据文件结构,当现有的数据文件结构与将要进行分析所要求的数据结构不一致时,我们需要进行数据文件结构的重组,一般来说数据文件的结构分析为横向和纵向两种结构。
横向结构
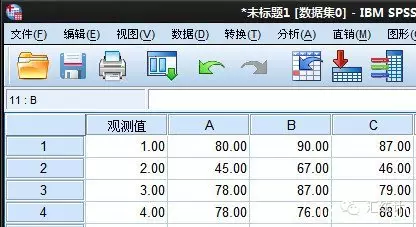
横向结构的数据将一个变量组中的不同分类分别作为不同的变量,例如将A,B,C作用下的数值分别作为一个变量进行保存,每一个组是一个观测量,如图:
纵向结构
纵向结构的数据将一个变量组中的不同分类分别作为不同的观测量,例如将A,B,C组作用下的数值作为一个观测量,如图:
数据重组方式的选择
在菜单栏中一次选择“数据”|“重组”命令,打开如下所示“重组数据向导”对话框。
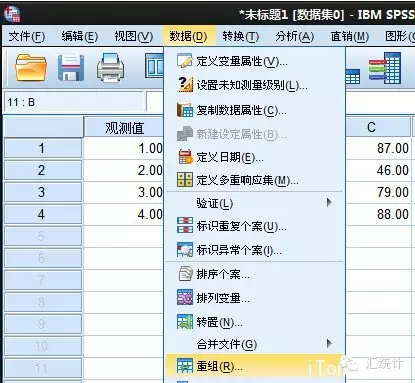

该对话框提供了三种数据重组方式,分别是“将选定变量组重组为个案”、“将选定个案重组为变量”和“转置所有数据”,用户可以根据现有数据的组合方式和将要进行的分析来选择相应的数据重组方式。
由变量组到观测量组的重组
变量组到观测量组的重组将会使数据由横向格式转换为纵向格式,首先打开横向格式保存的数据文件。
1)选择变量组个数
在“重组数据向导”对话框中选择“选定变量组重组为个案”单选按钮,单击“下一步”按钮,弹出下图对话框“重组数据向导-第二步(共7步)”对话框。
在此对话框中选择要重组的变量组个数。这里只有一个变量组(A,B,C),选择“一个”单选按钮。
2)选择要重组的变量
单击“下一步”按钮,弹出如下的“重组数据向导-第三步”对话框。

(1)“个案组标识”选项组 该选项组用于设置对观测记录的便是变量,在下拉框中有3个选项:
使用个案号,选择此项系统会出现“名称”输入框和“标签”列表,用户可以设置重组后序号变量的变量名和变量标签。
使用选定变量,选择此项系统会出现一个右箭头按钮和“变量”列表,选择标识变量,单击右箭头按钮将其选入“变量”列表即可。
无,则表示不适用标识变量。
(2)“要转置的变量”选项组 该选项组用于设置需要进行转置的变量组。“目标变量”下拉框用于指定要进行重组的变量组。指定完成后,选择相应变量,单击右箭头按钮将其选入“目标变量”列表,组成转置的变量组。
(3)“固定变量”列表 如果用户不希望一个变量参加重组,只需要选择该变量,单击右箭头按钮将其选入“固定变量”列表即可。
本例中将A,B,C变量选入“要转置的变量”列表,在“目标变量”后输入框输入“D”。

3)选择索引变量的个数
单击“下一步”按钮,弹出如下“重组数据向导--第四步”对话框

该对话框用于设置重组后生成的索引变量的个数,一个或者是多个,也可以选择无,标识把索引信息保存在某个要转置重组的变量中,不生成索引变量。本例选择创建“一个”索引变量。
4)设置索引变量的参数
继续单击“下一步”,弹出如下菜单“重组数据向导--第5步”对话框。

索引值是什么类型选项组:该选项组用于设置索引值的类型,用户可以选择有序数组或变量作为索引值得类型。
编辑索引变量的名称和标签栏:在该栏中设置索引变量的变量名和变量标签。
本例,设置索引变量的名称为“品类”,索引值为变量名,即A,B,C
5)其他参数的设置
单击“下一步”,弹出“重组数据向导---第6步”对话框。该对话框中有三个选项组设置。
(1)“处理未选定的变量”选项组 该选项组用于设置对用户未选定变量的处理方式,如选择“从数据文件中去掉变量”,系统会敬爱那个这一部分变量删除;如选择“作为固定变量保存和处理”,系统会将这一部分变量作为固定变量处理。
(2)“所有已转置变量中的缺失值或空白值”选项组 该选项组用于设置对要转置变量中的缺失值和空白值的处理方式,“在新文件中创建个案”,标识系统将为这些变量单独生成观测记录;选择“废弃数据”,则这一部分观测值将被删除。
(3)“个案计数变量”选项组 该选项组用于设置是否生成计数变量,勾选“计算有当前数据中的个案创建的新个案的数量”复选框,表示生成计数变量,同时将激活“名称”和“标签”输入框,用户可以在其中输入计数变量的变量名和变量标签,本例中,该步保持默认设置即可。
6)完成数据重组
单击“下一步”,弹出“重组数据向导---完成”对话框。
这里可选择是否立即进行数据重组,如选择“将本向导生成的已经黏贴到语句窗口”单选按钮,系统会将相应的命令语句粘贴值语句窗口。

设置完成后,单击“完成”按钮即可进行数据重组操作。重组后的数据文件如下,横向格式数据文件转换成了纵向格式的数据文件。

CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330