移动游戏数据分析框架-收入相关指标详解_数据分析师
==========在做进一步讲解之前,依旧先对活跃用户进行定义===================
AU(Active Users)活跃用户:统计周期内,登录过游戏的用户数;根据统计周期不同又划分为DAU(日活跃用户),WAU(周活跃用户),MAU(月活跃用户);
备注:入门篇中所定义的“用户”均以“账号”进行衡量;账号:游戏账号库中的唯一标识,在单款游戏中全局唯一;
==========================================================
仍然从应收的公式进行推导 Revenue = AU * PUR * ARPPU;在活跃用户规模固定的前提下,PUR 和 ARPPU 是衡量游戏盈利能力最基础的2个指标;
国内做游戏数据分析的时候 ARPPU 和 ARPU 经常被混在一起,这里为了严谨,单独把这2个指标拿出来对比一下;
ARPU(Average Revenue Per User) 平均每用户收入
定义:统计周期内,活跃用户对游戏产生的平均收入;
公式: ARPU = Revenue / AU
ARPPU (Average Revenue Per Paying User) 平均每付费用户收入
定义:统计周期内,付费用户对游戏产生的平均收入;
公式:ARPPU = Revenue / APA
PUR(Pay User Rate)付费比率
定义:统计周期内,付费账号数占活跃账号数的比例;一般以自然月或自然周为单位进行统计;
公式:PUR = APA / AU;
APA(Active Payment Account)活跃付费账号数
定义:统计周期内,成功付费的账号数(排重统计);
公式:APA = AU * PUR;
拓展应用:
从公式的推导可以看出,实际上 ARPU = ARPPU * PUR;目前国内游戏数据做数据分析时所说的“ARPU”实际上是ARPPU,即平均每付费用户收入;
之所以将 ARPU 再拆解为 PUR 和 ARPPU,主要是因为 ARPU是对产品盈利能力的综合评价,为了更好的我们做决策,将付费指标拆解为 PUR(广度,更多的人付费) 和 ARPPU(深度,付更多的钱) 两个维度;
基于上诉原则,在做充值相关分析的时候,还可以对PUR 和 ARPPU 做进一步拆解,比如新老用户的 PUR 和 ARPPU,对 APA 的付费强度(统计周期内充值金额)进行分段统计,观察APA的结构,如大R占比,贡献率、小额充值的比重等;
在移动游戏数据分析领域,特别是渠道商在判断产品质量的时候,大家还会经常听到一个指标 LTV
LTV(Lift Time Value)生命周期价值
定义:平均一个账号在其生命周期内(第一次登录游戏到最后一次登录游戏),为该游戏创造的收入总计;
公式:LTV_N = 统计周期内,一批新增用户在其首次登入后N天内产生的累计充值 / NU(New Users);
应用场景:手机游戏数据分析中的发行指标,用于衡量渠道导入用户的回本周期,LTV_N>CPA(登录)
从LTV的定义上可以看出,CP可以通过不同渠道导入用户的LTV_N 与 导入成本(CPL)进行比较,用于计算不同媒体投放的回本率(这个在市场推广篇已经提到);另外,渠道商也可以通过这个指标和联运资源的成本对比,迅速判断一款产品是否值得投入联运资源;
由于LTV是基于新增用户进行计算的,因此受大R影响比较严重。
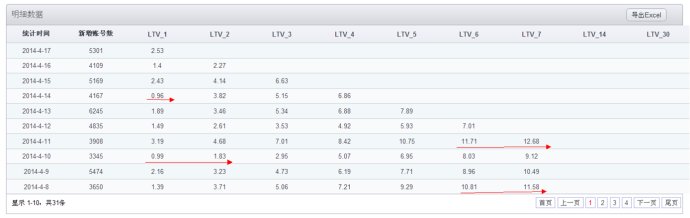
因此,在观察产品LTV数据的时候,通常情况下会选取一段时间的数据进行观察;在汇总计算时,如下图所示,计算LTV_N 时只抽取时间跨度足够的样本;
如,统计周期选择 4-10至4-19,LTV_4 仅通过 4-10 至 4-16的数据进行计算,因为 4-17至4-19 三天的新增账号还没有第4天的数据;
另外,由于受每日新增用户的质量影响较大,有可能出现LTV_N+1 小于 LTV_N的情况,因此要观察 LTV_N时,统计周期至少选择 N +14 天以上,保证每个指标都有14天以上的样本进行计算;
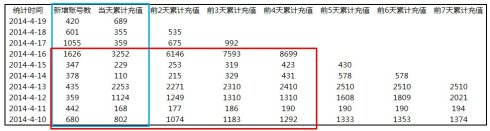
本文提及的收入指标主要是用于描述产品宏观数据,关于结合游戏内的其他数据做分析(包括IB分析、消费分析、首充分析等)以帮助我们制定相应的运营活动和版本计划,这部分会在 进阶篇 的案例中详细说明.(文章来源:CDA数据分析师)
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330