



2019-07-03
阅读量:
992
编码器和解码器要注意的问题
编码器: 它使用深度神经网络层并将输入字转换为相应的隐藏向量。每个向量代表当前单词和单词的上下文。
解码器: 它类似于编码器。它将编码器生成的隐藏矢量,其自身的隐藏状态和当前字作为输入,以产生下一个隐藏矢量,最后预测下一个字。
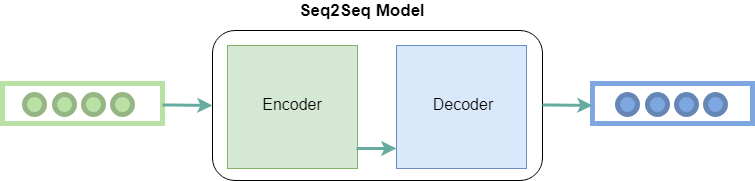
除了这两个,许多优化导致seq2seq的其他组件:
- 注意:解码器的输入是一个向量,它必须存储有关上下文的所有信息。这成为大序列的问题。因此,应用注意机制,其允许解码器选择性地查看输入序列。
- 波束搜索:选择最高概率词作为解码器的输出。但由于贪心算法的基本问题,这并不总能产生最好的结果。因此,应用波束搜索,其建议在每个步骤可能的翻译。这样就完成了一个顶级k结果的树。
- 跳跃:在seq2seq模型中可以使用可变长度序列,因为0的填充对输入和输出都进行了填充。但是,如果我们设置的最大长度为100且句子长度仅为3个字,则会造成巨大的空间浪费。所以我们使用bucketing的概念。我们制作不同大小的桶,如(4,8)(8,15)等等,其中4是我们定义的最大输入长度,8是定义的最大输出长度。
 50.0000
50.0000
 1
1
 2
2

 关注作者
关注作者
 收藏
收藏

评论(0)
 发表评论
发表评论
暂无数据







推荐帖子

天下无欺诈
2025-08-06
0条评论
CDA助教老师
2025-05-24
0条评论
CDA助教老师
2025-05-14
0条评论