“大数据之父”达文波特:
成功的数据科学家不一定要有研究生学位
2006年6月,乔纳森•高德曼(Jonathan Goldman)进入商务社交网站LinkedIn工作。作为斯坦福大学物理学博士,他醉心于无处不在的链接和丰富的用户资料。虽然这两者通常只能形成混乱的数据和浅显的分析,但当他着手挖掘人际联系时,却从中发现了“新大陆”。

他开始构建理论、检验预设,并研究出了模型。通过这些模型,他可以预测出某账号所归属的人际网络。高德曼觉得,在探索基础之上形成的新功能也许能为用户提供价值。
幸运的是,LinkedIn的联合创始人兼时任CEO雷德•霍夫曼(现执行总裁),在贝宝(PayPal)的工作经验让他对分析学的威力深信不疑,因此,他给了高德曼高度的自主权。
他给予高德曼一个不同于传统产品发布套路的新方式—在网站黄金页面以广告的形式挂出小型加载模块。这一测试最终大放异彩,成为了我们现在熟知的“你可能认识的人”。
传统的信息管理和数据分析主要用于支撑内部决策,而大数据在这方面有所不同。当然,在多数情况下,大数据也会有此用途,特别是在大企业内。不过, 数据科学家通常致力于面向客户的产品和服务,而不是创建为高管制定内部决策提供建议的报表或报告。
数据科学家这一概念直到2008年,才由D.J. 帕蒂尔和杰夫•哈默巴赫尔创造,这个职位因为被达文波特喻为“21世纪最性感的职业”而为更多人所熟知。那么,成为一名数据科学家,需要怎样的潜质和能力?
数据科学家的特征
我们可以用这样一张图表,来展示数据科学家必备的技能结构:
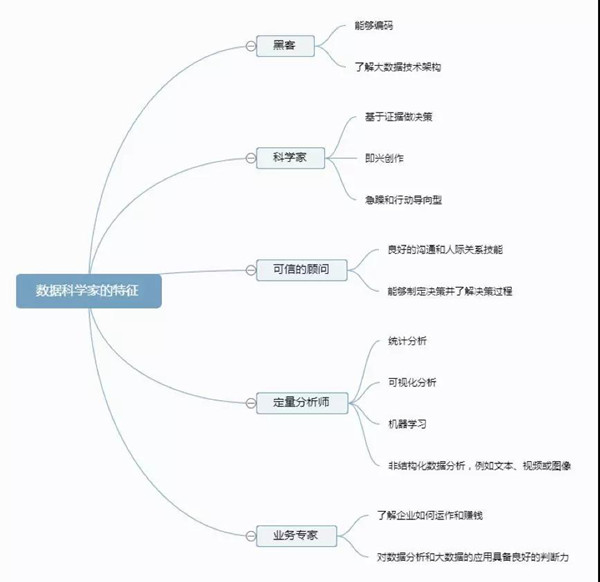
1、要想成为数据科学家,先去做黑客吧!
由于大数据技术是一种新兴技术,而且很难将其提取出来用于分析,所以,要想成为一位成功的数据科学家,就必须具备一些黑客的特征。
首先,你必须具备编码或编程能力。“你会编写代码吗”,这是一位首席科学家在招聘时向数据科学家提出的第一个问题。如果你具备任何编程语言方面的经验,那将大有裨益,尤其是脚本语言,如 Python、 Hive 和Pig,或者有时会生成的语言,如 Java。这些脚本语言相对容易编写,还能将大型数据处理问题分布于分布式 MapReduce 框架中。
数据科学中的黑客还需要熟悉常用的大数据技术,最重要的是 Hadoop/MapReduce,包括如何实施和扩展它们,以及是否需要在所在地点或云计算中提供这些技术。这些技术都是一些新技术,还在不断变化,所以数据科学家必须具备开放性思维,而且要特别开放,以学习新工具和新方法。
最后,对黑客技术做一个总结,很多大企业不愿意雇用黑客是有原因的。在本文中,黑客技术通常被定义为一种创新的快速计算,但这一术语还有一层“不太合法”的意味,即倾向于避开计算行为的正常规则。就当前大数据技术低下的情形而言,后一种意义的黑客技术可能是必需的。然而,值得注意的是,黑客特征在数据科学家特征中并不占主导地位,你可能会为此后悔。铁杆黑客带来的麻烦远比他们带来的益处要多得多。而且,他们也未必有兴趣为大型官僚组织效力。
2、成功的数据科学家,不一定要有研究生学位
在数据科学家的特征中,科学家这一特征不一定意味着必须是实战科学家。然而, 2012 年,我对 30 名数据科学家进行了采访,结果发现,57% 取得了科学和技术领域的博士学位, 90% 至少在科学或技术领域获得过一个高级学位,最常见的是实验物理学博士, 其中还包括生物学、生态学或社会科学等高级学位,而且这些领域通常涉及大量的计算机工作。
数据科学是否需要这些领域详细的相关知识呢? 绝对不需要。对实验物理学博士而言,重要的不是学位或相关的具体知识,而是完成数据科学任务所需的能力和态度,其能力包括开展实验、设计实验装置,以及利用数据来收集、分析和描述结果的能力。科学家分析的数据不可能是真正的数据科学家,就连大学也很少接触到真正的大数据,但它很可能是一种非结构化的数据。
进行大数据分析的科学家可能会具备的特征有:基于证据做决策、即兴创作、急躁以及自己动手的宽慰感。在大数据工作的早期阶段,这些技能很重要。在这一阶段中,数据科学家必须执行一些开创性工作,而在后期,这些工作可能会通过软件轻松地完成。科学家也可能是快速学习者,能迅速地吸收和掌握新技术。
应当指出的是,许多成功的数据科学家根本没有研究生学位,他们的大多技能都是自学而来的,因为以前的大学并不提供这方面的课程。例如,领先的数据科学家杰夫 · 哈默巴赫(Jeff Hammerbacher)在 Facebook 工作时与当时就职于领英的帕蒂尔(DJ Patil)创造了数据科学家这一术语,而那时他只有本科学位。大数据文化是一种任人唯才的文化,而不是一种强调具备某种数据科学学位的文化。
3、你得是一位可信的顾问
正如传统的定量分析师一样,数据科学家需要具备良好的人际沟通技能。然而,正如传统的数据分析师一样,他们不可能具备这些技能。因为如果你将大部分精力放在计算机和统计数据上,就不会对人际关系产生太大的兴趣。
不过,良好的人际沟通技能肯定是必要的。数据科学家要为高管制定内部决策提供建议;在以数据为产品的企业里,数据科学家还要为负责产品和营销的管理者就数据产品和服务的机会提出建议。最早一批数据科学家中的帕蒂尔参与创造了这一术语,他常喜欢说,数据科学家必须“站在桥上”,近距离地向船长提出建议。如果数据科学家和决策者之间存在中介的话,决策者可能无法了解关键决策涉及的所有重要数据和问题。
有证据表明,这些技巧很重要。高德纳公司(Gartner)的研究发现,“70%~80% 的企业智能商业项目的失败”是因为“IT 部门和业务部门之间缺乏沟通,未能提出正确的问题,或未能考虑到企业的真正需求”。智能商业项目通常涉及的都是一些小数据,而不是大数据。然而,某些项目之所以失败是因为自身存在问题。毫无疑问,缺乏沟通的小数据和大数据项目会引发大问题。

4、先成为定量分析师
在大数据被获取并被“驯服”之后,即从非结构化数据转换为结构化数据之后,必须用传统的方式对其进行分析。因此,数据科学家还需要承担起定量分析师的工作,了解他们身边的各种数学和统计技能,并能够轻松地向非技术人员做解释。我和一些作者已经合著了很多关于这些统计技能的书籍,所以在这里就不再详述这些技能了。
然而,小型非结构化数据的分析和大数据的分析之间存在一些差异。其一是,对于较大的群体来说,小样本统计推断出的结果可能不太重要。随着大数据的出现,企业往往会对整体数据进行分析,因为它们具备这种技术。如果你不是从一个样本来推断整个群体的结果,也就不用担心统计数据之类的概念,换句话说,小样本统计就是所观察到的结果代表群体的概率,因为它们就是一个群体。尽管如此,但我相信,在许多情况中,我们仍将继续使用样本统计。例如,向所有美国或其他国家公民征询他们对政治或社会问题的看法是不可行的,所以我们还是会利用样本调查来解决这类问题。即使你利用大量的网络数据来分析这一问题,但仍然只能代表特定时间内某些用户的意见。
两者之间的另一个不同之处是,大家普遍偏爱大数据的可视化分析。至于原因,我想没有人能完全解释清楚。大数据分析结果往往以可视化的形式表现出来,现在,可视化分析有很多优势:易于高管理解,容易引起注意。不利的一面是,它们一般不适宜于表达复杂的多元关系和统计模型。换句话来说,大多数可视化数据是为了进行描述性分析,而不是预测性或指令性分析。然而,它们可以同时显示大量的数据,如图 4-1 所示,这幅图呈现的是银行账户关闭因素的可视化分析。我发现,与许多其他复杂的大数据可视化分析一样,这一可视化分析也很难解释。我有时会想,很多大数据的可视化分析仅仅是因为可以进行分析而被创建的,而并不是为了清晰地呈现一个问题。
为什么可视化分析常见于大数据中呢?有几种可能的解释。
这表明,由于捕捉结构化数据所付出的努力太多,所以很少有时间和精力来开展复杂的多元统计分析,只能建立一个简单的频率统计,然后基于频率统计进行绘制。这种现象常见于数据科学家群体中,但没有人知道这种方法的重要性和普遍性。
另一种解释是,大数据和更吸引人的可视化分析几乎同时出现。最后一种解释是,大数据工作是一种探索性和反复性的工作,因此需要可视化分析来探索数据,并向管理者和决策者传达初步调查结果。
我们可能永远不会知道哪个解释更为重要,但事实是,数据科学家需要以可视化的方式来显示数据和分析结果。
5、做既能精通又能跨界的业务专家
数据科学家对业务的运作要有深入的了解,或者至少应该了解其中的部分环节。例如,企业如何赚钱?竞争对手是谁?企业如何在行业中成功推出产品和服务?能够利用大数据和分析来解决的关键问题是什么?这些都是一个有效率的数据科学家应该回答的问题。
掌握与业务相关的知识可以使数据科学家做出假设并迅速对其进行测试,为关键的功能和业务问题提供解决方案;否则,他将难以为业务增加附加值。正是对业务问题的分析使这些关于数据或传统数据分析的知识得以发挥作用,因此,相关业务领域的兴趣和经验很重要。当然, 数据科学家有时也会在各个行业之间来回转换,但没有人会精通所有领域。然而,重要的是,他们需要对所从事的新业务抱有强烈的好奇心和兴趣。 显而易见,数据科学家通常都是极其聪明的人,如果他们对某个新业务感兴趣,很快就会掌握相关的知识。如果你面试的是另一个行业的数据科学家,请确保他对其所从事的行业感兴趣,而且具备解决问题的能力。
当然,这个技能结构对有志成为数据科学家的人才来说,是一种参考。任何人都很难同时在这五个方向都出类拔萃。通用电气公司全球研究中心的分析学技术的负责人格拉伯是这样说的:“在通用电气公司,我们发现具备 2~3 个领域的专业技能的数据科学家是最有成效的”。你要做的,是在一支团队中找到自己的位置,发挥自己的创造性,并且不断学习。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330