LLM进入拖拽时代!只靠Prompt几秒定制大模型,效率飙升12000倍
【新智元导读】最近,来自NUS、UT Austin等机构的研究人员创新性地提出了一种「拖拽式大语言模型」(DnD),它可以基于提示词快速生成模型参数,无需微调就能适应任务。不仅效率最高提升12000倍,而且具备出色的零样本泛化能力。
现在的大模型基本都具备零样本泛化能力,但要在真实场景中做特定的适配,还是得花好几个小时来对模型进行微调。
即便是像LoRA这样的参数高效方法,也只能缓解而不能消除每个任务所需的微调成本。
刚刚,包括尤洋教授在内的来自新加坡国立大学、得克萨斯大学奥斯汀分校等机构的研究人员,提出了一种全新的「拖拽式大语言模型」——Drag-and-Drop LLMs!

- 论文地址:
https://arxiv.org/abs/2506.16406
DnD是一种基于提示词的参数生成器,能够对LLM进行无需训练的自适应微调。
通过一个轻量级文本编码器与一个级联超卷积解码器的组合,DnD能在数秒内,仅根据无标签的任务提示词,生成针对该任务的LoRA权重矩阵。
显然,对于那些需要快速实现模型专业化的场景,DnD可以提供一种相较于传统微调方法更强大、灵活且高效的替代方案。

总结来说,DnD的核心优势如下:
- 极致效率:其计算开销比传统的全量微调低12,000倍。
- 卓越性能:在零样本学习的常识推理、数学、编码及多模态基准测试中,其性能比最强大的、需要训练的LoRA模型还要高出30%。
- 强大泛化:仅需无标签的提示词,即可在不同领域间展现出强大的泛化能力。
DnD实现方法
通过观察,研究人员发现,LoRA适配器无非是其训练数据的一个函数:梯度下降会将基础权重「拖拽」至一个特定任务的最优状态。
如果能够直接学习从提示到权重的映射,那么就可以完全绕过梯度下降过程。
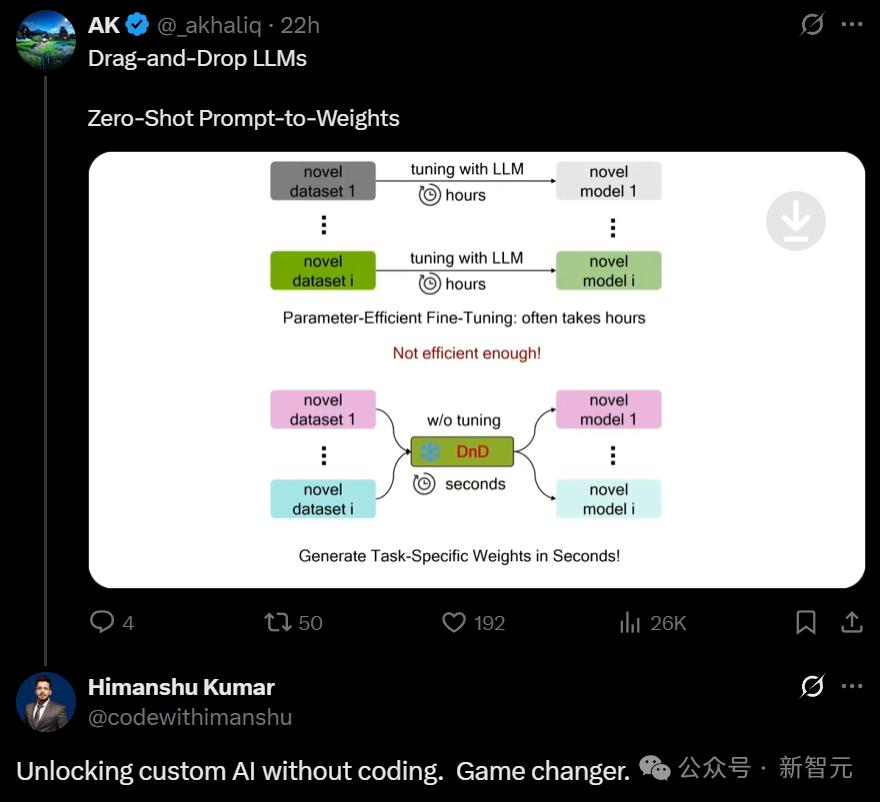
DnD通过两个核心步骤获得「拖拽」能力:准备训练数据(左上)与训练参数生成器(右上)。
在准备数据时,将模型参数(权重)与特定数据集的条件(提示词)进行显式配对。
在训练时,DnD模型将条件作为输入来生成参数,并使用原始的LoRA参数作为监督信号进行学习。
基于这些洞见,团队提出了「拖拽式大语言模型」,它无需微调即可生成任务专属的权重。
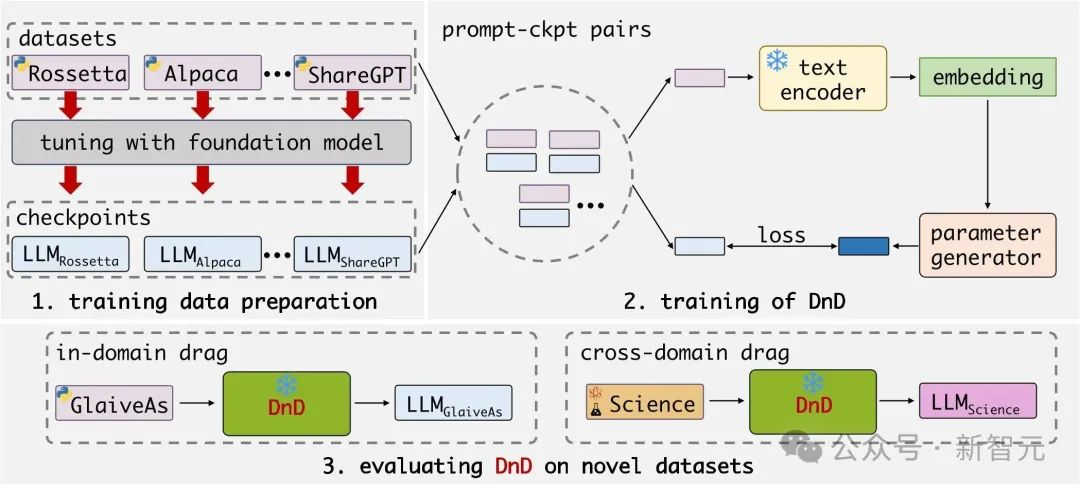
团队首先在多个不同数据集上分别训练并保存相应的LoRA适配器。
为了赋予模型「拖拽」的能力,团队将这些数据集的提示词与收集到的LoRA权重进行随机配对,构成DnD模型的训练数据——即「提示词-参数」对。
参数生成器是一个由级联卷积块构成的解码器。
参数生成器的模块细节如下:每个超卷积块包含三个超卷积模块,用于在不同维度上提取并融合特征信息。

训练时,团队采用一个现成的文本编码器提取提示词的嵌入向量,并将其输入生成器。
生成器会预测出模型权重,团队利用其与真实LoRA权重之间的均方误差(MSE)损失来对其进行优化。
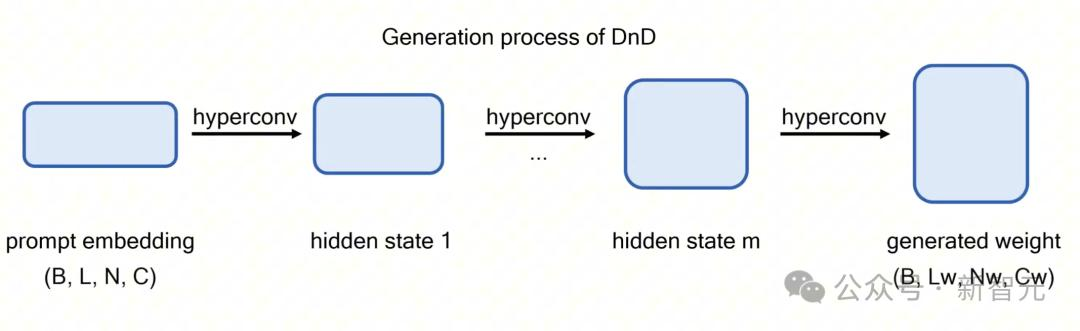
在推理阶段,团队只需将来自全新数据集(训练中未见过)的提示词输入DnD,仅需一次前向传播,即可获得为该任务量身定制的参数。
效果评估

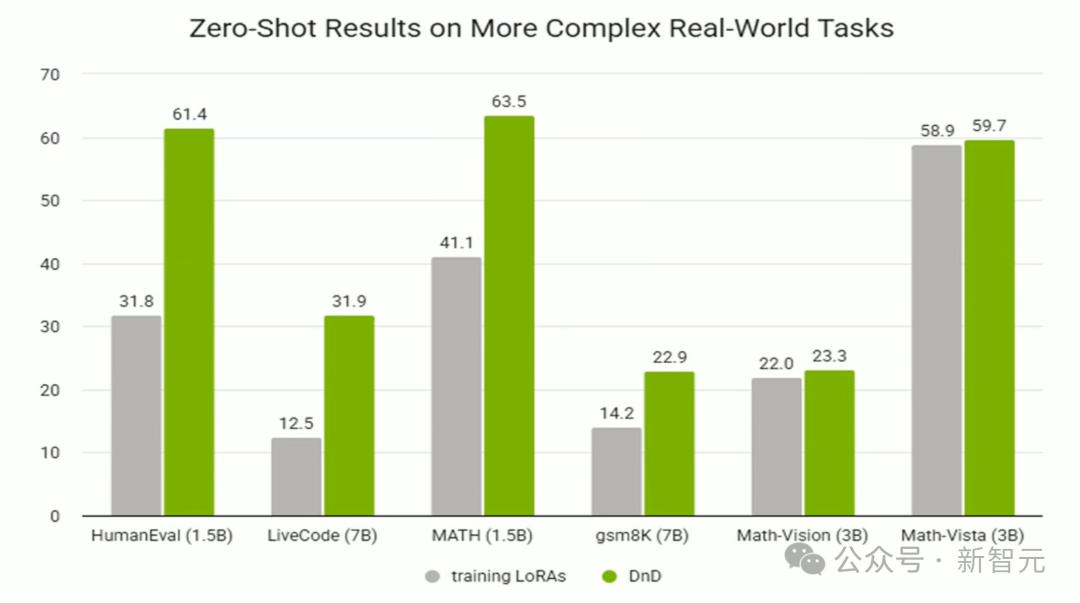
零样本学习效果
在新的(测试)数据集上的泛化能力。
在所有未曾见过的数据集上,DnD在准确率上都显著超越了那些用于训练的LoRA模型。

DnD能为数学、代码和多模态问答等更复杂的任务生成参数。
在这些任务上依然展现出强大的零样本学习能力。
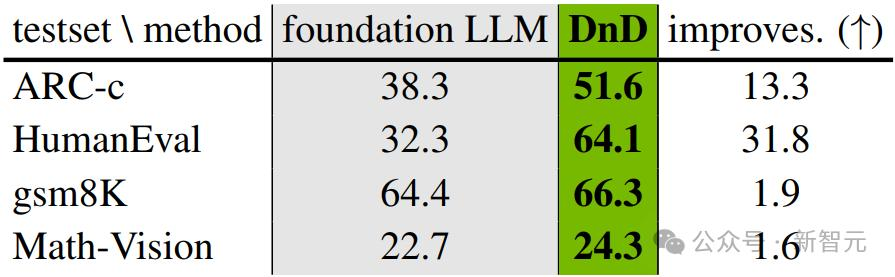
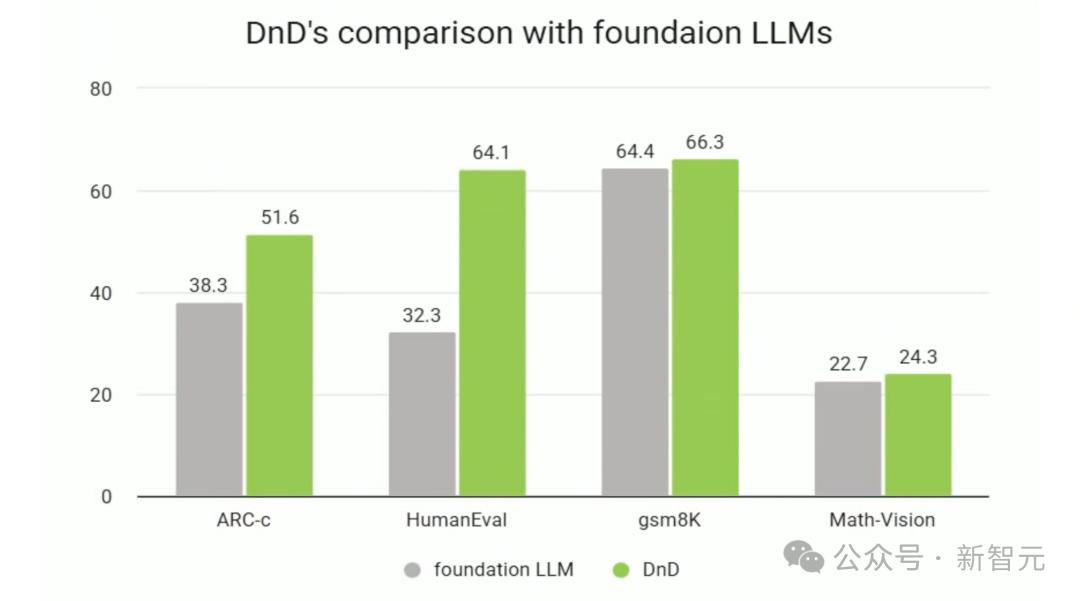
DnD在多种任务上超越了基座LLM,展现出显著的「拖拽」增强效果。

DnD能够很好地扩展至更大的7B基座模型,并在更复杂的LiveCodeBench基准测试中保持强劲性能。
通过利用已微调的LoRA作为训练数据,DnD成功地在输入提示词与模型参数之间建立了联系。
团队向DnD输入其训练阶段从未见过的数据集提示词,让它为这些新任务直接生成参数,以此来检验其零样本学习能力。
DnD在权重空间中生成的参数与原始参数分布接近,并且在性能上表现良好。
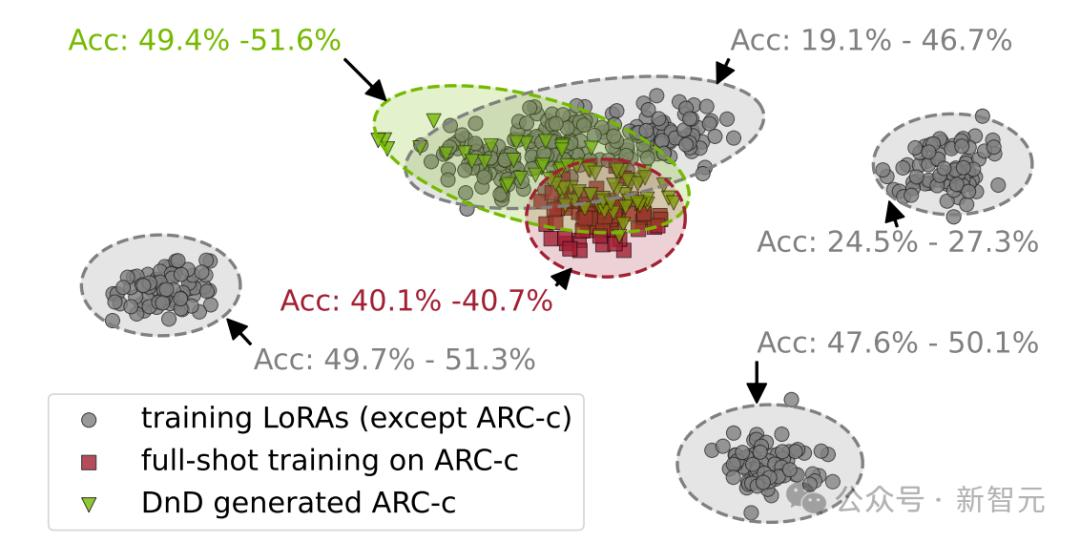
实验结果表明,在零样本测试集上,团队的方法相较于训练所用的LoRA模型的平均性能,取得了惊人的提升,并且能够很好地泛化到多种真实世界任务和不同尺寸的LLM。
对比其他微调方法
为了进一步展示DnD的强大能力,团队将其与全量样本微调(full-shot tuning)、少样本学习(few-shot)以及上下文学习(in-context learning)进行了对比。
令人惊讶的是,DnD的性能超越了LoRA全量微调的效果,同时速度快了2500倍。
虽然经过更多轮次的迭代,全量微调的性能会超过DnD,但其代价是高达12000倍的推理延迟。
此外,在样本数少于256个时,DnD的性能稳定地优于少样本学习和上下文学习。
尤其值得注意的是,少样本学习和上下文学习都需要依赖带标签的答案,而DnD仅仅需要无标签的提示词。
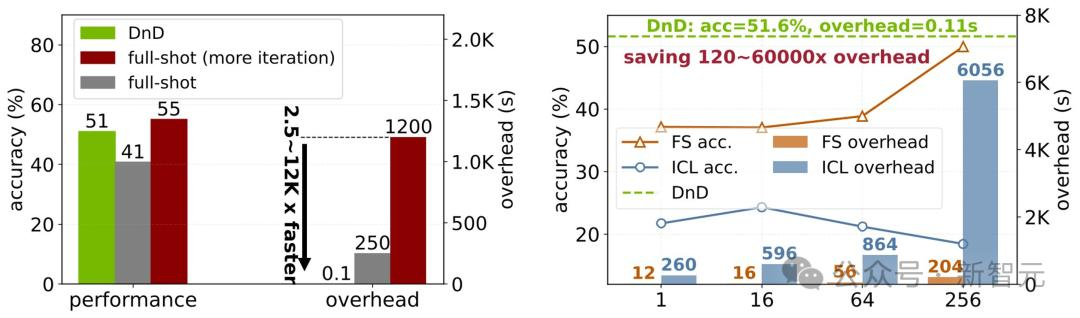
DnD能够达到与全量样本相当甚至更优的性能,同时速度提高了2500-12000倍
- 参考资料:
https://jerryliang24.github.io/DnD
By 新智元 On 2025年6月24日 In 综合

 免费加入阅读:
免费加入阅读:









 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330