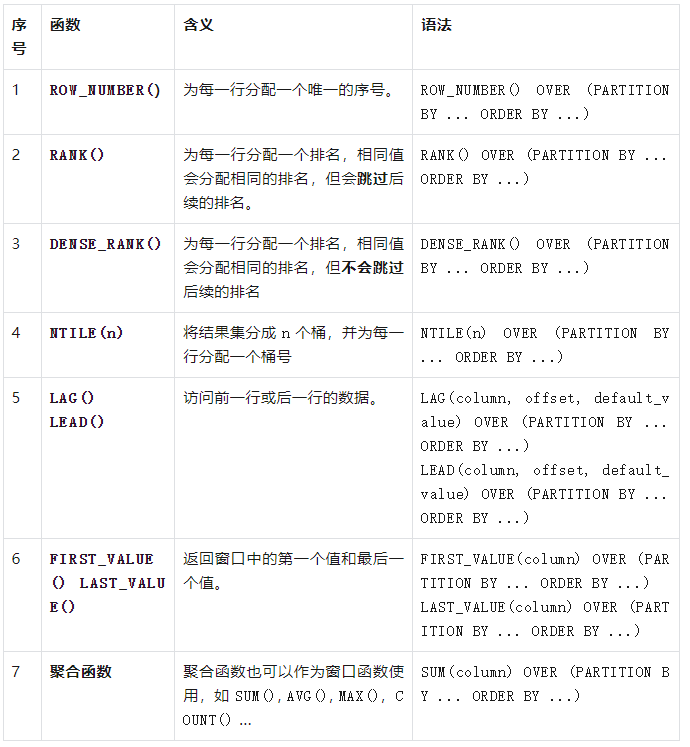
WITH employees AS ( SELECT 1 AS id, '张三' AS name, '销售部' AS department, 5000 AS salary UNION ALL SELECT 2, '李四', '市场部', 6000 UNION ALL SELECT 3, '王五', '销售部', 5500 UNION ALL SELECT 4, '赵六', '技术部', 7000 UNION ALL SELECT 5, '孙七', '市场部', 6500 UNION ALL SELECT 6, '周八', '技术部', 7500 UNION ALL SELECT 7, '吴九', '销售部', 4500 UNION ALL SELECT 8, '郑十', '市场部', 5000 UNION ALL SELECT 9, '钱十一', '技术部', 8000 UNION ALL SELECT 10, '王十二', '销售部', 4000 )
2.2 使用 SELECT 语句从单个表中检索数据
示例
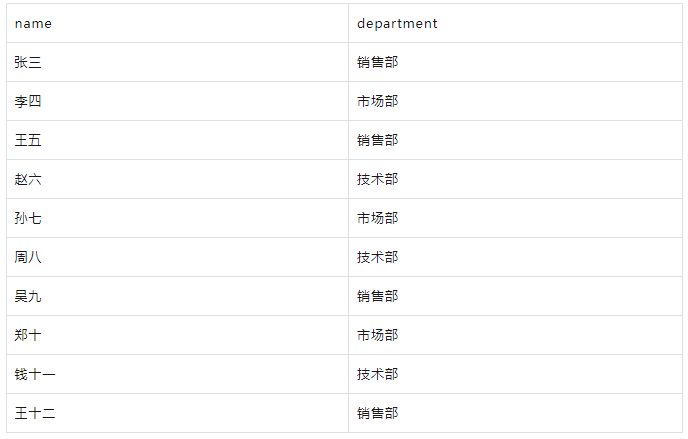
要获取所有员工的姓名和部门:
WITH employees AS ( SELECT 1 AS id, '张三' AS name, '销售部' AS department, 5000 AS salary UNION ALL SELECT 2, '李四', '市场部', 6000 UNION ALL SELECT 3, '王五', '销售部', 5500 UNION ALL SELECT 4, '赵六', '技术部', 7000 UNION ALL SELECT 5, '孙七', '市场部', 6500 UNION ALL SELECT 6, '周八', '技术部', 7500 UNION ALL SELECT 7, '吴九', '销售部', 4500 UNION ALL SELECT 8, '郑十', '市场部', 5000 UNION ALL SELECT 9, '钱十一', '技术部', 8000 UNION ALL SELECT 10, '王十二', '销售部', 4000 ) SELECT name, department FROM employees;
结果:
2.3 使用 WHERE 子句过滤数据
示例
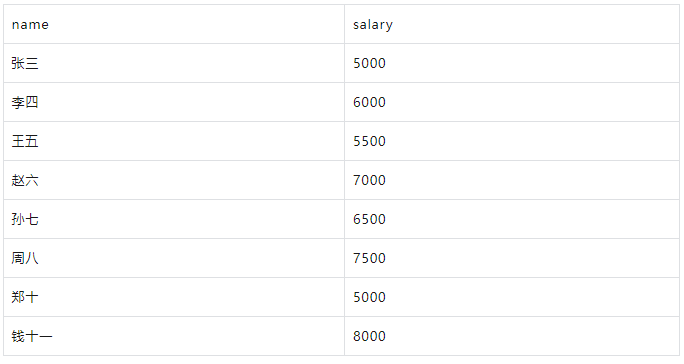
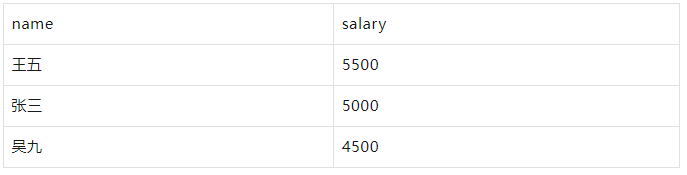
要获取工资大于5000的员工信息:
WITH employees AS ( SELECT 1 AS id, '张三' AS name, '销售部' AS department, 5000 AS salary UNION ALL SELECT 2, '李四', '市场部', 6000 UNION ALL SELECT 3, '王五', '销售部', 5500 UNION ALL SELECT 4, '赵六', '技术部', 7000 UNION ALL SELECT 5, '孙七', '市场部', 6500 UNION ALL SELECT 6, '周八', '技术部', 7500 UNION ALL SELECT 7, '吴九', '销售部', 4500 UNION ALL SELECT 8, '郑十', '市场部', 5000 UNION ALL SELECT 9, '钱十一', '技术部', 8000 UNION ALL SELECT 10, '王十二', '销售部', 4000 ) SELECT name, salary FROM employees WHERE salary > 5000;
结果
2.4 使用 ORDER BY 排序结果集
示例
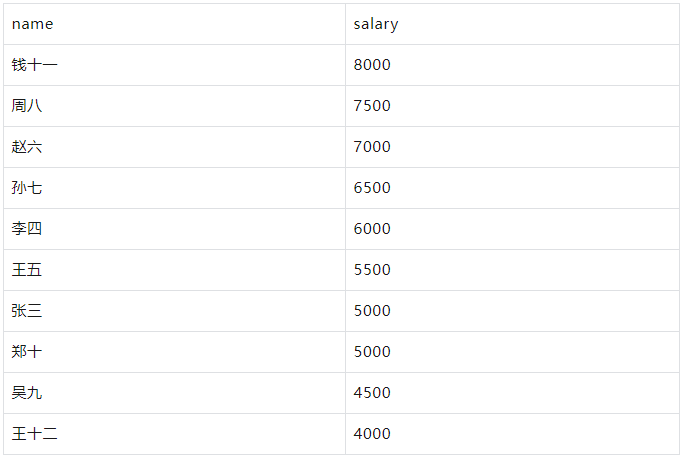
要按工资从高到低排序员工信息:
WITH employees AS ( SELECT 1 AS id, '张三' AS name, '销售部' AS department, 5000 AS salary UNION ALL SELECT 2, '李四', '市场部', 6000 UNION ALL SELECT 3, '王五', '销售部', 5500 UNION ALL SELECT 4, '赵六', '技术部', 7000 UNION ALL SELECT 5, '孙七', '市场部', 6500 UNION ALL SELECT 6, '周八', '技术部', 7500 UNION ALL SELECT 7, '吴九', '销售部', 4500 UNION ALL SELECT 8, '郑十', '市场部', 5000 UNION ALL SELECT 9, '钱十一', '技术部', 8000 UNION ALL SELECT 10, '王十二', '销售部', 4000 ) SELECT name, salary FROM employees ORDER BY salary DESC;
结果
2.5 使用 LIMIT 限制返回行数
示例
要获取前5名最高工资的员工信息,并按工资降序排序:
WITH employees AS ( SELECT 1 AS id, '张三' AS name, '销售部' AS department, 5000 AS salary UNION ALL SELECT 2, '李四', '市场部', 6000 UNION ALL SELECT 3, '王五', '销售部', 5500 UNION ALL SELECT 4, '赵六', '技术部', 7000 UNION ALL SELECT 5, '孙七', '市场部', 6500 UNION ALL SELECT 6, '周八', '技术部', 7500 UNION ALL SELECT 7, '吴九', '销售部', 4500 UNION ALL SELECT 8, '郑十', '市场部', 5000 UNION ALL SELECT 9, '钱十一', '技术部', 8000 UNION ALL SELECT 10, '王十二', '销售部', 4000 ) SELECT name, salary FROM employees ORDER BY salary DESC LIMIT 5;
结果
2.6 组合使用多个子句
示例
要获取属于 "销售部" 的前3名最高工资的员工信息,并按工资降序排序:
WITH employees AS ( SELECT 1 AS id, '张三' AS name, '销售部' AS department, 5000 AS salary UNION ALL SELECT 2, '李四', '市场部', 6000 UNION ALL SELECT 3, '王五', '销售部', 5500 UNION ALL SELECT 4, '赵六', '技术部', 7000 UNION ALL SELECT 5, '孙七', '市场部', 6500 UNION ALL SELECT 6, '周八', '技术部', 7500 UNION ALL SELECT 7, '吴九', '销售部', 4500 UNION ALL SELECT 8, '郑十', '市场部', 5000 UNION ALL SELECT 9, '钱十一', '技术部', 8000 UNION ALL SELECT 10, '王十二', '销售部', 4000 ) SELECT name, salary FROM employees WHERE department = '销售部' ORDER BY salary DESC LIMIT 3;
结果
2.7 总结
通过上述示例,你可以看到如何使用 WITH 子句创建一个临时表,并在此基础上进行各种数据检索操作。这些示例涵盖了 SELECT、WHERE、ORDER BY 和 LIMIT 的基本用法,帮助你更好地理解和验证查询结果。
使用SELECT语句从单个表中检索数据
使用WHERE子句过滤数据
使用ORDER BY排序结果集
使用LIMIT限制返回行数
3. 聚合与分组
使用COUNT(), SUM(), AVG(), MAX(), MIN()等聚合函数
使用GROUP BY对数据进行分组
3.1 使用 WITH 子句创建临时表
首先,我们创建一个包含10条员工数据的临时表 employees。
WITH employees AS ( SELECT 1 AS id, '张三' AS name, '销售部' AS department, 5000 AS salary UNION ALL SELECT 2, '李四', '市场部', 6000 UNION ALL SELECT 3, '王五', '销售部', 5500 UNION ALL SELECT 4, '赵六', '技术部', 7000 UNION ALL SELECT 5, '孙七', '市场部', 6500 UNION ALL SELECT 6, '周八', '技术部', 7500 UNION ALL SELECT 7, '吴九', '销售部', 4500 UNION ALL SELECT 8, '郑十', '市场部', 5000 UNION ALL SELECT 9, '钱十一', '技术部', 8000 UNION ALL SELECT 10, '王十二', '销售部', 4000 )
3.2 聚合函数
聚合函数用于对一组值执行计算并返回单个值。常用的聚合函数包括:
COUNT():计算行数。
SUM():计算总和。
AVG():计算平均值。
MAX():返回最大值。
MIN():返回最小值。
示例- count
计算总员工数:
WITH employees AS ( SELECT 1 AS id, '张三' AS name, '销售部' AS department, 5000 AS salary UNION ALL SELECT 2, '李四', '市场部', 6000 UNION ALL SELECT 3, '王五', '销售部', 5500 UNION ALL SELECT 4, '赵六', '技术部', 7000 UNION ALL SELECT 5, '孙七', '市场部', 6500 UNION ALL SELECT 6, '周八', '技术部', 7500 UNION ALL SELECT 7, '吴九', '销售部', 4500 UNION ALL SELECT 8, '郑十', '市场部', 5000 UNION ALL SELECT 9, '钱十一', '技术部', 8000 UNION ALL SELECT 10, '王十二', '销售部', 4000 ) SELECT COUNT(*) AS total_employees FROM employees;
结果:
total_employees 10
示例-sum
计算所有员工的总薪水:
WITH employees AS ( SELECT 1 AS id, '张三' AS name, '销售部' AS department, 5000 AS salary UNION ALL SELECT 2, '李四', '市场部', 6000 UNION ALL SELECT 3, '王五', '销售部', 5500 UNION ALL SELECT 4, '赵六', '技术部', 7000 UNION ALL SELECT 5, '孙七', '市场部', 6500 UNION ALL SELECT 6, '周八', '技术部', 7500 UNION ALL SELECT 7, '吴九', '销售部', 4500 UNION ALL SELECT 8, '郑十', '市场部', 5000 UNION ALL SELECT 9, '钱十一', '技术部', 8000 UNION ALL SELECT 10, '王十二', '销售部', 4000 ) SELECT SUM(salary) AS total_salary FROM employees;
结果:
total_salary 59000
示例-avg
计算所有员工的平均薪水:
WITH employees AS ( SELECT 1 AS id, '张三' AS name, '销售部' AS department, 5000 AS salary UNION ALL SELECT 2, '李四', '市场部', 6000 UNION ALL SELECT 3, '王五', '销售部', 5500 UNION ALL SELECT 4, '赵六', '技术部', 7000 UNION ALL SELECT 5, '孙七', '市场部', 6500 UNION ALL SELECT 6, '周八', '技术部', 7500 UNION ALL SELECT 7, '吴九', '销售部', 4500 UNION ALL SELECT 8, '郑十', '市场部', 5000 UNION ALL SELECT 9, '钱十一', '技术部', 8000 UNION ALL SELECT 10, '王十二', '销售部', 4000 ) SELECT AVG(salary) AS average_salary FROM employees;
结果:
average_salary 5900.00
示例-max
返回最高薪水:
WITH employees AS ( SELECT 1 AS id, '张三' AS name, '销售部' AS department, 5000 AS salary UNION ALL SELECT 2, '李四', '市场部', 6000 UNION ALL SELECT 3, '王五', '销售部', 5500 UNION ALL SELECT 4, '赵六', '技术部', 7000 UNION ALL SELECT 5, '孙七', '市场部', 6500 UNION ALL SELECT 6, '周八', '技术部', 7500 UNION ALL SELECT 7, '吴九', '销售部', 4500 UNION ALL SELECT 8, '郑十', '市场部', 5000 UNION ALL SELECT 9, '钱十一', '技术部', 8000 UNION ALL SELECT 10, '王十二', '销售部', 4000 ) SELECT MAX(salary) AS max_salary FROM employees;
结果:
max_salary 8000
示例-min
返回最低薪水:
WITH employees AS ( SELECT 1 AS id, '张三' AS name, '销售部' AS department, 5000 AS salary UNION ALL SELECT 2, '李四', '市场部', 6000 UNION ALL SELECT 3, '王五', '销售部', 5500 UNION ALL SELECT 4, '赵六', '技术部', 7000 UNION ALL SELECT 5, '孙七', '市场部', 6500 UNION ALL SELECT 6, '周八', '技术部', 7500 UNION ALL SELECT 7, '吴九', '销售部', 4500 UNION ALL SELECT 8, '郑十', '市场部', 5000 UNION ALL SELECT 9, '钱十一', '技术部', 8000 UNION ALL SELECT 10, '王十二', '销售部', 4000 ) SELECT MIN(salary) AS min_salary FROM employees;
结果:
min_salary 4000
3.3 使用 GROUP BY 进行分组
GROUP BY 子句用于将结果集按一个或多个列进行分组,通常与聚合函数一起使用。
示例-count
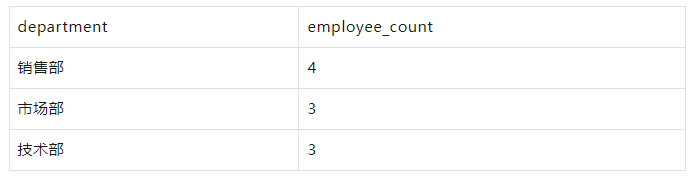
按部门分组,计算每个部门的员工数:
WITH employees AS ( SELECT 1 AS id, '张三' AS name, '销售部' AS department, 5000 AS salary UNION ALL SELECT 2, '李四', '市场部', 6000 UNION ALL SELECT 3, '王五', '销售部', 5500 UNION ALL SELECT 4, '赵六', '技术部', 7000 UNION ALL SELECT 5, '孙七', '市场部', 6500 UNION ALL SELECT 6, '周八', '技术部', 7500 UNION ALL SELECT 7, '吴九', '销售部', 4500 UNION ALL SELECT 8, '郑十', '市场部', 5000 UNION ALL SELECT 9, '钱十一', '技术部', 8000 UNION ALL SELECT 10, '王十二', '销售部', 4000 ) SELECT department, COUNT(*) AS employee_count FROM employees GROUP BY department;
结果:
示例-sum
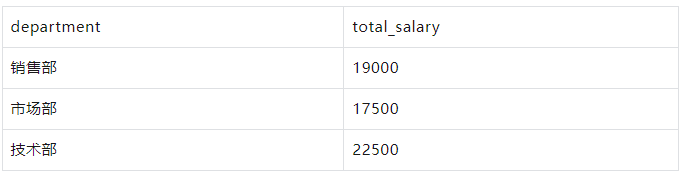
按部门分组,计算每个部门的总薪水:
WITH employees AS ( SELECT 1 AS id, '张三' AS name, '销售部' AS department, 5000 AS salary UNION ALL SELECT 2, '李四', '市场部', 6000 UNION ALL SELECT 3, '王五', '销售部', 5500 UNION ALL SELECT 4, '赵六', '技术部', 7000 UNION ALL SELECT 5, '孙七', '市场部', 6500 UNION ALL SELECT 6, '周八', '技术部', 7500 UNION ALL SELECT 7, '吴九', '销售部', 4500 UNION ALL SELECT 8, '郑十', '市场部', 5000 UNION ALL SELECT 9, '钱十一', '技术部', 8000 UNION ALL SELECT 10, '王十二', '销售部', 4000 ) SELECT department, SUM(salary) AS total_salary FROM employees GROUP BY department;
结果:
示例-avg
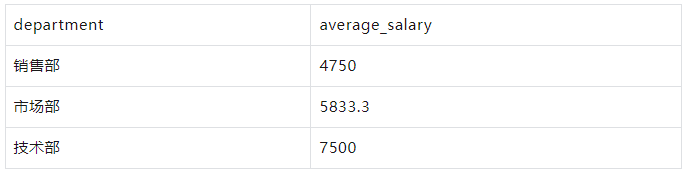
按部门分组,计算每个部门的平均薪水:
WITH employees AS ( SELECT 1 AS id, '张三' AS name, '销售部' AS department, 5000 AS salary UNION ALL SELECT 2, '李四', '市场部', 6000 UNION ALL SELECT 3, '王五', '销售部', 5500 UNION ALL SELECT 4, '赵六', '技术部', 7000 UNION ALL SELECT 5, '孙七', '市场部', 6500 UNION ALL SELECT 6, '周八', '技术部', 7500 UNION ALL SELECT 7, '吴九', '销售部', 4500 UNION ALL SELECT 8, '郑十', '市场部', 5000 UNION ALL SELECT 9, '钱十一', '技术部', 8000 UNION ALL SELECT 10, '王十二', '销售部', 4000 ) SELECT department, AVG(salary) AS average_salary FROM employees GROUP BY department;
结果:
示例-max-min
按部门分组,返回每个部门的最高和最低薪水:
WITH employees AS ( SELECT 1 AS id, '张三' AS name, '销售部' AS department, 5000 AS salary UNION ALL SELECT 2, '李四', '市场部', 6000 UNION ALL SELECT 3, '王五', '销售部', 5500 UNION ALL SELECT 4, '赵六', '技术部', 7000 UNION ALL SELECT 5, '孙七', '市场部', 6500 UNION ALL SELECT 6, '周八', '技术部', 7500 UNION ALL SELECT 7, '吴九', '销售部', 4500 UNION ALL SELECT 8, '郑十', '市场部', 5000 UNION ALL SELECT 9, '钱十一', '技术部', 8000 UNION ALL SELECT 10, '王十二', '销售部', 4000 ) SELECT department, MAX(salary) AS max_salary, MIN(salary) AS min_salary FROM employees GROUP BY department;
结果:
3.4 总结
通过上述示例,你可以看到如何使用聚合函数和 GROUP BY 子句来对数据进行分组和计算。这些示例涵盖了 COUNT()、SUM()、AVG()、MAX() 和 MIN() 的基本用法,并结合 GROUP BY 进行分组操作。
WITH employees AS ( SELECT 1 AS id, '张三' AS name, 1 AS department_id, 5000 AS salary UNION ALL SELECT 2, '李四', 2, 6000 UNION ALL SELECT 3, '王五', 1, 5500 UNION ALL SELECT 4, '赵六', 3, 7000 UNION ALL SELECT 5, '孙七', 2, 6500 UNION ALL SELECT 6, '周八', 3, 7500 UNION ALL SELECT 7, '吴九', 1, 4500 UNION ALL SELECT 8, '郑十', 2, 5000 UNION ALL SELECT 9, '钱十一', 3, 8000 UNION ALL SELECT 10, '王十二', 1, 4000 ), departments AS ( SELECT 1 AS id, '销售部' AS department_name UNION ALL SELECT 2, '市场部' UNION ALL SELECT 3, '技术部' )
4.2 内连接(INNER JOIN)
内连接返回两个表中满足连接条件的所有行。
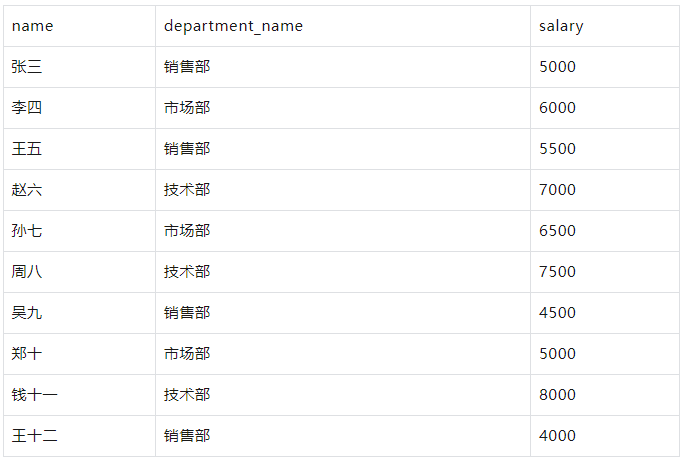
示例
要获取每个员工及其所属部门的名称:
WITH employees AS ( SELECT 1 AS id, '张三' AS name, 1 AS department_id, 5000 AS salary UNION ALL SELECT 2, '李四', 2, 6000 UNION ALL SELECT 3, '王五', 1, 5500 UNION ALL SELECT 4, '赵六', 3, 7000 UNION ALL SELECT 5, '孙七', 2, 6500 UNION ALL SELECT 6, '周八', 3, 7500 UNION ALL SELECT 7, '吴九', 1, 4500 UNION ALL SELECT 8, '郑十', 2, 5000 UNION ALL SELECT 9, '钱十一', 3, 8000 UNION ALL SELECT 10, '王十二', 1, 4000 ), departments AS ( SELECT 1 AS id, '销售部' AS department_name UNION ALL SELECT 2, '市场部' UNION ALL SELECT 3, '技术部' ) SELECT e.name, d.department_name, e.salary FROM employees e INNER JOIN departments d ON e.department_id = d.id;
结果
4.3 左连接(LEFT JOIN)
左连接返回左表中的所有行,以及右表中满足连接条件的行。如果右表中没有匹配的行,则结果为 NULL。
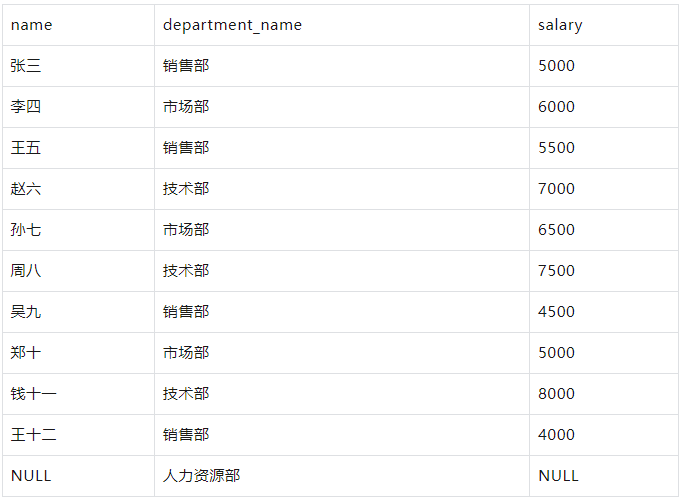
示例
要获取所有员工及其所属部门的名称,即使某些员工没有部门:
WITH employees AS ( SELECT 1 AS id, '张三' AS name, 1 AS department_id, 5000 AS salary UNION ALL SELECT 2, '李四', 2, 6000 UNION ALL SELECT 3, '王五', 1, 5500 UNION ALL SELECT 4, '赵六', 3, 7000 UNION ALL SELECT 5, '孙七', 2, 6500 UNION ALL SELECT 6, '周八', 3, 7500 UNION ALL SELECT 7, '吴九', 1, 4500 UNION ALL SELECT 8, '郑十', 2, 5000 UNION ALL SELECT 9, '钱十一', 3, 8000 UNION ALL SELECT 10, '王十二', 1, 4000 UNION ALL SELECT 11, '无部门员工', NULL, 4000 -- 添加一个没有部门的员工 ), departments AS ( SELECT 1 AS id, '销售部' AS department_name UNION ALL SELECT 2, '市场部' UNION ALL SELECT 3, '技术部' ) SELECT e.name, d.department_name, e.salary FROM employees e LEFT JOIN departments d ON e.department_id = d.id;
结果
4.4 右连接(RIGHT JOIN)
右连接返回右表中的所有行,以及左表中满足连接条件的行。如果左表中没有匹配的行,则结果为 NULL。
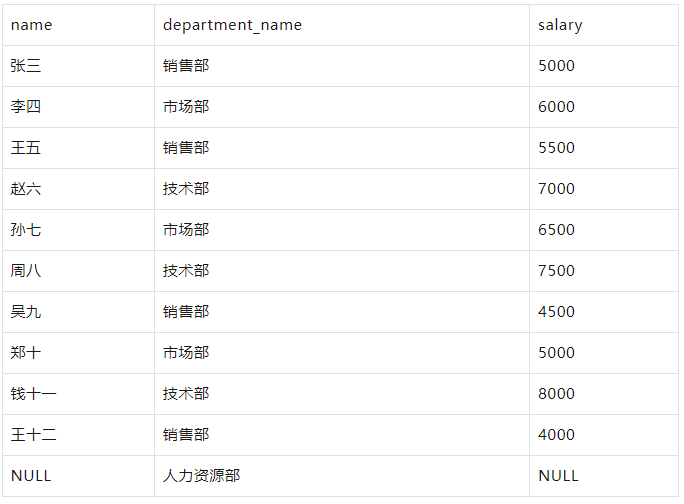
示例
要获取所有部门及其所属员工的名称,即使某些部门没有员工:
WITH employees AS ( SELECT 1 AS id, '张三' AS name, 1 AS department_id, 5000 AS salary UNION ALL SELECT 2, '李四', 2, 6000 UNION ALL SELECT 3, '王五', 1, 5500 UNION ALL SELECT 4, '赵六', 3, 7000 UNION ALL SELECT 5, '孙七', 2, 6500 UNION ALL SELECT 6, '周八', 3, 7500 UNION ALL SELECT 7, '吴九', 1, 4500 UNION ALL SELECT 8, '郑十', 2, 5000 UNION ALL SELECT 9, '钱十一', 3, 8000 UNION ALL SELECT 10, '王十二', 1, 4000 ), departments AS ( SELECT 1 AS id, '销售部' AS department_name UNION ALL SELECT 2, '市场部' UNION ALL SELECT 3, '技术部' UNION ALL SELECT 4, '人力资源部' -- 添加一个没有员工的部门 ) SELECT e.name, d.department_name, e.salary FROM employees e RIGHT JOIN departments d ON e.department_id = d.id;
结果
4.5 全外连接(FULL OUTER JOIN)
全外连接返回两个表中的所有行,如果某个表中没有匹配的行,则结果为 NULL。需要注意的是,并非所有数据库系统都支持 FULL OUTER JOIN,例如 MySQL 不支持,但可以通过 UNION 实现类似效果。
WITH employees AS ( SELECT 1 AS id, '张三' AS name, 1 AS department_id, 5000 AS salary UNION ALL SELECT 2, '李四', 2, 6000 UNION ALL SELECT 3, '王五', 1, 5500 UNION ALL SELECT 4, '赵六', 3, 7000 UNION ALL SELECT 5, '孙七', 2, 6500 UNION ALL SELECT 6, '周八', 3, 7500 UNION ALL SELECT 7, '吴九', 1, 4500 UNION ALL SELECT 8, '郑十', 2, 5000 UNION ALL SELECT 9, '钱十一', 3, 8000 UNION ALL SELECT 10, '王十二', 1, 4000 ), departments AS ( SELECT 1 AS id, '销售部' AS department_name UNION ALL SELECT 2, '市场部' UNION ALL SELECT 3, '技术部' UNION ALL SELECT 4, '人力资源部' -- 添加一个没有员工的部门 ) SELECT e.name, d.department_name, e.salary FROM employees e FULL OUTER JOIN departments d ON e.department_id = d.id;
结果
4.6 总结
通过上述示例,你可以看到如何使用内连接、左连接、右连接和全外连接来操作多个表。这些示例涵盖了 INNER JOIN、LEFT JOIN、RIGHT JOIN 和 FULL OUTER JOIN 的基本用法,并结合 WITH 子句创建临时表进行验证。
5. 高级特性
我们将详细讲解SQL中的高级特性,包括公用表表达式(CTE)、子查询和窗口函数。我们将使用 WITH 子句创建临时表 employees 和 departments,然后进行各种高级查询。
5.1 使用 WITH 子句创建临时表
首先,我们创建两个临时表 employees 和 departments。
WITH employees AS ( SELECT 1 AS id, '张三' AS name, 1 AS department_id, 5000 AS salary UNION ALL SELECT 2, '李四', 2, 6000 UNION ALL SELECT 3, '王五', 1, 5500 UNION ALL SELECT 4, '赵六', 3, 7000 UNION ALL SELECT 5, '孙七', 2, 6500 UNION ALL SELECT 6, '周八', 3, 7500 UNION ALL SELECT 7, '吴九', 1, 4500 UNION ALL SELECT 8, '郑十', 2, 5000 UNION ALL SELECT 9, '钱十一', 3, 8000 UNION ALL SELECT 10, '王十二', 1, 4000 ), departments AS ( SELECT 1 AS id, '销售部' AS department_name UNION ALL SELECT 2, '市场部' UNION ALL SELECT 3, '技术部' )
5.2 公用表表达式(CTE)
公用表表达式(CTE)是一个临时结果集,可以在查询中多次引用。CTE 使用 WITH 子句定义。
示例
要计算每个部门的平均薪水,并使用 CTE 来简化查询:
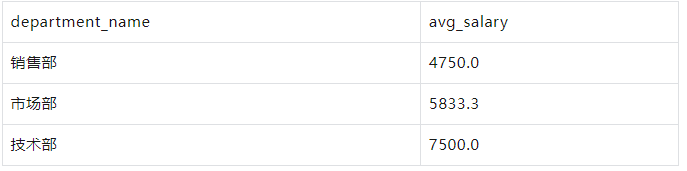
WITH employees AS ( SELECT 1 AS id, '张三' AS name, 1 AS department_id, 5000 AS salary UNION ALL SELECT 2, '李四', 2, 6000 UNION ALL SELECT 3, '王五', 1, 5500 UNION ALL SELECT 4, '赵六', 3, 7000 UNION ALL SELECT 5, '孙七', 2, 6500 UNION ALL SELECT 6, '周八', 3, 7500 UNION ALL SELECT 7, '吴九', 1, 4500 UNION ALL SELECT 8, '郑十', 2, 5000 UNION ALL SELECT 9, '钱十一', 3, 8000 UNION ALL SELECT 10, '王十二', 1, 4000 ), departments AS ( SELECT 1 AS id, '销售部' AS department_name UNION ALL SELECT 2, '市场部' UNION ALL SELECT 3, '技术部' ), department_avg_salary AS (--每个部门平均薪水 SELECT department_id, AVG(salary) AS avg_salary FROM employees GROUP BY department_id ) SELECT d.department_name, das.avg_salary FROM departments d JOIN department_avg_salary das ON d.id = das.department_id;
结果
5.3 子查询
子查询是嵌套在另一个查询中的查询。子查询可以出现在 SELECT、FROM、WHERE 子句中。
示例
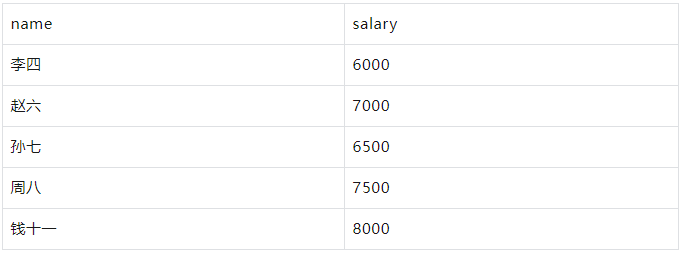
要获取薪水高于平均薪水的员工:
WITH employees AS ( SELECT 1 AS id, '张三' AS name, 1 AS department_id, 5000 AS salary UNION ALL SELECT 2, '李四', 2, 6000 UNION ALL SELECT 3, '王五', 1, 5500 UNION ALL SELECT 4, '赵六', 3, 7000 UNION ALL SELECT 5, '孙七', 2, 6500 UNION ALL SELECT 6, '周八', 3, 7500 UNION ALL SELECT 7, '吴九', 1, 4500 UNION ALL SELECT 8, '郑十', 2, 5000 UNION ALL SELECT 9, '钱十一', 3, 8000 UNION ALL SELECT 10, '王十二', 1, 4000 ) SELECT name, salary FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);
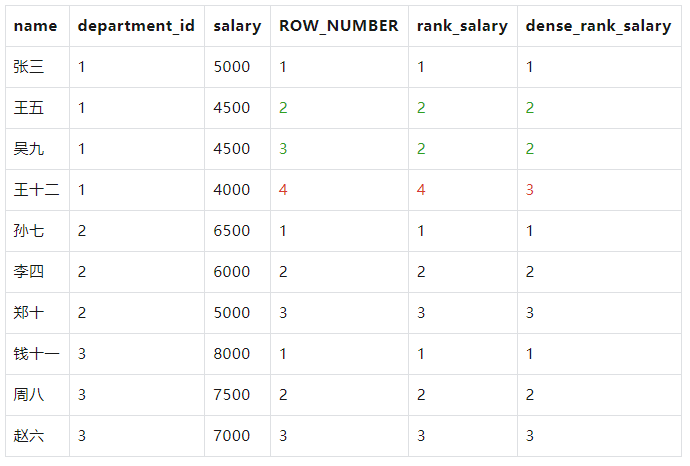
WITH employees AS ( SELECT 1 AS id, '张三' AS name, 1 AS department_id, 5000 AS salary UNION ALL SELECT 2, '李四', 2, 6000 UNION ALL SELECT 3, '王五', 1, 4500 UNION ALL SELECT 4, '赵六', 3, 7000 UNION ALL SELECT 5, '孙七', 2, 6500 UNION ALL SELECT 6, '周八', 3, 7500 UNION ALL SELECT 7, '吴九', 1, 4500 UNION ALL SELECT 8, '郑十', 2, 5000 UNION ALL SELECT 9, '钱十一', 3, 8000 UNION ALL SELECT 10, '王十二', 1, 4000 ) SELECT name, department_id, salary, ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY salary DESC) AS row_number, RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS rank_salary, DENSE_RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS dense_rank_salary FROM employees
结果:
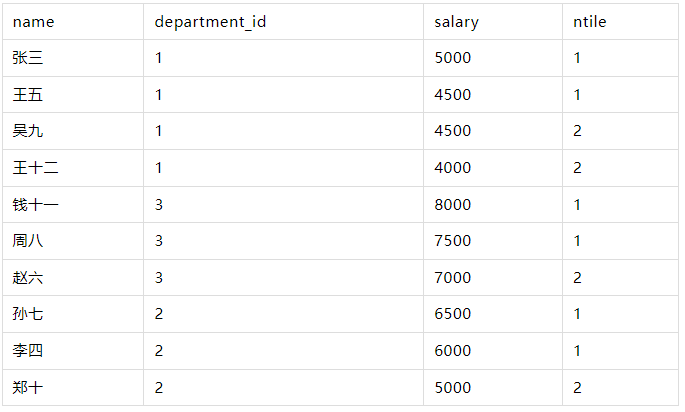
NTILE(2)
WITH employees AS ( SELECT 1 AS id, '张三' AS name, 1 AS department_id, 5000 AS salary UNION ALL SELECT 2, '李四', 2, 6000 UNION ALL SELECT 3, '王五', 1, 4500 UNION ALL SELECT 4, '赵六', 3, 7000 UNION ALL SELECT 5, '孙七', 2, 6500 UNION ALL SELECT 6, '周八', 3, 7500 UNION ALL SELECT 7, '吴九', 1, 4500 UNION ALL SELECT 8, '郑十', 2, 5000 UNION ALL SELECT 9, '钱十一', 3, 8000 UNION ALL SELECT 10, '王十二', 1, 4000 ) SELECT name, department_id, salary, NTILE(2) OVER (PARTITION BY department_id ORDER BY salary DESC) AS ntile_2 FROM employees;
结果:
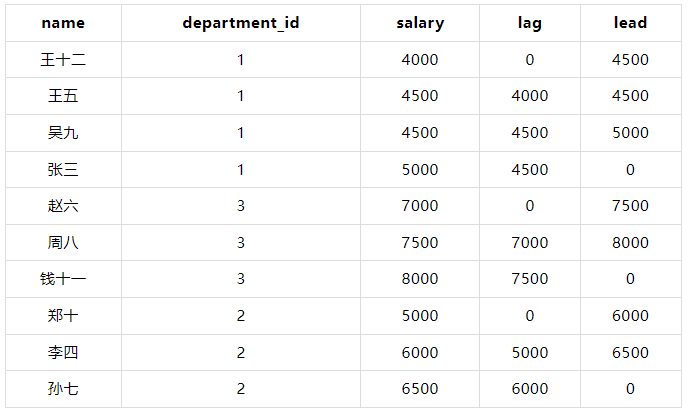
LAG() 和 LEAD()
WITH employees AS ( SELECT 1 AS id, '张三' AS name, 1 AS department_id, 5000 AS salary UNION ALL SELECT 2, '李四', 2, 6000 UNION ALL SELECT 3, '王五', 1, 4500 UNION ALL SELECT 4, '赵六', 3, 7000 UNION ALL SELECT 5, '孙七', 2, 6500 UNION ALL SELECT 6, '周八', 3, 7500 UNION ALL SELECT 7, '吴九', 1, 4500 UNION ALL SELECT 8, '郑十', 2, 5000 UNION ALL SELECT 9, '钱十一', 3, 8000 UNION ALL SELECT 10, '王十二', 1, 4000 ) SELECT name, department_id, salary, LAG(salary, 1, 0) OVER (PARTITION BY department_id ORDER BY salary) AS lag_salary, LEAD(salary, 1, 0) OVER (PARTITION BY department_id ORDER BY salary) AS lead_salary FROM employees;
结果:
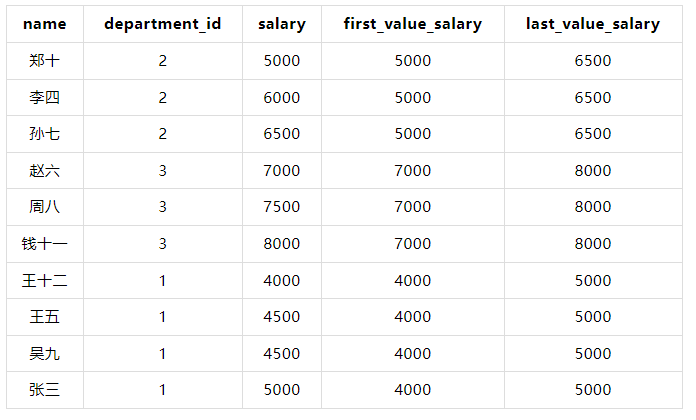
FIRST_VALUE() 和 LAST_VALUE()
WITH employees AS ( SELECT 1 AS id, '张三' AS name, 1 AS department_id, 5000 AS salary UNION ALL SELECT 2, '李四', 2, 6000 UNION ALL SELECT 3, '王五', 1, 4500 UNION ALL SELECT 4, '赵六', 3, 7000 UNION ALL SELECT 5, '孙七', 2, 6500 UNION ALL SELECT 6, '周八', 3, 7500 UNION ALL SELECT 7, '吴九', 1, 4500 UNION ALL SELECT 8, '郑十', 2, 5000 UNION ALL SELECT 9, '钱十一', 3, 8000 UNION ALL SELECT 10, '王十二', 1, 4000 ) SELECT name, department_id, salary, FIRST_VALUE(salary) OVER (PARTITION BY department_id ORDER BY salary) AS first_value_salary, LAST_VALUE(salary) OVER (PARTITION BY department_id ORDER BY salary) AS last_value_salary FROM employees;
结果
????注意: LAST_VALUE() 默认情况下会在窗口内逐行计算,如果需要在整个分区计算,可以使用 ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING。
WITH employees AS ( SELECT 1 AS id, '张三' AS name, 1 AS department_id, 5000 AS salary UNION ALL SELECT 2, '李四', 2, 6000 UNION ALL SELECT 3, '王五', 1, 4500 UNION ALL SELECT 4, '赵六', 3, 7000 UNION ALL SELECT 5, '孙七', 2, 6500 UNION ALL SELECT 6, '周八', 3, 7500 UNION ALL SELECT 7, '吴九', 1, 4500 UNION ALL SELECT 8, '郑十', 2, 5000 UNION ALL SELECT 9, '钱十一', 3, 8000 UNION ALL SELECT 10, '王十二', 1, 4000 ) SELECT name, department_id, salary, FIRST_VALUE(salary) OVER (PARTITION BY department_id ORDER BY salary) AS first_value_salary, LAST_VALUE(salary) OVER (PARTITION BY department_id ORDER BY salary ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS last_value_salary FROM employees;
结果:
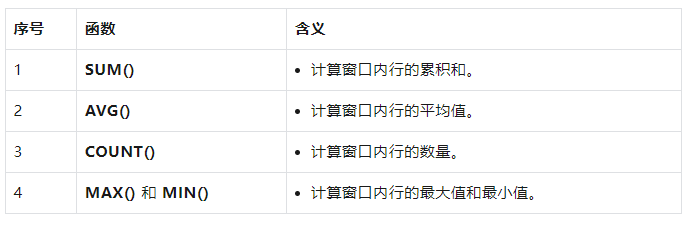
常用聚合函数在窗口中的用法
聚合函数在窗口中的用法允许你在窗口内进行聚合计算,例如计算窗口内的总和、平均值等。这通常使用 OVER 子句来定义窗口。
1. SUM() - 累积和
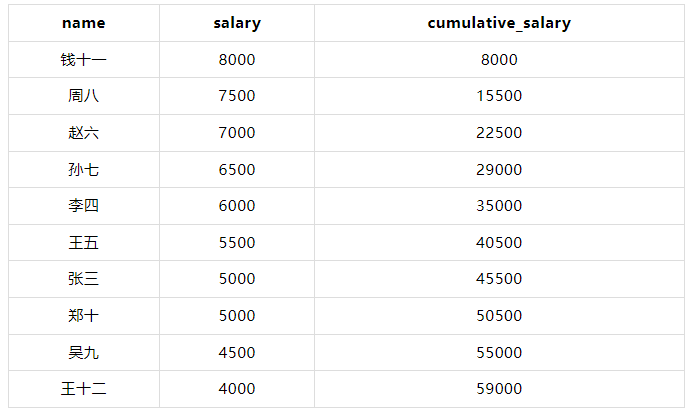
计算每个员工的累积薪水(按薪水降序排列)。
WITH employees AS ( SELECT 1 AS id, '张三' AS name, 1 AS department_id, 5000 AS salary UNION ALL SELECT 2, '李四', 2, 6000 UNION ALL SELECT 3, '王五', 1, 5500 UNION ALL SELECT 4, '赵六', 3, 7000 UNION ALL SELECT 5, '孙七', 2, 6500 UNION ALL SELECT 6, '周八', 3, 7500 UNION ALL SELECT 7, '吴九', 1, 4500 UNION ALL SELECT 8, '郑十', 2, 5000 UNION ALL SELECT 9, '钱十一', 3, 8000 UNION ALL SELECT 10, '王十二', 1, 4000 ) SELECT name, salary, SUM(salary) OVER (ORDER BY salary DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cumulative_salary FROM employees;
结果:
????在这个示例中,SUM(salary) OVER (ORDER BY salary DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) 计算从第一个行到当前行的累积薪水。
2. AVG() - 移动平均
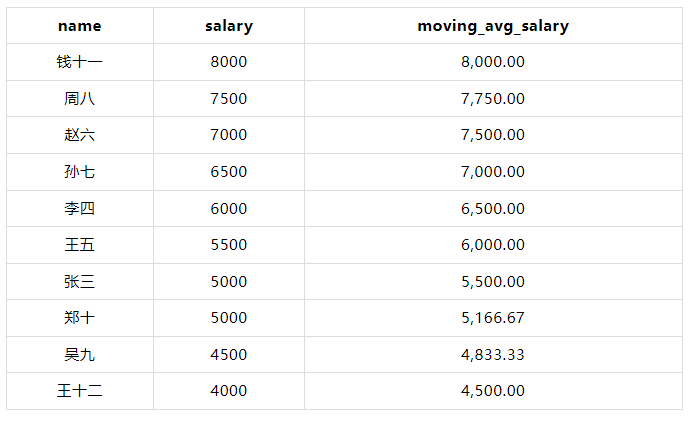
计算每个员工的移动平均薪水(按薪水降序排列,窗口大小为3)。
WITH employees AS ( SELECT 1 AS id, '张三' AS name, 1 AS department_id, 5000 AS salary UNION ALL SELECT 2, '李四', 2, 6000 UNION ALL SELECT 3, '王五', 1, 5500 UNION ALL SELECT 4, '赵六', 3, 7000 UNION ALL SELECT 5, '孙七', 2, 6500 UNION ALL SELECT 6, '周八', 3, 7500 UNION ALL SELECT 7, '吴九', 1, 4500 UNION ALL SELECT 8, '郑十', 2, 5000 UNION ALL SELECT 9, '钱十一', 3, 8000 UNION ALL SELECT 10, '王十二', 1, 4000 ) SELECT name, salary, AVG(salary) OVER (ORDER BY salary DESC ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS moving_avg_salary FROM employees;
结果:
????在这个示例中,AVG(salary) OVER (ORDER BY salary DESC ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) 计算当前行及其前两行的平均薪水。
3. COUNT() - 窗口内行数
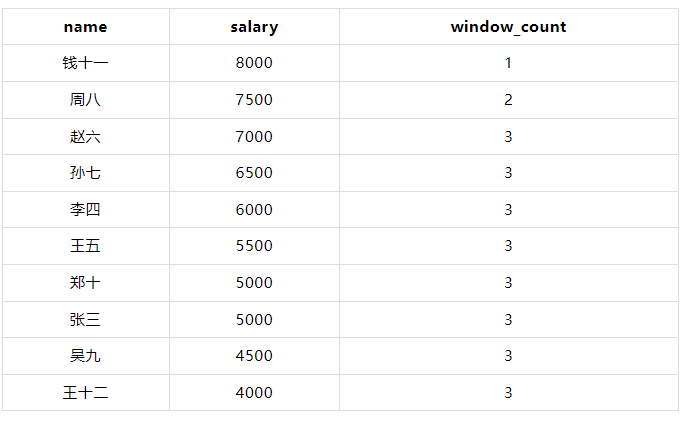
计算每个员工的窗口内行数(按薪水降序排列,窗口大小为3)。
WITH employees AS ( SELECT 1 AS id, '张三' AS name, 1 AS department_id, 5000 AS salary UNION ALL SELECT 2, '李四', 2, 6000 UNION ALL SELECT 3, '王五', 1, 5500 UNION ALL SELECT 4, '赵六', 3, 7000 UNION ALL SELECT 5, '孙七', 2, 6500 UNION ALL SELECT 6, '周八', 3, 7500 UNION ALL SELECT 7, '吴九', 1, 4500 UNION ALL SELECT 8, '郑十', 2, 5000 UNION ALL SELECT 9, '钱十一', 3, 8000 UNION ALL SELECT 10, '王十二', 1, 4000 ) SELECT name, salary, COUNT(*) OVER (ORDER BY salary DESC ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS window_count FROM employees;
结果:
????在这个示例中,COUNT(*) OVER (ORDER BY salary DESC ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) 计算当前行及其前两行的行数。
4. MAX() 和 MIN() - 窗口内最大值和最小值
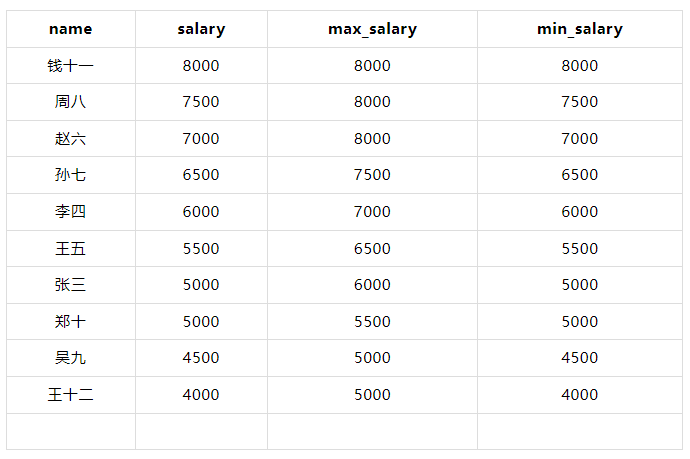
计算每个员工的窗口内最大值和最小值(按薪水降序排列,窗口大小为3)。
WITH employees AS ( SELECT 1 AS id, '张三' AS name, 1 AS department_id, 5000 AS salary UNION ALL SELECT 2, '李四', 2, 6000 UNION ALL SELECT 3, '王五', 1, 5500 UNION ALL SELECT 4, '赵六', 3, 7000 UNION ALL SELECT 5, '孙七', 2, 6500 UNION ALL SELECT 6, '周八', 3, 7500 UNION ALL SELECT 7, '吴九', 1, 4500 UNION ALL SELECT 8, '郑十', 2, 5000 UNION ALL SELECT 9, '钱十一', 3, 8000 UNION ALL SELECT 10, '王十二', 1, 4000 ) SELECT name, salary, MAX(salary) OVER (ORDER BY salary DESC ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS max_salary, MIN(salary) OVER (ORDER BY salary DESC ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS min_salary FROM employees;
结果:
????在这个示例中,MAX(salary) OVER (ORDER BY salary DESC ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) 和 MIN(salary) OVER (ORDER BY salary DESC ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) 分别计算当前行及其前两行的最大值和最小值。
WITH employees AS ( SELECT 1 AS id, '张三' AS name, 1 AS department_id, 5000 AS salary UNION ALL SELECT 2, '李四', 2, 6000 UNION ALL SELECT 3, '王五', 1, 5500 UNION ALL SELECT 4, '赵六', 3, 7000 UNION ALL SELECT 5, '孙七', 2, 6500 UNION ALL SELECT 6, '周八', 3, 7500 UNION ALL SELECT 7, '吴九', 1, 4500 UNION ALL SELECT 8, '郑十', 2, 5000 UNION ALL SELECT 9, '钱十一', 3, 8000 UNION ALL SELECT 10, '王十二', 1, 4000 ), departments AS ( SELECT 1 AS id, '销售部' AS department_name UNION ALL SELECT 2, '市场部' UNION ALL SELECT 3, '技术部' )
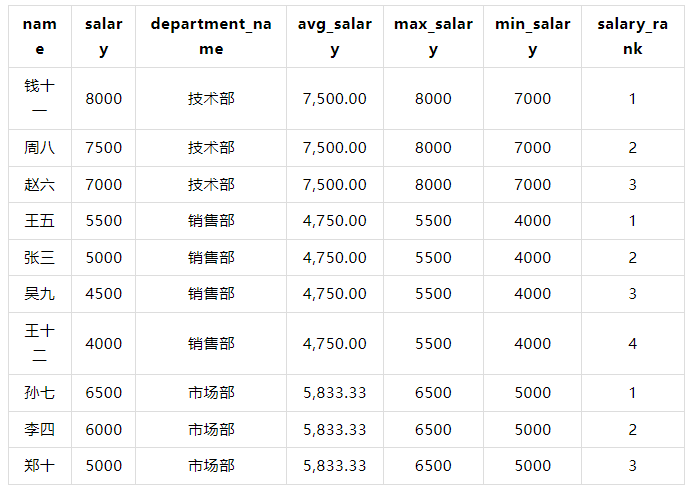
6.1.3 查询
WITH employees AS ( SELECT 1 AS id, '张三' AS name, 1 AS department_id, 5000 AS salary UNION ALL SELECT 2, '李四', 2, 6000 UNION ALL SELECT 3, '王五', 1, 5500 UNION ALL SELECT 4, '赵六', 3, 7000 UNION ALL SELECT 5, '孙七', 2, 6500 UNION ALL SELECT 6, '周八', 3, 7500 UNION ALL SELECT 7, '吴九', 1, 4500 UNION ALL SELECT 8, '郑十', 2, 5000 UNION ALL SELECT 9, '钱十一', 3, 8000 UNION ALL SELECT 10, '王十二', 1, 4000 ), departments AS ( SELECT 1 AS id, '销售部' AS department_name UNION ALL SELECT 2, '市场部' UNION ALL SELECT 3, '技术部' ), department_stats AS ( SELECT department_id, AVG(salary) AS avg_salary, MAX(salary) AS max_salary, MIN(salary) AS min_salary FROM employees GROUP BY department_id ) SELECT e.name, e.salary, d.department_name, ds.avg_salary, ds.max_salary, ds.min_salary, RANK() OVER (PARTITION BY e.department_id ORDER BY e.salary DESC) AS salary_rank FROM employees e JOIN departments d ON e.department_id = d.id JOIN department_stats ds ON e.department_id = ds.department_id;
6.1.4 结果
6.2 案例:销售数据分析
6.2.1 目标
分析每个销售员的销售业绩,包括总销售额、平均销售额以及每个销售员的排名。
6.2.2 数据准备
WITH sales AS ( SELECT 1 AS id, '张三' AS salesperson, 1000 AS amount UNION ALL SELECT 2, '李四', 1500 UNION ALL SELECT 3, '张三', 2000 UNION ALL SELECT 4, '李四', 2500 UNION ALL SELECT 5, '王五', 3000 UNION ALL SELECT 6, '王五', 3500 UNION ALL SELECT 7, '张三', 4000 UNION ALL SELECT 8, '李四', 4500 UNION ALL SELECT 9, '王五', 5000 UNION ALL SELECT 10, '张三', 5500 )
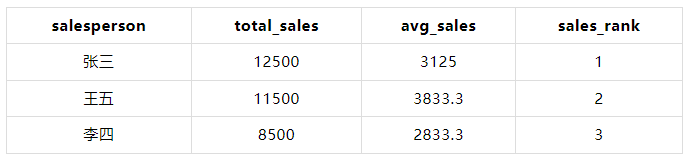
6.2.3 查询
WITH sales AS ( SELECT 1 AS id, '张三' AS salesperson, 1000 AS amount UNION ALL SELECT 2, '李四', 1500 UNION ALL SELECT 3, '张三', 2000 UNION ALL SELECT 4, '李四', 2500 UNION ALL SELECT 5, '王五', 3000 UNION ALL SELECT 6, '王五', 3500 UNION ALL SELECT 7, '张三', 4000 UNION ALL SELECT 8, '李四', 4500 UNION ALL SELECT 9, '王五', 5000 UNION ALL SELECT 10, '张三', 5500 ), sales_summary AS ( SELECT salesperson, SUM(amount) AS total_sales, AVG(amount) AS avg_sales FROM sales GROUP BY salesperson ) SELECT salesperson, total_sales, avg_sales, RANK() OVER (ORDER BY total_sales DESC) AS sales_rank FROM sales_summary;
6.2.4 结果
6.3 案例:股票价格分析
6.3.1 目标
分析股票价格的变化趋势,包括最高价、最低价以及每日价格变化。
6.3.2 数据准备
WITH stock_prices AS ( SELECT '2023-01-01' AS date, 100 AS open_price, 105 AS close_price UNION ALL SELECT '2023-01-02', 105, 110 UNION ALL SELECT '2023-01-03', 110, 108 UNION ALL SELECT '2023-01-04', 108, 112 UNION ALL SELECT '2023-01-05', 112, 115 UNION ALL SELECT '2023-01-06', 115, 113 UNION ALL SELECT '2023-01-07', 113, 118 UNION ALL SELECT '2023-01-08', 118, 120 UNION ALL SELECT '2023-01-09', 120, 119 UNION ALL SELECT '2023-01-10', 119, 122 )
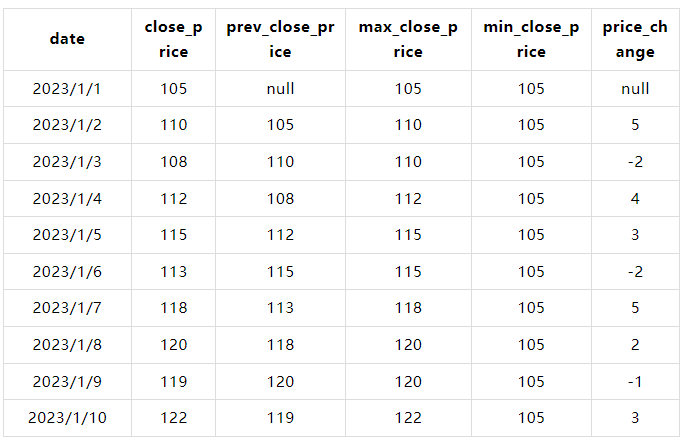
6.3.3 查询
WITH stock_prices AS ( SELECT '2023-01-01' AS date, 100 AS open_price, 105 AS close_price UNION ALL SELECT '2023-01-02', 105, 110 UNION ALL SELECT '2023-01-03', 110, 108 UNION ALL SELECT '2023-01-04', 108, 112 UNION ALL SELECT '2023-01-05', 112, 115 UNION ALL SELECT '2023-01-06', 115, 113 UNION ALL SELECT '2023-01-07', 113, 118 UNION ALL SELECT '2023-01-08', 118, 120 UNION ALL SELECT '2023-01-09', 120, 119 UNION ALL SELECT '2023-01-10', 119, 122 ), daily_stats AS ( SELECT date, close_price, LAG(close_price) OVER (ORDER BY date) AS prev_close_price, MAX(close_price) OVER (ORDER BY date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS max_close_price, MIN(close_price) OVER (ORDER BY date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS min_close_price FROM stock_prices ) SELECT date, close_price, prev_close_price, max_close_price, min_close_price, close_price - prev_close_price AS price_change FROM daily_stats;


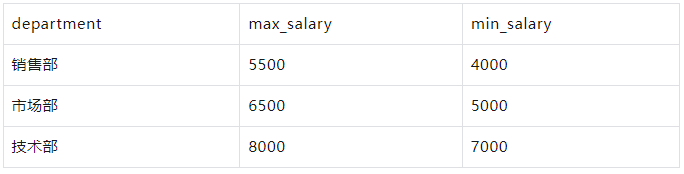













 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330