嗨喽,各位同学又到了公布CDA数据分析师认证考试LEVEL I的模拟试题时间了,今天给大家带来的是模拟试题(二)中的76-80题。
不过,在出题前,要公布上一期71-75题的答案,大家一起来看!
71、A
72、D
73、C
74、C
75、A
你答对了吗?
76.盒须图(箱线图)是利用数据中的5个统计量来描述数据的一种方法,适用于对几个样本数据的比较。在箱线图中Q1到其最近的内限距离为( )。
A.IQR
B.1.5IQR
C.0.5
D.0.75
77.下图横轴为X,纵轴为Y,则关于下图描述错误的是( )
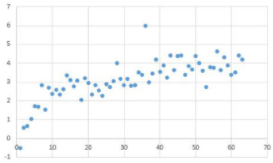
A.X 和Y 之间很大可能是非线性关系
B.这些散点中存在异常点
C.X 和Y 之间是正相关的
D.分析两者之间的关系可用逻辑回归模型
78.有一组数据的偏态系数为-4.23,那么下面表述正确的是( )
A.这是一组极度左偏的数据
B.偏态系数在0 附近,所以只是轻微的左偏
C.偏态系数在0 附近,所以只是轻微的右偏
D.这是一组极度右偏的数据
79.下面的数据是一家企业科研投入与专利产出的相关性描述,根据表格信息,下列选项中正确的是( )。

A.专利产出与科研投入高度线性相关
B.专利产出与科研投入相关性不显著
C.专利产出与科研投入存在线性相关性,但是相关性较弱
D.加大科研投入就能够提高专利的产出
80.某手机电池生产商对电池的生产工艺进行了改进,并对外宣称改进后的电池能够显著的提高手机待机时间,为了检验该改进工艺是否有效,我们将进行t检验。通常在t 检验之前我们首选需要进行( )
A.工艺改进前后的数据相关性分析。
B.使用线性回归,检验工艺改进对待机时间的影响。
C.进行F 检验,判断两个总体的方差是否存在显著差异。
D.使用卡方的独立性检验查看工艺改进与待机时间是否相关。
认真答题哦,我们将在下一期公布正确答案,敬请期待。

CDA(数据分析师认证),与CFA相似,由国际范围内数据科学领域行业专家、学者及知名企业共同制定并修订更新,迅速发展成行业内长期而稳定的全球大数据及数据分析人才标准,具有专业化、科学化、国际化、系统化等特性。
同时,CDA全栈考试布局和认证体系已得到教育部直属中国成人教育协会及大数据专业委员会认可,并由为IBM、华为等提供全球认证服务的Pearson VUE面向全球提供灵活的考试服务。
报名方式
登录CDA认证考试官网注册报名:CDA 认证考试中心官网
报名费用
Level Ⅰ:1200 RMB
Level Ⅱ:1700 RMB
Level Ⅲ:2000 RMB
考试时间
Level Ⅰ:随报随考。
Level Ⅱ:随报随考。
Level Ⅲ:一年四届(3、6、9、12月的最后一个周六),每届考前一个月截止该届报名。
考试地点
Level Ⅰ+Ⅱ:中国内地30+省市,70+城市,250+考场。考生可选择就近考场预约考试。
Level Ⅲ:中国内地30所城市,北京/上海/天津/重庆/成都/深圳/广州/济南/南京/杭州/苏州/福州/太原/武汉/长沙/西安/贵阳/郑州/南宁/昆明/乌鲁木齐/沈阳/哈尔滨/合肥/石家庄/呼和浩特/南昌/长春/大连/兰州。
点击CDA题库链接,获取免费版CDA题库入口,祝考试顺利,快速拿证!

CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330