
【导语】:今天我们来聊聊粽子,Python分析部分请看第三部分。
又到一年端午节,作为中华民族的传统节日,传说粽子是为祭奠投江的屈原而传承下来的,如今吃粽子也成了端午的主要习俗之一。除了商场出售的琳琅满目的粽子,各家各户的妈妈和奶奶们也纷纷浸糯米、洗粽叶、包粽子。
粽子的包法和形状也很有讲究,除了常见的三角粽、四角粽,还长粽、塔型粽和牛角粽等等。




说到粽子的口味就更多了。粽子几乎每年都会引发咸甜之争,有句话说的是——吃货不分南北,口味必分甜咸。




北方人吃粽子偏爱甜口,多以红枣、豆沙做馅,少数也采用果脯为馅,蘸白糖或红糖食用;
而南方青睐咸口,口味有咸肉粽、咸蛋黄粽、板栗肉粽、腊肉香肠粽、火腿粽、虾仁粽等等。

那么哪家的粽子买得最好?大家都普遍喜欢什么口味?今天我们就用数据来盘一盘端午的粽子。
本文要点:
粽子甜咸之争,自己包粽子选什么料?
吃货的力量,全网粽子谁家卖的最好?
01粽子“甜咸之争”
自己包粽子选什么料?
自己家包的粽子,永远是最好吃的,相比起来外面卖的粽子都不香了。对厨艺有自信的小伙伴们大可以自己试着包包看。
那么自己包粽子,选甜口还是咸口?馅料配红豆还是五花肉?

首先我们获取了,美食天下网站关于粽子的菜谱,共460条。看看哪些菜谱最受欢迎吧。
1甜粽还是咸粽?
在甜咸之争中,这次甜粽胜出了。
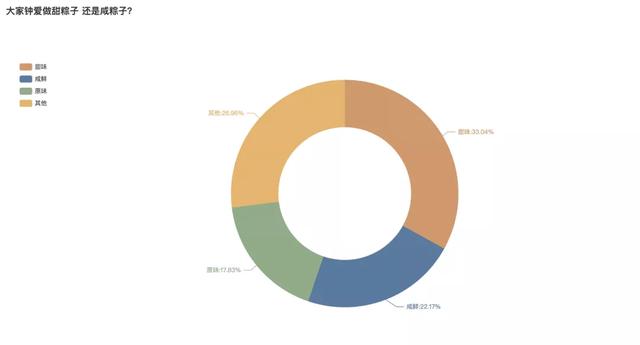
有33.04%的菜谱都是甜粽,其次22.17%才是咸粽。同时也有许多小伙伴选择最简单的纯糯米粽,原味,这部分占比17.83%。
2食材选什么
食材方面我们看到:

无论如何糯米和粽叶都是必不可少的。
然后在咸粽方面,五花肉很多人的首选,其次咸蛋黄、香菇、排骨、腊肠等都是常见的选择;在甜粽方面呢,红豆蜜枣是很多人的首选。其次绿豆、豆沙、花生米、西米等也不错。
3调料放什么
调料方面可以看到:

糖和酱油是少不了的。还花生油、蚝油等选择。除了这些常规操作,也还有选择抹茶粉这种创新的做法。
02吃货的力量
全网粽子谁家卖的最好?
出于自己不会包粽子、图方便、过节送人等考虑,直接在网上买粽子的人也不少。那么哪些店铺的粽子最受大众欢迎呢?我们分析获取了淘宝售卖粽子商品数据,共4403条。
粽子店铺销量TOP10
1首先在店铺方面:
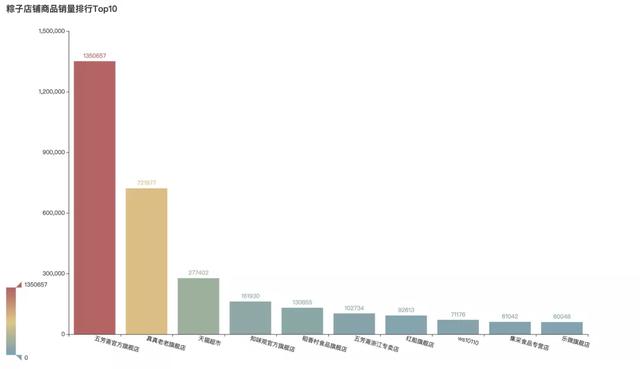
五芳斋是妥妥的霸主,粽子销量位居第一。其次真真老老位居第二。
2粽子店铺地区排行TOP10
这些店铺都来自哪里?谁是真正的粽子大省呢?
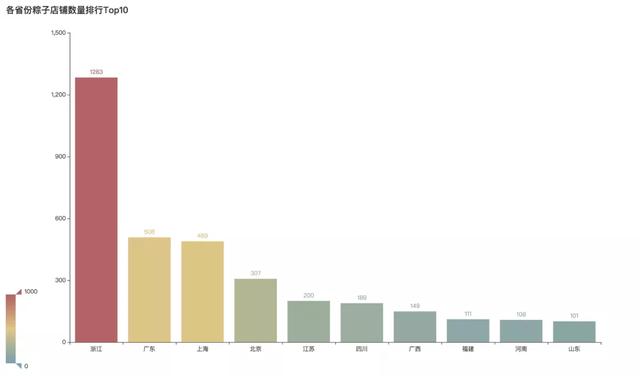
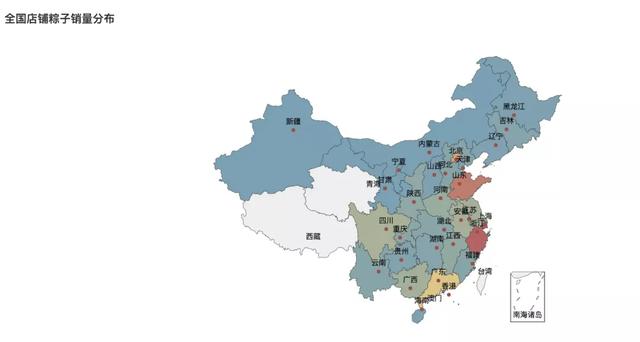
经过分析发现,浙江一骑绝尘,粽子店铺数量远远领先其他省份。浙江的粽子店铺占到全网的67.71%。毫无争议的大佬。
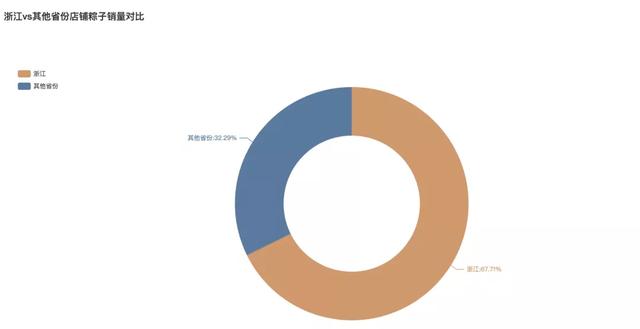
其次广东、上海、北京分部位于第二、三、四名。
3 粽子都卖多少钱?
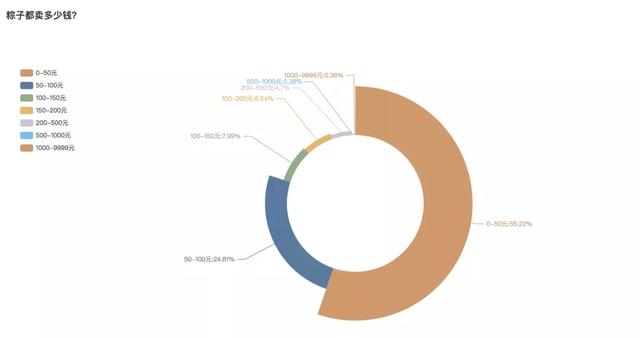
粽子都卖多少钱也是消费者们最关系的了,淘宝店铺买的粽子一般一份有10个左右。分析发现,价格在一份50元以内的还是占到绝多数,全网有55.22%的粽子都在50元内。其次是50-100元的,占比24.81%。
4不同价格粽子销量
那么销售额方面又如何呢,什么价格的粽子卖的最好?
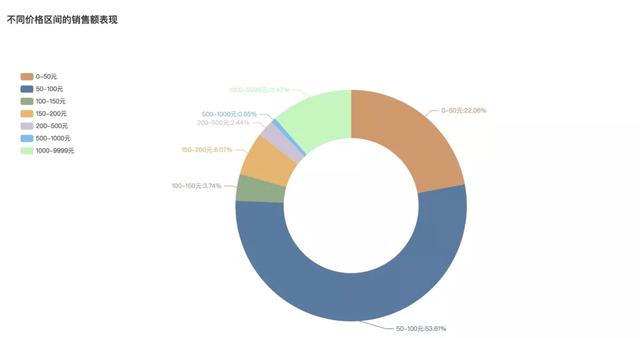
可以看到50-100元的粽子销售额最高,占比53.61%。其次是50元以内的,占比22.06%。毕竟从送礼品的角度,还是要一定价格考量的,太平价的不行,需要一定的档次。
5粽子标题词云
最后,我们再看到粽子的商品标题:

整理发现,除了"粽子"、"端午"等关键词,"嘉兴"被提到的最多。看来嘉兴的粽子是真的很有名呀。
粽子馅料方面,"蛋黄"、"鲜肉"、"豆沙"都是非常热门的。同时"礼盒包装"、"送礼"、"五芳斋"等也被多次提到。
03用Python教你
爬取淘宝粽子数据
我们使用Python获取了淘宝网粽子商品销售数据和美食天下菜谱数据,进行了一下数据分析。此处展示淘宝商品分析部分代码。按照数据读入-数据处理和数据可视化流程,首先导入我们使用的Python库,其中pandas用于数据处理,jieba用于分词,pyecharts用于可视化。
# 导入包
import pandas as pd
import time
import jieba
from pyecharts.charts import Bar, Line, Pie, Map, Page
from pyecharts import options as opts
from pyecharts.globals import SymbolType, WarningType
WarningType.ShowWarning = False
1数据导入
# 读入数据
df_tb = pd.read_excel('../data/淘宝商城粽子数据6.23.xlsx')
df_tb.head()

查看一下数据集大小,可以看到一共有4403条数据。
df_tb.info()
RangeIndex: 4403 entries, 0 to 4402
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 goods_name 4403 non-null object
1 shop_name 4403 non-null object
2 price 4403 non-null float64
3 purchase_num 4403 non-null object
4 location 4403 non-null object
dtypes: float64(1), object(4)
memory usage: 172.1+ KB
2数据预处理
我们对数据集进行以下处理,以便我们后续的可视化分析工作,经过处理之后的数据共4192条。
去除重复值
goods_name:暂不处理
shop_name:暂不处理
price:暂不处理
purchase_num:提取人数,注意单位万的处理
计算销售额 = price * purchase_num
location:提取省份
# 去除重复值
df_tb.drop_duplicates(inplace=True)
# 删除购买人数为空的记录
df_tb = df_tb[df_tb['purchase_num'].str.contains('人付款')]
# 重置索引
df_tb = df_tb.reset_index(drop=True)
# 提取数值
df_tb['num'] = df_tb['purchase_num'].str.extract('(\d+)').astype('int')
# 提取单位
df_tb['unit'] = df_tb.purchase_num.str.extract(r'(万)')
df_tb['unit'] = df_tb.unit.replace('万', 10000).replace(np.nan, 1)
# 重新计算销量
df_tb['true_purchase'] = df_tb['num'] * df_tb['unit']
# 删除列
df_tb = df_tb.drop(['purchase_num', 'num', 'unit'], axis=1)
# 计算销售额
df_tb['sales_volume'] = df_tb['price'] * df_tb['true_purchase']
# 提取省份
df_tb['province'] = df_tb['location'].str.split(' ').str[0]
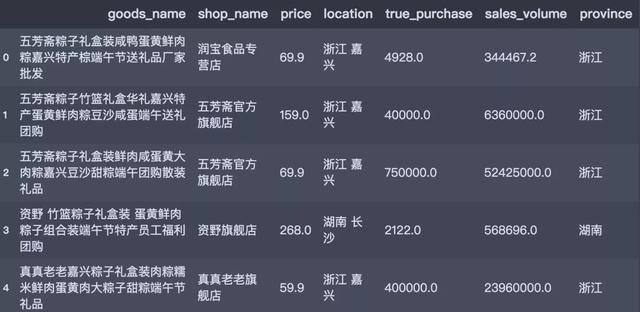
df_tb.head()
3数据可视化
数据可视化部分主要对以下的数据进行汇总分析,分析维度如下:
粽子店铺商品销量排行
各省份粽子店铺数量排行
各省份粽子销量分布
粽子都卖多少钱?
不同价格区间的销售额分布?
粽子的食材
商品标题词云图
粽子店铺商品销量排行Top10
shop_top10 = df_tb.groupby('shop_name')['true_purchase'].sum().sort_values(ascending=False).head(10)
# 条形图
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(shop_top10.index.tolist())
bar1.add_yaxis('', shop_top10.values.tolist())
bar1.set_global_opts(title_opts=opts.TitleOpts(title='粽子店铺商品销量排行Top10'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
visualmap_opts=opts.VisualMapOpts(max_=1350657.0)
)
bar1.render()
各省份粽子店铺数量排行Top10
province_top10 = df_tb.province.value_counts()[:10]
# 条形图
bar2 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar2.add_xaxis(province_top10.index.tolist())
bar2.add_yaxis('', province_top10.values.tolist())
bar2.set_global_opts(title_opts=opts.TitleOpts(title='各省份粽子店铺数量排行Top10'),
visualmap_opts=opts.VisualMapOpts(max_=1000)
)
bar2.render()
浙江vs其他省份店铺粽子销量对比
names = ['浙江', '其他省份']
numbers = [3378601.0. 1611409.0]
data_pair = [list(z) for z in zip(names, numbers)]
# 绘制饼图
pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
pie1.add('', data_pair, radius=['35%', '60%'])
pie1.set_global_opts(title_opts=opts.TitleOpts(title='浙江vs其他省份店铺粽子销量对比'),
legend_opts=opts.LegendOpts(orient='vertical', pos_top='15%', pos_left='2%'))
pie1.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
pie1.set_colors(['#EF9050', '#3B7BA9'])
pie1.render()
全国店铺粽子销量分布
province_num = df_tb.groupby('province')['true_purchase'].sum().sort_values(ascending=False)
# 地图
map1 = Map(init_opts=opts.InitOpts(width='1350px', height='750px'))
map1.add("", [list(z) for z in zip(province_num.index.tolist(), province_num.values.tolist())],
maptype='china'
)
map1.set_global_opts(title_opts=opts.TitleOpts(title='全国店铺粽子销量分布'),
visualmap_opts=opts.VisualMapOpts(max_=300000),
)
map1.render()
粽子都卖多少钱?
# 分箱
bins = [0.50.100.150.200.500.1000.9999]
labels = ['0-50元', '50-100元', '100-150元', '150-200元', '200-500元', '500-1000元', '1000-9999元']
df_tb['price_cut'] = pd.cut(df_tb.price, bins=bins, labels=labels, include_lowest=True)
price_num = df_tb['price_cut'].value_counts()
# 数据对
data_pair2 = [list(z) for z in zip(price_num.index.tolist(), price_num.values.tolist())]
# 绘制饼图
pie2 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
pie2.add('', data_pair2. radius=['35%', '60%'], rosetype='radius')
pie2.set_global_opts(title_opts=opts.TitleOpts(title='粽子都卖多少钱?'),
legend_opts=opts.LegendOpts(orient='vertical', pos_top='15%', pos_left='2%'))
pie2.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
pie2.set_colors(['#EF9050', '#3B7BA9', '#6FB27C', '#FFAF34', '#D8BFD8', '#00BFFF'])
pie2.render()
不同价格区间的销售额
# 添加列
cut_purchase = round(df_tb.groupby('price_cut')['sales_volume'].sum())
# 数据对
data_pair = [list(z) for z in zip(cut_purchase.index.tolist(), cut_purchase.values.tolist())]
# 绘制饼图
pie3 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
pie3.add('', data_pair, radius=['35%', '60%'])
pie3.set_global_opts(title_opts=opts.TitleOpts(title='不同价格区间的销售额表现'),
legend_opts=opts.LegendOpts(orient='vertical', pos_top='15%', pos_left='2%'))
pie3.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
pie3.set_colors(['#EF9050', '#3B7BA9', '#6FB27C', '#FFAF34', '#D8BFD8', '#00BFFF', '#7FFFAA'])
pie3.render()
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330