Python实现计算最小编辑距离
最小编辑距离或莱文斯坦距离(Levenshtein),指由字符串A转化为字符串B的最小编辑次数。允许的编辑操作有:删除,插入,替换。具体内容可参见:维基百科—莱文斯坦距离。一般代码实现的方式都是通过动态规划算法,找出从A转化为B的每一步的最小步骤。从Google图片借来的图,
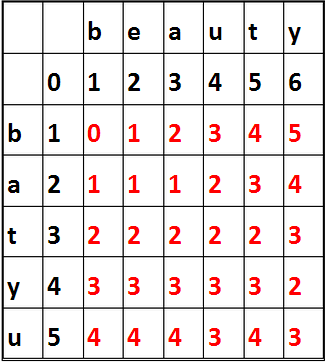
Python代码实现, (其中要注意矩阵的下标从1开始,而字符串的下标从0开始):
def normal_leven(str1, str2):
len_str1 = len(str1) + 1
len_str2 = len(str2) + 1
#create matrix
matrix = [0 for n in range(len_str1 * len_str2)]
#init x axis
for i in range(len_str1):
matrix[i] = i
#init y axis
for j in range(0, len(matrix), len_str1):
if j % len_str1 == 0:
matrix[j] = j // len_str1
for i in range(1, len_str1):
for j in range(1, len_str2):
if str1[i-1] == str2[j-1]:
cost = 0
else:
cost = 1
matrix[j*len_str1+i] = min(matrix[(j-1)*len_str1+i]+1,
matrix[j*len_str1+(i-1)]+1,
matrix[(j-1)*len_str1+(i-1)] + cost)
return matrix[-1]
最近看文章看到Python库提供了一个包difflib实现了从对象A转化对象B的步骤,那么计算最小编辑距离的代码也可以这样写了:
def difflib_leven(str1, str2):
leven_cost = 0
s = difflib.SequenceMatcher(None, str1, str2)
for tag, i1, i2, j1, j2 in s.get_opcodes():
#print('{:7} a[{}: {}] --> b[{}: {}] {} --> {}'.format(tag, i1, i2, j1, j2, str1[i1: i2], str2[j1: j2]))
if tag == 'replace':
leven_cost += max(i2-i1, j2-j1)
elif tag == 'insert':
leven_cost += (j2-j1)
elif tag == 'delete':
leven_cost += (i2-i1)
return leven_cost
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330