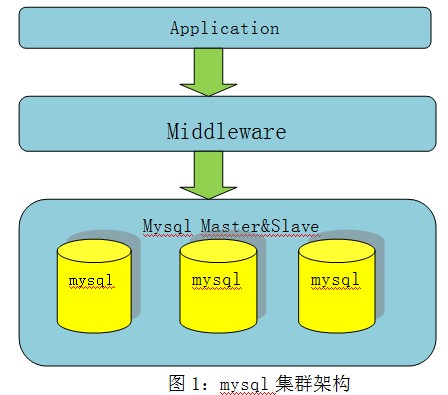
互联网网站应用大多采用mysql作为DB存储,限于mysql单机性能的瓶颈,为了支撑更大容量和更大的访问量,dba一般通过建立
分布式集群,让多个mysql共同提供服务。所谓的mysql分布式集群,实质就是将原有的数据拆成多份,放在多个mysql数据库上存储,应用通过中间
层路由到对应的数据库分片,访问所需要数据,基本架构如图1所示。这里的关键点就是“拆”,如何拆库,根据业务场景,一般可以采取水平拆分和垂直拆分。所
谓水平拆分是指,将一个大表按一定的规则分片,分布在多个mysql数据库中;垂直拆分则是指根据业务模块划分,将不同模块分布在不同的mysql数据库
中。无论是水平拆分,还是垂直拆分,对于底层运维人员来说,迁移扩容的本质是一样的。本文会结合一个具体的例子,详细讲解mysql拆库的具体步骤。
前提:mysq集群部署采用MM架构,Master与Slave采用双向复制,Master对外提供服务,Slave作为热备。
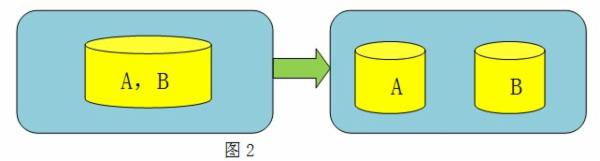
假设:实例上有库A和库B,目前受限于单机mysql的性能瓶颈,需要扩容。
目的:将库B拆出来,使得库A和库B分别单独占用物理机,如图2所示
实施步骤:
1.搭建备库
Mysql搭建备库主要有两种方式,逻辑备份(mysqldump)或物理备份(extrabackup)。由于我们需要将其中一个库拆出来,选择mysqldump会比较合适。
|
mysqldump -uxxx -pxxx –h ip_addr -P
port --databases B mysql --master-data=2 --single-transaction
--default-character-set=xxx > /u01/bak/B_dump.sql
2>/u01/bak/B_dump.log &
|
说明:
1) 参数
--master-data=2,--single-transaction这两个参数一起使用,全局读锁只会在dump开始的时
候加一小段时间,通过设置repeatable
read隔离级别,保证读取事务开始时的数据,获取一致性数据,并且在备份文件开头处显示位点(File,Position)。
2) 为什么要备份mysql库
这里是因为数据库的元数据信息都存储在mysql中,比如表定义,用户 信息等,因此需要一起备份过去。
2. 检查备份是否成功
|
查看/u01/bak/B_dump.sql的结尾是否有dump complete
查看/u01/bak/B_dump.log文件是否异常输出
|
3.导入备份到新机器
|
Mysql –uroot</u01/bak/B_dump.sql>B_import.log 2>&1 &
|
4.导入增量
1) 由于老库上面有A,B两个库,新库只有B库,通过复制获取增量时,必然会导致报错,因此在导入前需要对新库设置复制过滤参数,replicate-do-db
|
replicate-do-db=mysql
replicate-do-db=B
|
2) 新库与老库建立复制关系,这里需要用到步骤1获取的位点信息(File,Position)
|
CHANGE master TO master_host=xxx, master_port=xxx,master_user='slave',master_password='slave',
master_log_file=File,master_log_pos=Position;
|
5. 等待新库与老库同步,至此新库与老库复制结构如下图

6. 切换
1) 将New M设置为可写状态,并将Old M与New M构成双M架构

备注:红色代表本次操作的复制变动
2) 通知应用将B库流量切换到New Master,由于这里设置到中间件的细节,不同公司采用的中间件不一样,这里不作说明
3) B库流量全部切换到New Master 后,检查Old Master是否还有B库流量访问,确定没有,调整复制结构

备注: 检查是否还有流量,可以通过show processlist看看是否还有连接来验证。
7.切换完毕 ,断开New Master 和Old Master的复制

8.善后
清理Old Master的B库数据,释放磁盘空间。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330