数据科学就业市场正在迅速变化。能够建立机器学习模型曾经是只有少数杰出科学家才具备的一项精英技能。但是现在,任何具有基本编程经验的人都可以按照以下步骤来训练一个简单的scikit-learn或keras模型。招聘人员收到了大量的求职申请,因为围绕“本世纪最性感的工作”的炒作几乎没有减弱,而招聘工具正变得越来越容易使用。人们对数据科学家应该带来什么的期望已经发生了变化,企业开始认识到,训练机器学习模型只是数据科学成功的一小部分。
下面是让最好的数据科学家脱颖而出的四个最有价值的品质。
1.聚焦业务
对数据科学家来说,最常见的动机之一是对在数据中发现模式的自然好奇心。深入研究探索数据集的工作是令人兴奋的,用该领域的最新技术进行实验,系统地测试它们的效果,并发现一些新的东西。这种类型的科学动机是数据科学家应该具备的。但如果它是唯一的动力,那就成了问题。在这种情况下,它可能导致人们在一个孤立的泡沫中思考,迷失在统计细节中,而没有考虑他们工作的具体应用和公司的更大背景。
最好的数据科学家了解他们的工作如何与整个公司相适应,并具有交付业务价值的内在驱动力。当简单的解决方案足够好时,他们不会浪费时间在复杂的技术上。他们询问项目的更大目标,并在跳到解决方案之前挑战核心假设。他们关注整个团队的影响,并主动与涉众沟通。他们对新项目充满创意,敢于打破常规。他们为自己帮助了多少人而自豪,而不是他们使用的技术有多先进。
数据科学在很大程度上仍是一个不标准化的领域,数据科学训练营所教授的内容与企业实际需要的内容之间存在很大差距。最好的数据科学家不怕走出自己的舒适区,去解决紧迫的问题,并最大限度地发挥其影响。
2.扎实的软件工程技能
当人们想到理想的数据科学家时,他们脑海中往往会浮现出来自名牌大学的著名人工智能教授。当公司正在竞争建立尽可能高精确度的机器学习模型时,招聘这样的人才是有意义的。当用任何必要的方法挤出最后一个精度百分比非常重要时,那么你就需要注意数学细节,测试最复杂的方法,甚至发明专门针对特定用例进行优化的新的统计技术。
但在现实世界中,这几乎没有必要。对于大多数公司来说,具有相当精确度的标准模型已经足够好了,不值得花费时间和资源把这些模型变成世界上最先进的模型。更重要的是,要快速地以可接受的精度构建模型,并尽早建立反馈周期,这样你就可以开始迭代并加速识别最有价值的用例的过程。准确性上的微小差异通常不是数据科学项目成功或失败的原因,这也是为什么在商业世界中软件工程技能胜过科学技能的原因。
数据团队的典型工作流程通常是这样的:数据科学家用反复试验的代码和意大利面条式的代码构建了一些解决方案的原型。一旦结果开始看起来很有希望,他们就把它们交给软件工程师,然后他们必须从头重写所有内容,使解决方案具有可扩展性、效率和可维护性。不能期望数据科学家交付与全职软件工程师水平相当的生产代码,但是如果数据科学家更熟悉软件工程原理,并且对可能出现的体系结构问题有一定的认识,那么整个过程将会更加顺畅和快速。
随着越来越多的数据科学工作流被新的软件框架所取代,扎实的工程技能是数据科学家最重要的技能之一。
3.关注期望管理
从外部来看,数据科学可能是一个非常模糊和令人困惑的领域。这只是一种炒作,还是世界真的正在经历一场革命性的变革?每个数据科学项目都是机器学习项目吗?这些人是科学家、工程师还是统计学家?他们的主要输出软件还是仪表盘和可视化?为什么这个模型向我展示了一个错误的预测,有人能修复这个bug吗?如果他们现在只有这几行代码,那么在过去的一个月里他们一直在做什么呢?
有很多事情是不清楚的,数据科学家应该做什么,在公司的不同人之间的期望可能会有很大的差异。
对于数据科学家来说,主动地、持续地与涉众沟通是至关重要的,这样才能设定清晰的预期,及早发现误解,并让所有人都站在同一立场上。
最好的数据科学家了解其他团队的不同背景和议程如何影响他们的期望,并仔细调整他们的沟通方式。他们能够以简单的方式解释复杂的方法,以便非技术涉众更好地理解目标。他们知道什么时候该抑制过于乐观的预期,什么时候该说服过于悲观的同事。最重要的是,他们强调数据科学固有的实验性质,当一个项目的成功仍不明朗时,他们不会过度承诺。
4.熟悉云服务
云计算是数据科学工具包的核心部分。在很多情况下,在本地机器上摆弄Jupyter notebook已经达到极限了,不足以完成任务。当你需要在功能强大的gpu上训练机器学习模型、在分布式集群上并行化数据预处理、部署REST api来公开机器学习模型、管理和共享数据集或查询数据库以进行可扩展分析时,云服务尤其有用。
最大的供应商是Amazon Web Services (AWS)、Microsoft Azure和谷歌云平台 (GCP)。
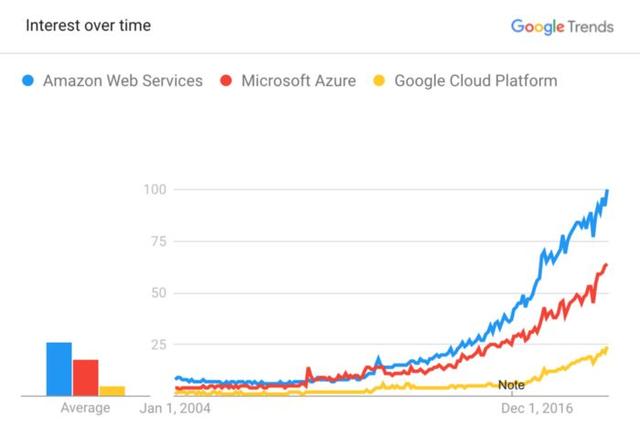
考虑到大量的服务和平台之间的差异,云服务提供商几乎不可能胜任必须提供的所有服务。但是,对云计算有一个基本的了解是很重要的,以便能够浏览文档并了解在需要时这些特性是如何工作的。至少,这可以让你向其他数据工程师提出更好的问题和更具体的需求。
好了。对于正在寻求数据科学团队的公司,我建议寻找能够务实解决问题,有很强的工程能力,能够调整对业务价值的候选人。统计优势可以带来很多价值,但是对于大多数用例来说,它变得不那么重要了,尤其是在早期的团队中。
到目前为止,大多数公司更倾向于雇佣具有强大学术背景的数据科学家,比如数学或物理博士。考虑到该行业近年来的发展,未来是否会有更大比例的软件工程师或技术产品经理转变为数据科学角色,将是一个有趣的问题。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330