健康云上如何进行大数据的挖掘与分析(三)
三、健康云上的大数据分析
由于医疗数据的一些特有的性质,给健康云上的大数据分析带来了特殊的挑战。
1、 医疗数据是持续、大量增长的大数据。根据估算,中国一个中等城市(一千万人口)50年所积累的医疗数据量就会达到10PB级。并且,随着时间的推移和业务系统的不断升级换代,医疗数据模式的一致性也无法保证。因此,每天都会有大量的数据持续不断的导入区域医疗数据中心,并且每当有数据模式的更改,相关的历史数据也需要做相应的调整。所以,区域医疗数据中心并不是简单的传统数据仓库概念。相比之下,它的模式更灵活、写入和更新的操作更多,而对数据存储的水平可扩展性的要求也更高。
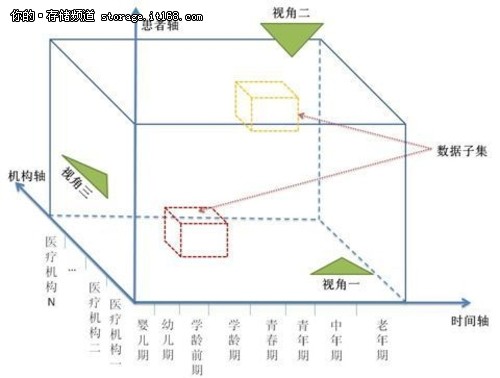
2、 医疗数据是关系复杂的多维数据。由于医疗数据是多种数据源数据的汇总,数据之间的关系非常复杂。比如:一个简单的实验室检验检测值,必须同时记录这个值对应的编码系统和编码、单位、检测时间、检验项目、标本编码,以及相关联的患者主索引号、就诊机构、申请科室、申请医师标识号、报告医师标识号、审核医师标识号、正常值参考等等。一条检测记录就可以把患者、医生、医疗机构多个实体在不同层次上关联起来。而不同的医疗信息服务更需要从不同的视角来观察这些数据,如下图所示。比如:以患者为中心的服务需要把一个患者的全周期数据按照时间轴排列,并分析诊断、用药和患者生命体征、检验检测值之间的关联;以医生为中心的服务又需要把与一个医生相关的患者数据挑拣出来,并进行分类;以科室为中心的服务可能需要即从科室所属医生的角度,又要从在该科室就诊患者的角度进行分析;针对社区的服务可能需要统计整个社区居民某项指标(比如血压、血糖)的达标率。总之,医疗数据的多维度多粒度为各种信息服务的多角度多层次分析提供了可能,但同时也为大数据分析带来了挑战。因为我们不可能为每一种信息服务存储一份特定的优化模式的数据,况且我们也无法枚举出所有可能的信息服务需求。这就需要医疗数据的存储模型能够适应灵活多变的多维统计分析需求。
3、 医疗数据是具有语义的数据。大家可能听说过语义网(Semantic Web),它是为让数据能跨应用进行共享和重用所设计的框架体系。我们可以把语义网简单地理解为:一个让机器(machines)读懂的维基百科(Wikipedia),主要包括了各种条目的定义以及各个条目之间的关系。如果数据也采用这些条目和关系组织内容,那么机器就可以自动理解数据的语义,并推理出各种知识。所以建立语义网的关键就是如何制作一本百科全书(有个专有名词叫Ontology)。由于医学是一门非常严谨的科学,其在全球的标准化水平很高,对疾病名称、药物成分、临床特征、仪器设备等都有严格的定义以及关联描述。所以,语义网在医学领域得到了广泛应用。进而,医疗数据也越来越多的采用基于语义网的临床文档框架(CDA)格式的XML文档来保存。这些XML文档通过Ontology的解释,就变成了一个无比巨大的概念+事实+关系的网络。虽然机器能够读懂这个网络,并能够在上面进行逻辑推理,从而发现知识,但是其计算代价也是相当高的。当前的医疗系统通常会把复杂的临床文档解析成简单的属性值,并存入自定义的关系表中。这样做虽然会有大量的语义及关系的丢失,但却能够满足日常业务系统对数据处理性能的要求。但是对于未来的区域医疗信息系统来说,为了能够提供丰富全面的信息服务,我们必须尽可能的保留临床文档中的语义信息。这样,医疗数据分析的过程中就不可避免的需要对大量XML文档进行解析、对各种关系进行推理。这样的数据分析处理过程比我们之前提到的互联网数据处理要复杂得多。
通过上述的分析可见,简单地将现有的大数据分析技术套用在健康云服务上是行不通的。我们需要充分考虑健康云服务的特点和充分利用现有技术框架的灵活性,已达到最好的大数据分析性能。EMC中国研究院大数据实验室正在涉足于健康云领域的大数据分析技术。根据我们已掌握的技术,我们提出了如下的初步解决方案:
1. 基于Hadoop生态系统构建健康云数据中心,用以解决数据存储水平扩展的挑战。利用MapReduce并行处理批量事务的能力,从多个数据源(主要是医疗机构的各个业务系统)抽取数据、转换格式、并导入基于HBase的数据存储模型。
2. 在数据存储模型的设计上,我们将充分借鉴已有的数据仓库中多维数据模型的设计思想,比如:星型模式和数据立方体的概念。在考虑应用需求的基础上,利用HBase中行键、列键、列族设计的灵活性,将多维医疗数据有效地组织在一起。而在索引技术上,我们会结合RDBMS领域的成熟技术,用以进一步提高HBase的查询性能。对于数据模式的更新,HBase特有的多版本共存的特性正好成了解决问题的关键。
3. 为了保留医疗数据中大量的语义关系,我们将采用结构化数据+XML文档混合存储的方式。在数据导入的同时,提取XML文档中特定的元数据,(比如:患者主索引、就诊科室、主治医师等),并将XML文档根据不同粒度打散成大小不一的子文档。根据不同粒度的查询条件,系统将自动选择相应的子文档进行进一步信息的解析,从而避免为提取少量信息而不得不解析大量XML文档的问题。
4. 数据模型的接口将采用Hive提供的类SQL查询的方式。这样更有利于数据分析人员设计分析算法。同时,我们的系统中将嵌入多种数据挖掘算法供数据分析师使用。
综上所述,为解决健康云上的大数据分析问题,我们必须同时利用RDBMS和NoSQL的优势,并且采用结构化和非结构化数据混合存储的形式,相互弥补缺陷,已达到最灵活和最高效的设计。而这套基于健康云的大数据分析平台,也将有希望扩展到其他类似行业,比如:电信、能源、物联网和公共事业等。
总结
在我国,健康云的发展才是刚刚起步。我们相信,在不久的将来,我国的区域医疗解决方案市场将会有突飞猛进的发展,文中提到的医疗信息服务将会真正的走入我们的日常生活。为此,EMC中国研究院已经走在了技术发展的前列,旨在为健康云的实现提供先进的技术支持。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330