大数据时代个性化健康预测
本周Nature新闻与观点中评述了Zeevi等人在Cell中报导的一项研究:一个人的血糖浓度如何受特定的食物影响的复杂问题。根据他们肠道中的微生物和其他方面的生理状况,提出了一种可以提供个性化的食物建议的预测模型。
肥胖和Ⅱ型糖尿病正在让发达国家忧愁。一个人的餐后血糖反应(PPGR),是Ⅱ型糖尿病风险的预测。上升得越高,风险越大。因为这个环节,具体指示了一个人是如何能保持血糖控制的。Zeevi等人给800个人安装了皮下探针,超过一周每五分钟测量他们的血糖水平的过程。除了5107组提供标准化的膳食之外,参与者吃了他们的典型食谱和做了详细的膳食记录。研究包含了52005餐的内容,然后分析了150万多个的葡萄糖测量。
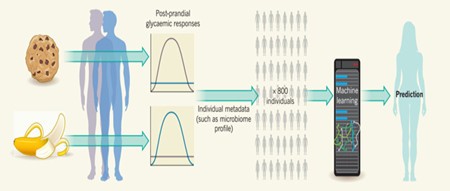
数据显示了对于相同(标准化)的伙食和自我报告的相似饮食的PPGRS重要人际变化和差异。此外,不同的食物引起最高PPGRS差异要比不同的个体之间差异大:香蕉有比饼干对一个人更大的作用,但换另外一个人却是相反的。这些发现可以解释为什么控制PPGR的标准饮食干预不能均匀有效地作用于整个人群。
为了找到高度个人化的血糖对食品反应的意义,作者转向针对每一个人收集大量的数据。包括生理特征的分析,如身体质量指数;如胆固醇水平等血液标志物;从调查问卷收集的行为数据,例如活动水平和睡眠习惯;参与者肠道菌群分布,包括菌群物种组成和相关基因组序列。数据立即显示一个人的PPGRS和已知Ⅱ型糖尿病风险相关的因素,如身体质量指数和血压。然而,其他的医学特征不那么明显的方面也与PPGRS相关,包括特定的类群存在的微生物,如大肠杆菌,特别是那些参与趋化运动细菌的基因。
然后,作者使用了一个“决策树”的机器学习方法来创建一个算法,整合所有的这些元数据。这种方法在800人的交叉验证中被证明PPGRS是可以预测的,用其他799名参与者的数据生成算法也意味着可以预测一个人的PPGRS。该算法还预测了一个100人的不参与训练算法的独立数据的PPGRS。
作者发现在元数据中和一个人的PPGRS相关的几个特点。正如预期的那样,增加碳水化合物的消耗是增加的PPGR紧密联系在一起的。增加膳食纤维的存在会在消化后不久的增加PPGR,但在接下来的24小时内降低PPGR。预测PPGRS也有几个特点:不涉及餐饮消耗,包括睡眠、微生物的生理活性和方面。
总的来说,这种方法比目前的金标准能更准确的预测血糖反应,它是基于每餐碳水化合物的含量。在最后的测试,作者招募了26个新的参与者,给予量身定制的膳食建议,每个参与者既使用他们的算法也由专家解读这些人特定膳食的PPGRS。建议由该模型的基础上改进的PPGRS和由专家建议血糖水平的稳定性而提出。
虽然先前已在几个方面:从肥胖到自闭症,对肠道菌群与疾病的关系展开研究,这样相关性的机制大多未知。Zeevi和他同事的方法很大的一个优势是,这种机制不需要知道它的工作原理。然而,这项研究提供了一个路线图,用于产生和测试机制的假设。例如,Akkermansiamuciniphila菌,降解肠道的糖蛋白粘蛋白,这与作者发现的更高的PPGRS相关,有助于血糖的反应。如果是这样,进一步研究是怎样作用的。作者在人体大数据集和机器学习方法对适用和相关人的机理研究提供了一个良好的起点。
在现在这个时间,大多数微生物的研究者们不打算模仿天气预报,预测一个人对于饮食或药物对他们的肠道菌群作用的反应。然而,当结合机器学习算法,采用了额外的生物学指标,这样的预测似乎更不令人畏惧。机器学习方法除了在PPGRS的应用,如治疗自身免疫性疾病、心血管疾病和癌症,可能会跟着更迅速地发展。在“大数据”科学的时代,我们可以分析大量的参数。多维数据的最具预测性的方面的能力将是非常强大的。
虽然以前的研究如何个别菌群谱系的复杂性可以告知个性化医疗是艰难的,但该研究对一个乐观的预测提供了依据。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330