


2020-11-15
阅读量:
2418
在 Power BI Desktop 中使用聚合
借助 Power BI 中的聚合,可缩小表的大小,以便专注于重要数据并提高查询性能。 聚合能够以无法另行实现的方式对大数据执行交互式分析,并且可大幅降低解锁大型数据集用于做出决策的成本。
优点包括:
更高的大数据查询性能。 与 Power BI 视觉对象的每次交互都会向数据集提交 DAX 查询。 缓存的聚合数据使用详细信息数据所需资源的一小部分,因此,可解锁通过其他方式无法访问的大数据。
优化的数据刷新。 更小的缓存大小可减少刷新时间,因此,用户可以更快地获得数据。
平衡的体系结构。 Power BI 内存中缓存可处理聚合查询、限制 DirectQuery 模式下发送的查询以及帮助满足并发限制。 剩余的详细信息级查询通常是经过筛选的事务级查询,数据仓库和大数据系统通常能够很好地处理此类查询。
若要创建聚合表,请执行以下操作:
根据数据源和模型,使用所需字段设置新表。
使用“管理聚合”对话框定义聚合 。
如果适用,请更改聚合表的存储模式。
管理聚合
创建具有所需字段的新表后,在任何 Power BI Desktop 视图的“字段”窗格中,右键单击该表,然后选择“管理聚合” 。
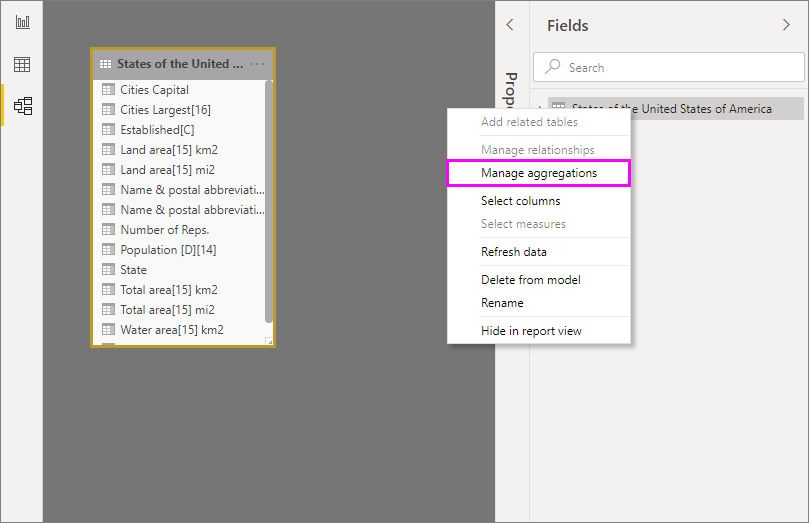
“管理聚合”对话框为表中的每一列显示一行,可在其中指定聚合行为 。 在下面的示例中,对“Sales”详细信息表的查询会在内部重定向到“Sales Agg”聚合表 。
“管理聚合”对话框中的“汇总”下拉菜单提供以下值 :
Count
GroupBy
Max
Min
总和
计算表行数
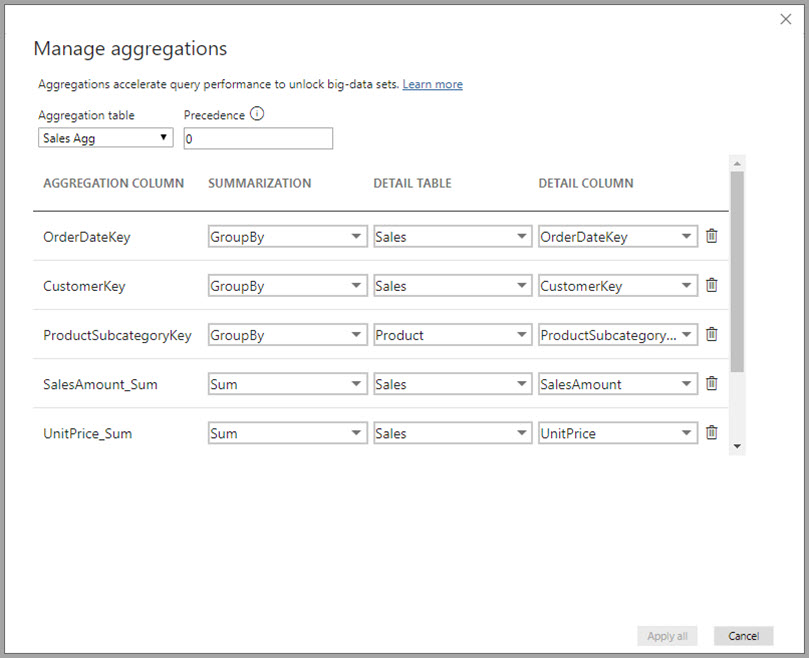
在此基于关系的聚合示例中,GroupBy 条目是可选的。 除 DISTINCTCOUNT 外,它们不影响聚合行为,并且主要用于提高可读性。 如果不使用 GroupBy 条目,聚合仍可根据关系命中。 这与本文后面介绍的大数据示例不同,在该示例中,需要 GroupBy 条目。
定义所需的聚合后,选择“全部应用” 。
验证
“管理聚合”对话框强制实施以下重要验证 :
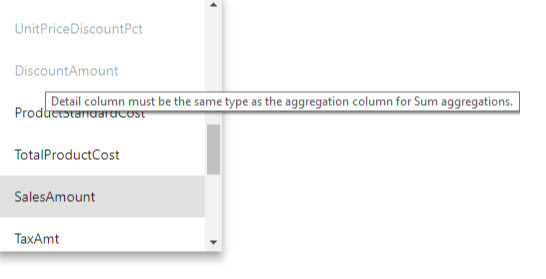
“详细信息列”的数据类型必须与“聚合列”相同,“计数”和“计算表行数”汇总函数除外 。 “计数”和“计算表行数”仅用于整数聚合列,且无需匹配的数据类型。
不允许使用涉及三个(及以上)表的链式聚合。 例如,表 A 上的聚合不能引用具有引用表 C 的聚合的表 B。
不允许使用重复聚合,重复聚合是指两个条目使用相同的汇总函数并引用相同的“详细信息表”和“详细信息列” 。
“详细信息表”必须使用 DirectQuery 存储模式,而不是 Import 存储模式 。
不支持通过非活动关系所用的外键列进行分组以及依赖 USERELATIONSHIP 函数进行聚合命中。
大多数验证可通过禁用下拉值并在工具提示中显示解释性文本强制实施,如下图所示。
 31.5516
31.5516
 1
1
 0
0

 关注作者
关注作者
 收藏
收藏

评论(0)
 发表评论
发表评论
暂无数据







推荐帖子

大妮tbdt
2024-10-08
0条评论
大妮tbdt
2024-10-08
1条评论

nigel
2023-07-14
0条评论