


2020-10-30
阅读量:
2311
大数据分析之红楼梦是两个人写的吗?
大数据分析案例根据行业的不同也有不同,由于楼主没有明确哪个行业所以无法针对性回答。在此分享一个文学方面的大数据分析案例,仅做参考!
《红楼梦》的作者前八十回和后四十回到底是不是同一个作者?我们都在读书的时候学过《红楼梦》的作者有两个!曹雪芹写了前八十回,高鹗续写了后四十回。然而,红学上关于《红楼梦》的作者争议一直很大,存在着很多种版本。
清代著名《红楼梦》评论家张新之指出,《红楼梦》80回前后在思想、结构上、人物性格发展上都具有高度的一致性,他在《红楼梦读法》中写道:“一部《石头记》,计百二十回,沥沥洋洋,可谓繁矣,而实无一句闲文。有谓此书只八十回,其余四十回乃出另手,吾不能知。但观其中结构,如常山蛇,首尾相应,安根伏线,有牵一发浑身动摇之妙,且此句笔气,前后略无差别——重以父兄命,万金赠,使闲人增半回,不能也。何以耳为目,随声附和者之多?”
我们使用大数据语义智能技术对《红楼梦》进行了分析:
首先将《红楼梦》一百二十回按顺序均分为三、六、十二等份,将其命名为“三组”、“六组”、“十二组”。将各组作为语料源,使用大数据分析工具分别进行批量分词的分析操作。然后统计出文言虚词的词频。最后对不同组数据之间进行KL距离计算。(注:KL距离(相对熵)可以衡量两个随机分布之间的距离,当两个随机分布相同时,它们的相对熵为零,当两个随机分布的差别增大时,它们的相对熵也会增大。所以相对熵(KL散度)可以用于比较文本的相似度。其公式为
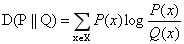
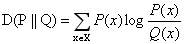
)
接下来以“三组”为例详细介绍,“六组”与“十二组”等同。将一百二十回按顺序均分为三等份即第1回-第40回、第41回-第80回、第81-第120回。统计出四十七个虚字在每组的词频及概率。“三组”数据中部分虚词以及该词的概率如表1所示,其中概率值得计算为本组数据中某个虚词的个数与本组数据虚词的总数的比值。
根据KL计算公式将表2中的行所在回数的各个虚词的概率值记为P(x),将表2中列所在回数的各个虚词的概率值记为Q(x)。其它组实验等同。例如计算第1回-第40回与第41回-第80回的KL值时,公式中的x表示某个虚词,P(x)表示x在第1回-第40回中的概率。Q(x)表示x在第41回-第80回中的概率。需要注意的是D(P||Q)与D(Q||P)不同。
表1 各个虚词在各组的频率及概率
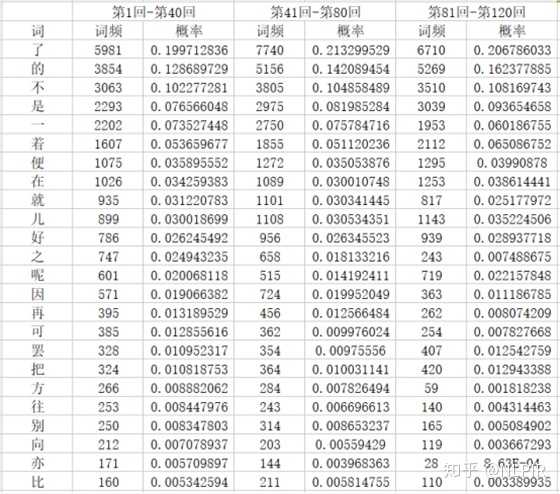
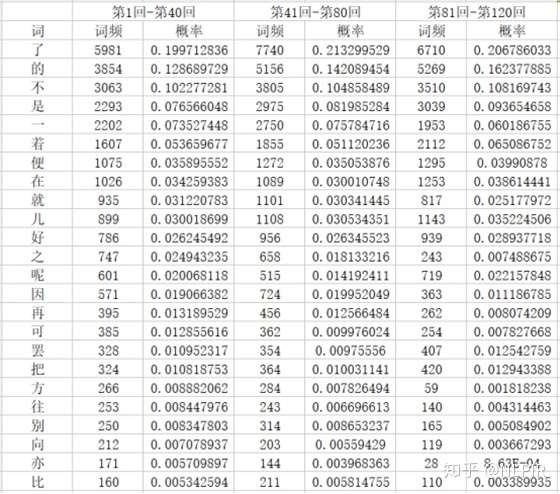
这3组数据的KL值结果如表2所示。从表中可以观察到第一行中1-40与81-120的KL值是1-40与41-80的KL值的十倍。由于当两个随机分布的差别增大时,它们的相对熵也会增大。所以1-40与81-120的相似性比1-40与41-80低。
表2 “三组”数据结果
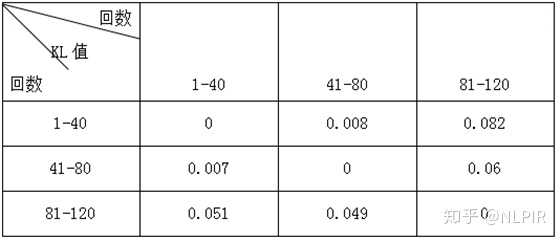
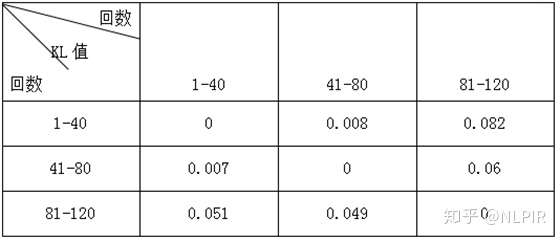
表2对应的直观图如图1,可以观察到第1回-第40回与第41回-第80回的相似性较大,第1回-第40回和第41回-第80回与第81-第120回的相似性出现明显变化。
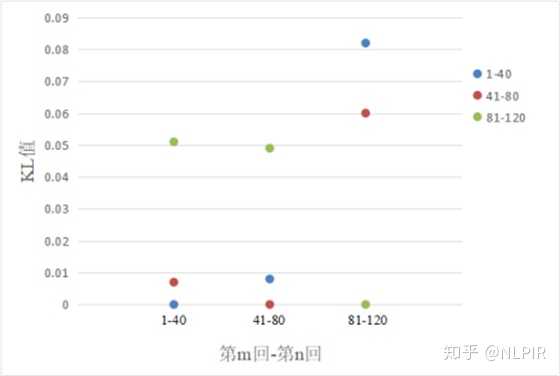
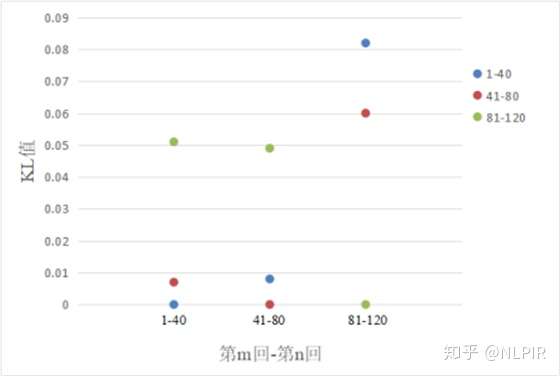
图1 “三组”数据结果
“六组”将120回按顺序均分为六等份即第1回-第20回、第21回-第40回、第41-第80回、第81回-第100回、第101-第1200回。
这6组数据的结果如表3所示。对应直观图如图2所示。
表3 “六组”数据结果
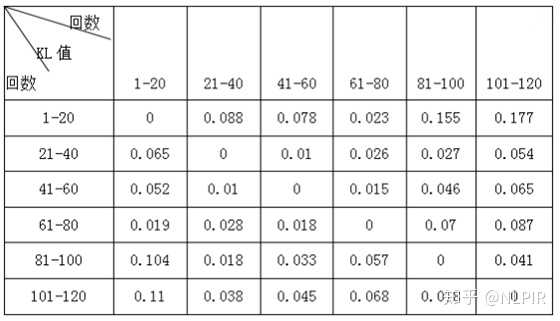
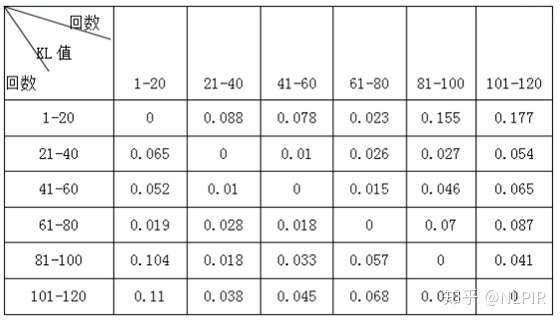
根据当两个随机分布的差别增大时,它们的KL值也会增大。发现前四等份在跟后两等份进行比较时KL值会明显增加。同时后两等份在跟前四等份进行比较时KL值会明显降低。
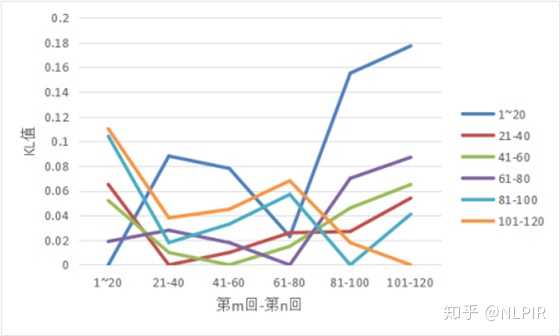
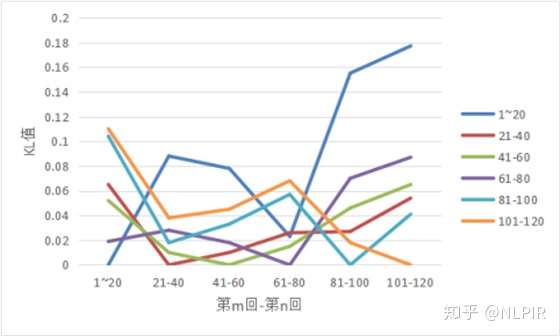
图2 “六组”数据结果
“十二组”将120回按顺序均分为十二等份即第1回-第10回、第11回-第20回、第21-第30回... ...第111-第1200回。这12组数据的结果如表4所示。
表4 “十二组”数据结果
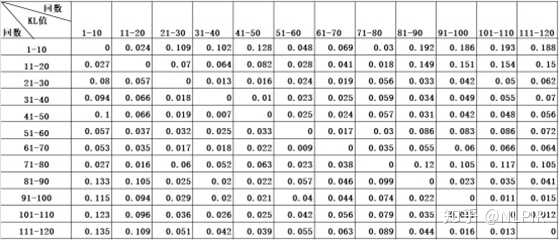
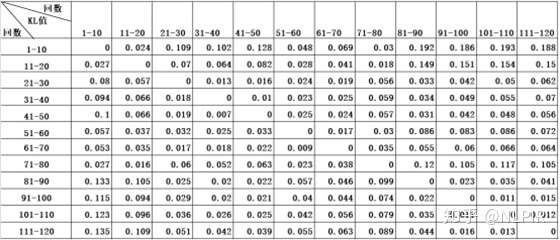
从表4中可以观察到前八十回中的任意一组数据在与一百二十回的其他组比较时,与后四十回的各组数据的KL值比与前八十回其他组数据的KL值高。当两个随机分布的差别增大时,它们的KL值也会增大。
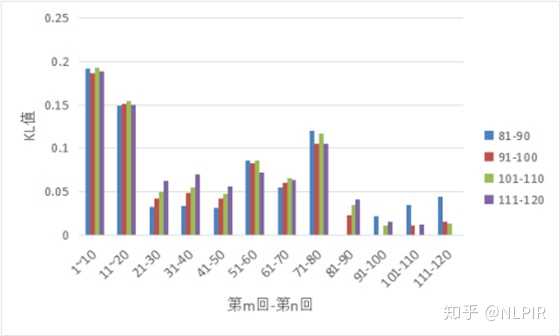
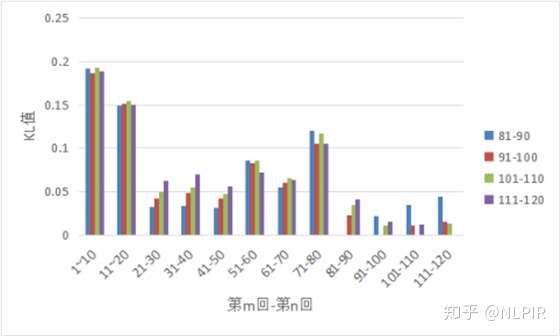
图3各组与后四十回均分的4组数据的对比
图3为一百二十回与后四十回均分的4组数据的对比图。可以看出前八十回的各组数据的KL值与后四十回的数据的KL值有不同程度的差距。后四十回之间的KL值比其他组得KL值要小,说明后四十回的相似度较高。
经过一系列的分析,前八十回与后四十回确实在用词习惯上有明显的区别。可以大胆猜测后四十回是出自于另外一个人。
以上是分享的大数据分析案例,其他行业的案例由于文章篇幅不做累述,本案例使用北京理工大学大数据搜索与挖掘实验室张华平主任研发的NLPIR大数据语义智能分析技术进行数据分析,其他行业数据分析也可以使用相同方法可行行业数据挖掘和分析。
 0.0151
0.0151
 2
2
 0
0

 关注作者
关注作者
 收藏
收藏

评论(0)
 发表评论
发表评论
暂无数据







推荐帖子
CDA助教老师
2024-10-15
0条评论
CDA助教老师
2024-04-17
1条评论
CDA138749
2024-04-01
0条评论