Pandas是一款很强大的Python库,具有很多方便的功能,今天小编就给大家分享用Pandas修改样式。
以下内容转载于早起Python微信公众号。
作者:刘早起
文章来源:早起Python
前言
在之前的很多文章中我们都说过,Pandas与openpyxl有一个很大的区别就是openpyxl可以进行丰富的样式调整,但其实在Pandas中每一个DataFrame都有一个Style属性,我们可以通过修改该属性来给数据添加一些基本的样式。
使用说明
我们可以编写样式函数,并使用CSS来控制不同的样式效果,通过修改Styler对象的属性,将样式传递给DataFrame,主要有两种传递方式
Styler.applymap:逐元素
Styler.apply:列/行/表方式
Styler.applymap通过DataFrame逐个元素地工作。Styler.apply根据axis参数,按列使用axis=0.按行使用axis=1.以及axis=None作用于整个表。所以若使用Styler.applymap,我们的函数应返回带有CSS属性-值对的单个字符串。若使用Styler.apply,我们的函数应返回具有相同形状的Series或DataFrame,其中每个值都是具有CSS属性值对的字符串。
不会CSS?没关系,作为调包侠的我们大多是改改HTML颜色代码即可完成样式修改,下面看一些示例。
一些例子
基本样式
首先我们创建一组没有任何样式的数据
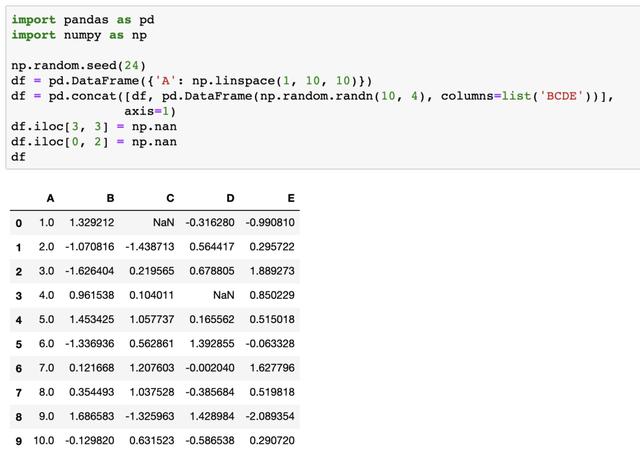
我们之前说过,DataFrame是有style属性的,所以在没有做任何修改的情况下,使用df.style应该和上图一样
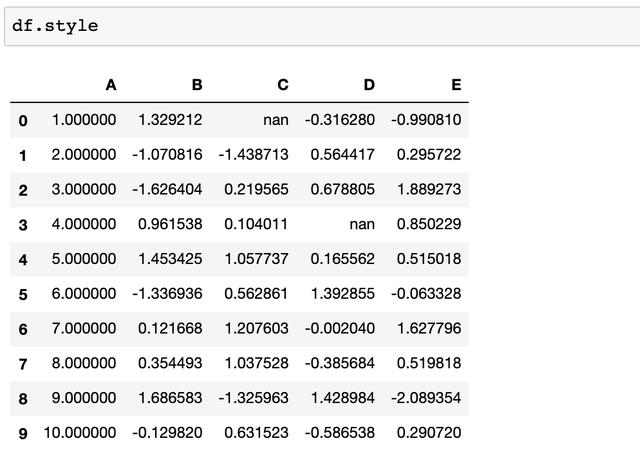
现在让我们编写一个简单的样式函数,该函数可以将负数变为红色,使正数保持黑色。
def color_negative_red(val):
color = 'red' if val < 0 else 'black'
return 'color: %s' % color
现在来应用这段函数(思考Excel如何实现)
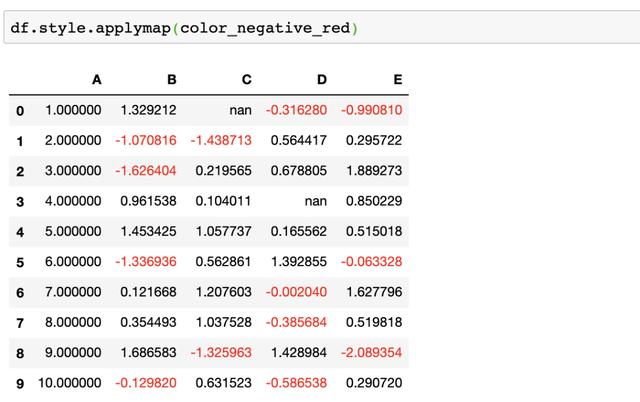
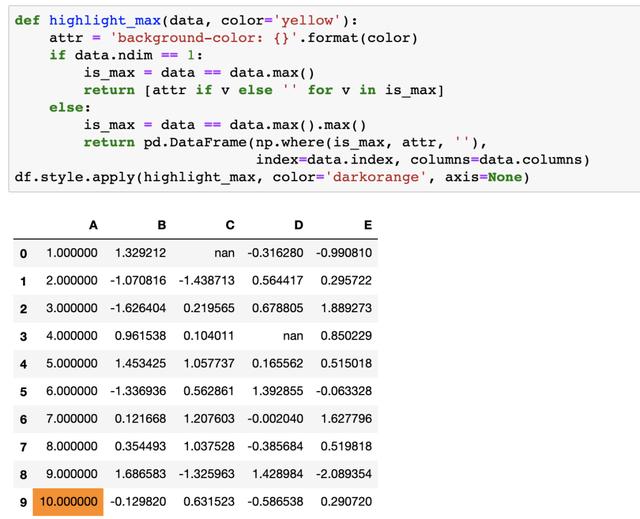
现在如果我们想突出显示每列中的最大值,需要重新定义一个函数
def highlight_max(s):
is_max = s == s.max()
return ['background-color: yellow' if v else '' for v in is_max]
因为之前我们是以元素为单位判断,所以使用的是.applymap,所以现在我们应对列进行.apply操作
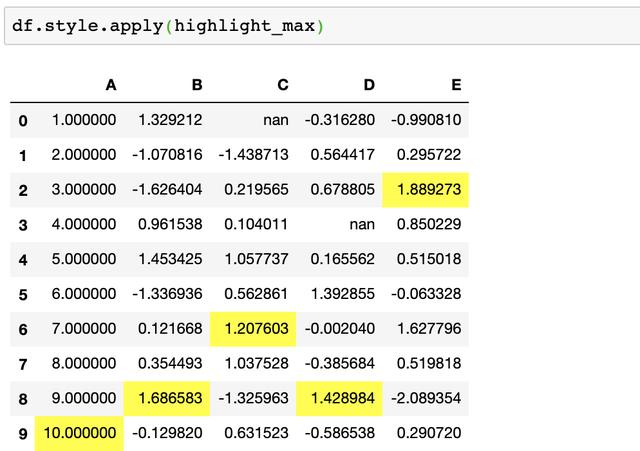
现在可以使用
df.style.applymap(color_negative_red).apply(highlight_max)
来混合修改样式或使用.\实现
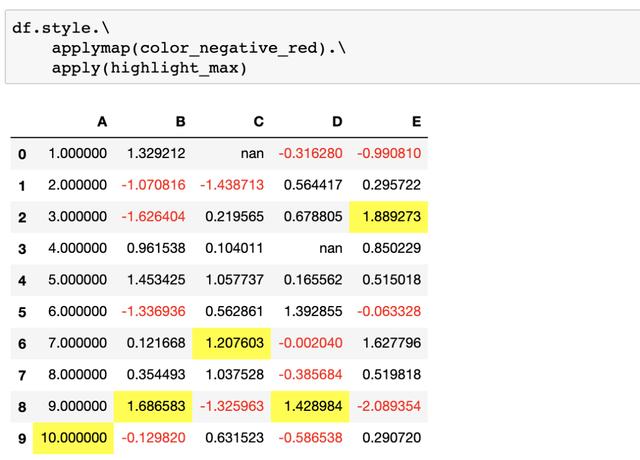
当然我们也可以通过修改样式函数并使用.apply来高亮整个DataFrame的最大值,
切片
当然我们也可以使用subset通过切片来完成对指定列进行样式修改,比如高亮部分列的最大值
df.style.apply(highlight_max, subset=['B', 'C', 'D'])
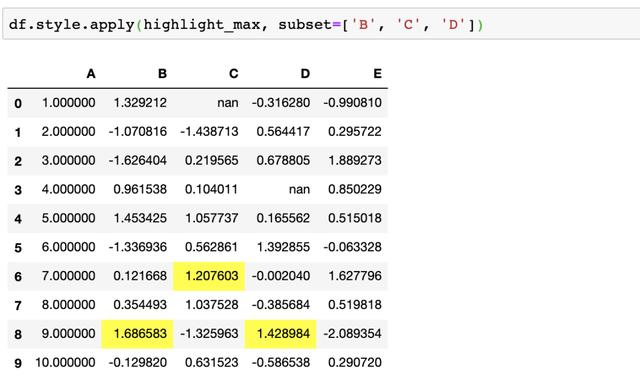
对于行和列切片,可以使用我们熟悉的.loc,不过目前仅支持基于标签的切片,不支持位置切片。
格式化输出
我们也可以使用Styler.format来快速格式化输出,比如将小数格式化为百分数
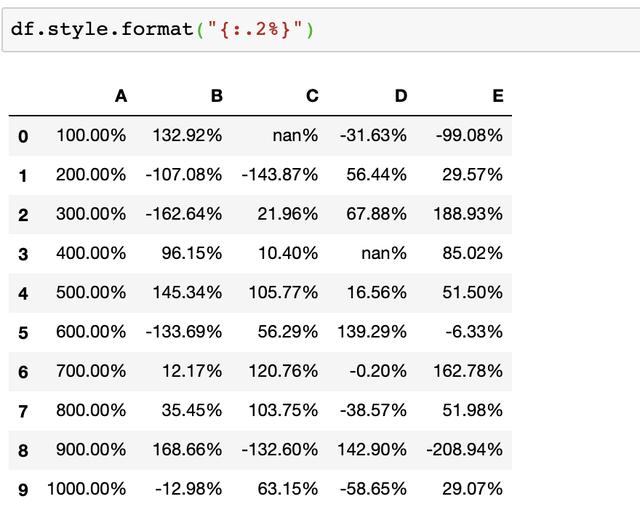
也支持使用字典或lambda表达式来更灵活的使用
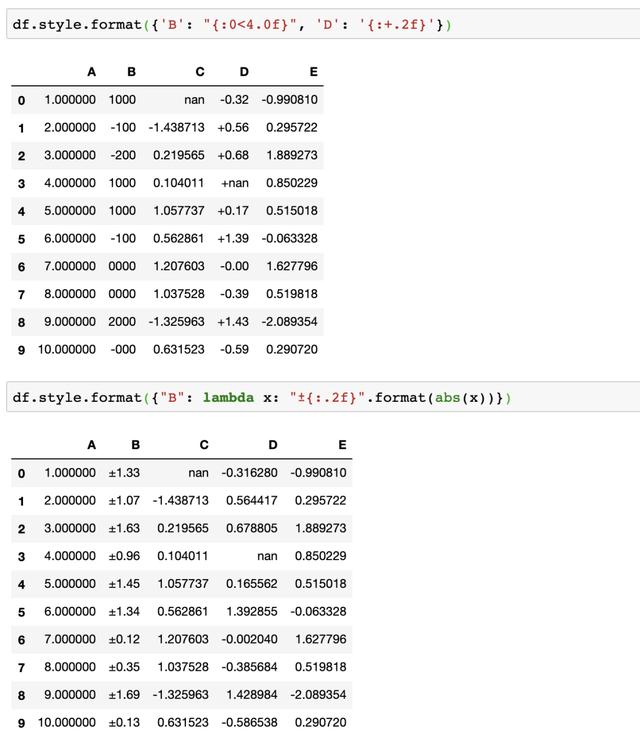
当然是支持和之前的样式结合使用
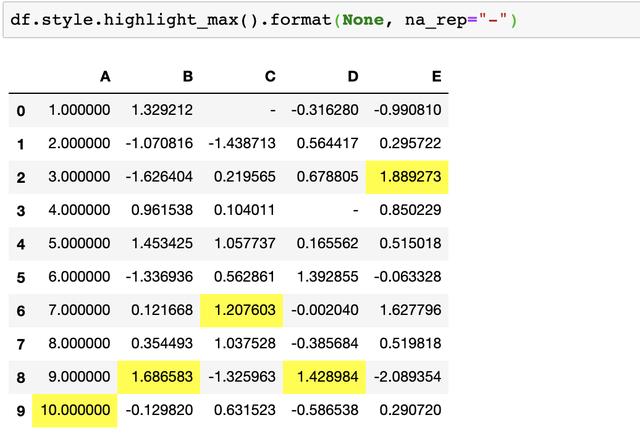
内置样式
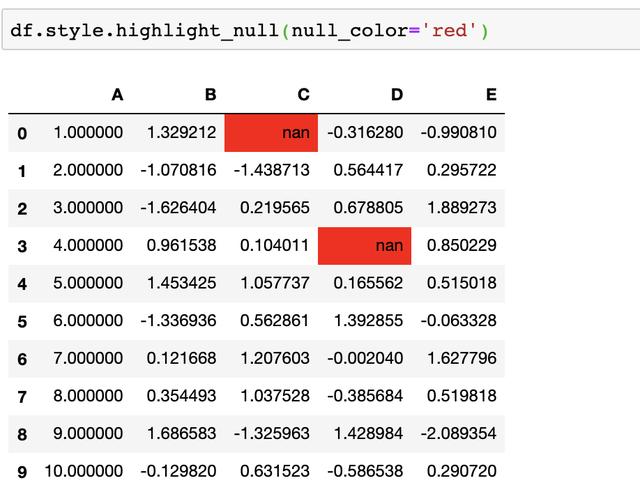
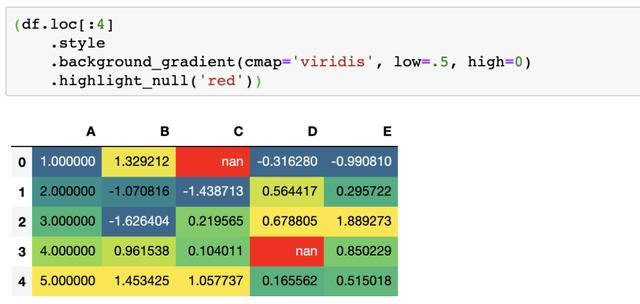
开发者们为了尽可能的让作为调包侠的我们使用起来更方便,已经内置了很多写好的样式,拿走就用,比如将空值设置为红色
或是结合seaborn使用热力图
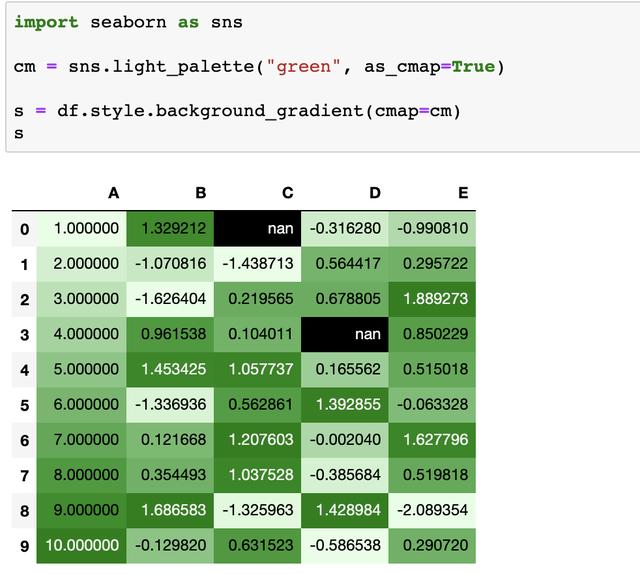
现在我们就可以通过修改Styler.background_gradient来轻松的修改颜色等样式
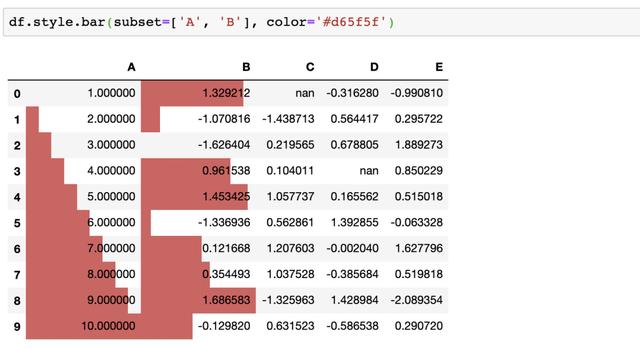
最后我们可以将数据修改为条形图的样式,这也是我最喜欢的一个功能,能够快速的看出数据的变化!
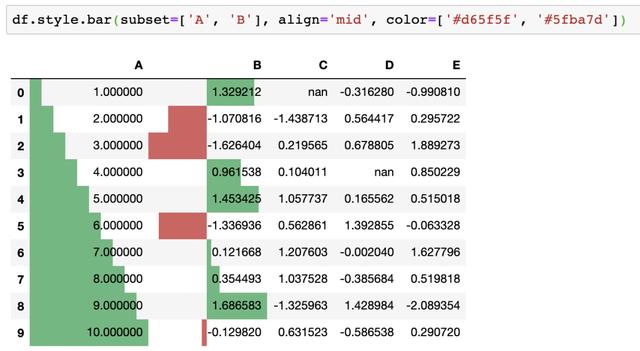
在最新的版本中可以进一步自定义条形图:我们现在可以将df.style.bar以零或中点值为中心来快速观察数据变化,并可以传递颜色[color_negative, color_positive],比如使用align='mid':
以上就是对Pandas中如何修改样式的一个简单介绍,更多的操作可以在官方文档https://pandas.pydata.org/pandas-docs/stable/user_guide/style.html中找到与学习。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330