今天小编给大家带来的是现在非常火爆的机器学习方法——集成学习。集成学习,顾名思义,通过将多个单个学习器集成/组合在一起,使它们共同完成学习任务,有时也被称为“多分类器系统(multi-classifier system)”、基于委员会的学习(Committee-based learning)。
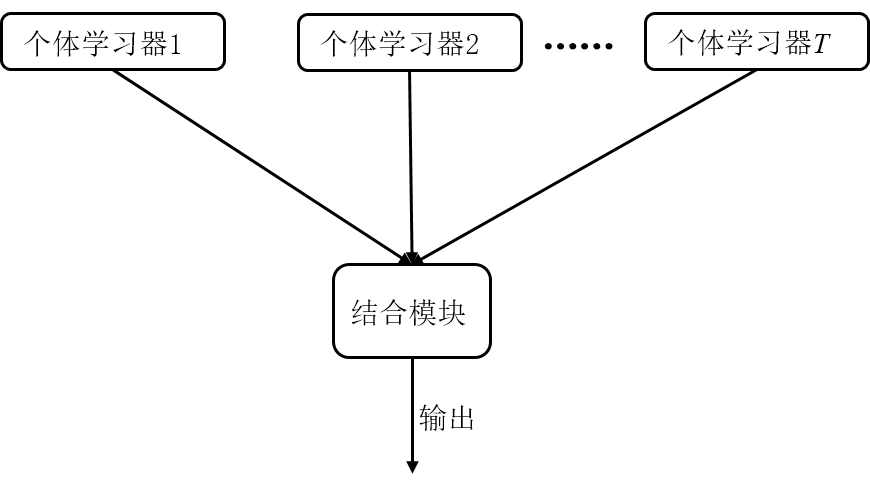
它本身不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务。也就是我们常说的“博采众长”。集成学习可以用于分类问题集成,回归问题集成,特征选取集成,异常点检测集成等等,可以说所有的机器学习领域都可以看到集成学习的身影。
一般集成学习会通过重采样获得一定数量的样本,然后训练多个弱学习器(分类精度稍大于50%),采用投票法,即“少数服从多数”原则来选择分类结果,当少数学习器出现错误时,也可以通过多数学习器来纠正结果。
集成学习分类
目前根据个体学习器的生成方式,集成学习可以分为两大类:
1)个体学习器之间存在较强的依赖性,必须串行生成的序列化方法:boosting类算法;
Boosting是一簇可将弱学习器提升为强学习器的算法。其工作机制为:先从初始训练集训练出一个基学习器,再根据基学习器的表现对样本分布进行调整,使得先前的基学习器做错的训练样本在后续收到更多的关注,然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器数目达到实现指定的值T,或整个集成结果达到退出条件,然后将这些学习器进行加权结合。
2)个体学习器之间不存在强依赖关系,可以并行生成学习器:bagging和随机森林
Bagging的算法原理和 boosting不同,它的弱学习器之间没有依赖关系,可以并行生成。
Bagging的基本流程:
1.经过T轮自助采样,可以得到T个包含m个训练样本的采样集。
2.然后基于每个采样集训练出一个基学习器。
3.最后将这T个基学习器进行组合,得到集成模型。
随机森林(Random Forest,简称RF) 是Bagging的一个扩展变体。
随机森林对Bagging做了小改动:
1.Bagging中基学习器的“多样性”来自于样本扰动。样本扰动来自于对初始训练集的随机采样。
2.随机森林中的基学习器的多样性不仅来自样本扰动,还来自属性扰动。
3.这就是使得最终集成的泛化性能可以通过个体学习器之间差异度的增加而进一步提升。
4.随机森林在以决策树为基学习器构建Bagging集成模型的基础上,进一步在决策树的训练过程中引入了随机属性选择。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330