以下的文章内容来源于张彦存老师的专栏,如果您想阅读专栏《Python 数据可视化 18 讲(PyEcharts、Matplotlib、Seaborn)》,点击下方链接
https://edu.cda.cn/goods/show/3842?targetId=6751&preview=0
一、帕累托分析原理与应用
1.1 核心原理
帕累托分析(Pareto Analysis)源于经济学家维尔弗雷多·帕累托提出的"二八法则",其核心原理是通过识别导致80%结果的20%关键因素,帮助决策者聚焦资源解决主要矛盾。
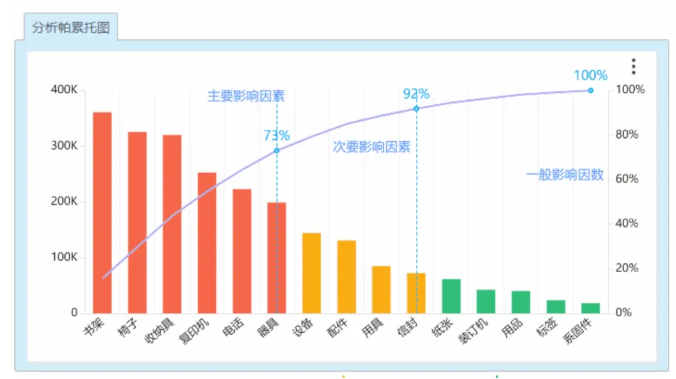
具体实施步骤包含:
- 识别关键因素(通常为累计占比70-80%的前端因素)
1.2 典型应用场景
在管理和质量控制领域,帕累托分析(Pareto Analysis)是一种决策工具,用于识别少数重要因素对总体影响的程度。除此之外还可以有如下应用:
- 故障排查:锁定高频故障点
今天我们基于简单的实验数据,使用Python中的Pyecharts库来开发一个帕累托分析图

使用前需安装,代码运行的pyecharts版本是2.0.5
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyecharts==2.0.5
2.1 环境配置与数据准备
首先,我们需要导入Pyecharts中的Bar和Line图表类,以及options类,用于实现对各个图标的配置,此外如果代码需要在jupyter notebook中展示图形还需要从globals中导入CurrentConfig, NotebookType做执行环境的配置,对于新版本的jupyter notebook统一设置为NotebookType.JUPYTER_LAB。
from pyecharts.charts import Bar, Line
from pyecharts import options as opts
categories = ["产品质量问题", "送货延迟", "客户服务不满", "价格不公", "其他"]
counts = [40, 30, 20, 5, 5]
技术细节说明:
2.2 核心计算逻辑
total_counts = sum(counts)
cumulative_percents = [sum(counts[:i+1])/total_counts for i in range(len(counts))]
计算过程解析:
- 列表推导式逐项累加:40/100=0.4 → (40+30)/100=0.7 → ... → 1.0
- 输出结果:[0.4, 0.7, 0.9, 0.95, 1.0]
2.3 可视化组件构建
(1) 柱状图初始化
bar = (
Bar()
.add_xaxis(categories)
.add_yaxis("投诉次数", counts)
.set_global_opts(
title_opts=opts.TitleOpts(title="帕累托分析图"),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross")
)
)
bar.render_notebook()

关键技术点:
(2) 折线图构建
line = (
Line()
.add_xaxis(categories)
.add_yaxis(
"累计百分比",
cumulative_percents,
linestyle_opts=opts.LineStyleOpts(color="red", width=4),
label_opts=opts.LabelOpts(is_show=True, color="red")
)
)
line.render_notebook()
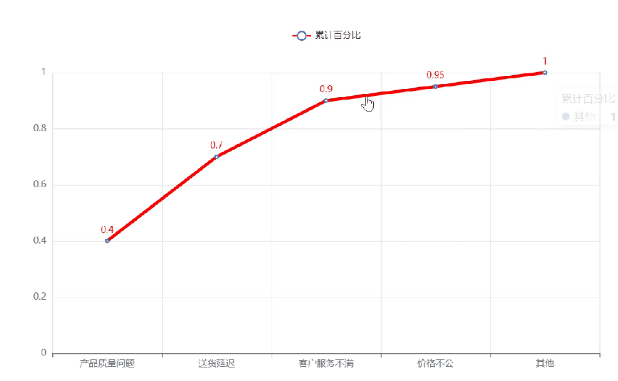
视觉优化设计:
2.4 图表合成与优化
帕累托图需将以上两张图组合在一起,可以使用overlap实现
bar.overlap(line)
bar.render_notebook()
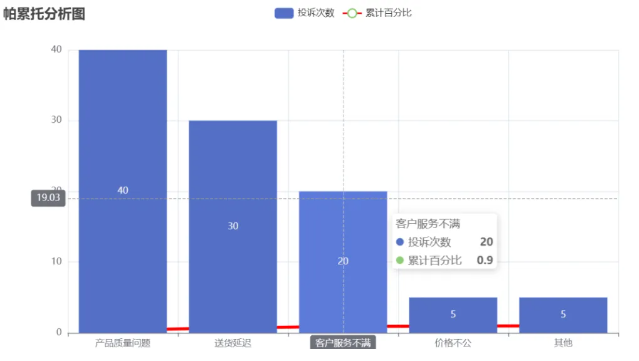
可以看到图形很奇怪,因为折线图对应的数据与柱形图对应的数据量纲相差很大。那如何优化?
bar = (
Bar()
.add_xaxis(categories)
.add_yaxis("投诉次数", counts, yaxis_index=0)
.extend_axis(
yaxis=opts.AxisOpts(
type_="value",
name="累计百分比",
min_=0.3,
max_=1.1,
interval=0.2
)
)
.set_global_opts(
title_opts=opts.TitleOpts(title="帕累托分析图"),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross")
)
)
line = (
Line()
.add_xaxis(categories)
.add_yaxis(
"累计百分比",
cumulative_percents,
yaxis_index=1,
linestyle_opts=opts.LineStyleOpts(color="red", width=4),
label_opts=opts.LabelOpts(is_show=True, color="red")
)
)
bar.overlap(line)
bar.options["series"][1]["z"] = 1
bar.options["series"][0]["z"] = 0
bar.render_notebook()
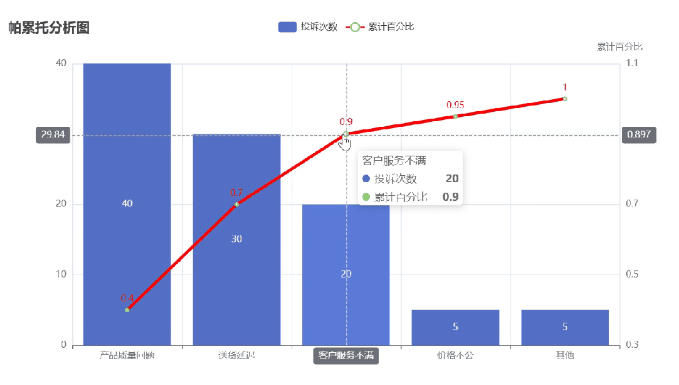
深度优化说明:
- extend_axis创建次坐标轴,范围设置为30%-110%以留出视觉缓冲
2.5 输出与展示
bar.render_notebook()
多环境支持:
- Jupyter环境使用render_notebook()
三、实现效果与业务解读
3.1 生成图表分析
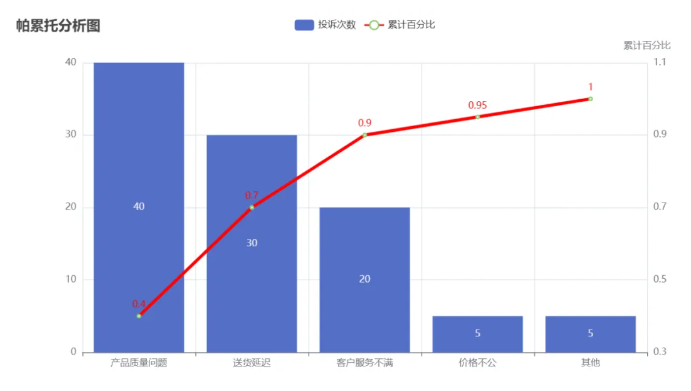 帕累托分析效果图
帕累托分析效果图
3.2 生产环境扩展建议
大家如果觉得自己的可视化技能训练的不错了,可以实操起来。
四、完整代码汇总
本实现方案通过Pyecharts高效构建了交互式帕累托分析图表,将技术实现与业务分析有机结合,为决策者提供直观的数据支持。开发者可根据具体业务需求扩展功能模块,构建完整的决策分析系统。绘制帕累托的流程相对固定,因此这些代码也可以封装为函数方便后续的复用。
def get_plt(categories,counts):
import pandas as pd
df = pd.DataFrame({"categories":categories,"counts":counts})
categories = list(df.sort_values("counts")["categories"])
counts = list(df.sort_values("counts")["counts"])
from pyecharts.charts import Bar, Line
from pyecharts import options as opts
bar = (
Bar()
.add_xaxis(categories)
.add_yaxis("投诉次数", counts, yaxis_index=0)
.extend_axis(
yaxis=opts.AxisOpts(
type_="value",
name="累计百分比",
min_=0.3,
max_=1.1,
interval=0.2
)
)
.set_global_opts(
title_opts=opts.TitleOpts(title="帕累托分析图"),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross")
)
)
line = (
Line()
.add_xaxis(categories)
.add_yaxis(
"累计百分比",
cumulative_percents,
yaxis_index=1,
linestyle_opts=opts.LineStyleOpts(color="red", width=4),
label_opts=opts.LabelOpts(is_show=True, color="red")
)
)
bar.overlap(line)
bar.options["series"][1]["z"] = 1
bar.options["series"][0]["z"] = 0
return bar
以上的文章内容来源于张彦存老师的专栏,如果您想阅读专栏《Python 数据可视化 18 讲(PyEcharts、Matplotlib、Seaborn)》,点击下方链接
https://edu.cda.cn/goods/show/3842?targetId=6751&preview=0











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330