来源:早起Python
作者:陈熹
一、需求描述
大家好,我是早起。
在之前的文章 批量翻译文档 中,我们介绍了如何调用百度翻译API完成实际的文档翻译需求。如果是科研、深度学习等需要经常阅读大量论文的工作,批量翻译就能大大提高效率。
本文将进一步使用 Python 实现另一个在科研学术领域的办公自动化应用。「结合爬虫批量翻译文献题目和摘要,并存储搜索和翻译结果至 Excel中」
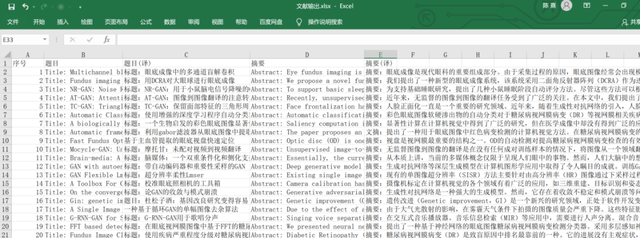
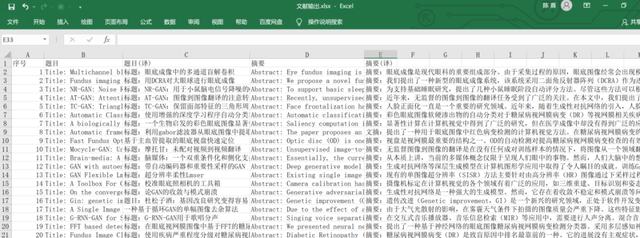
完成效果如下,指定的外文文献标题、摘要都被批量翻译后存储在Excel中,我们可以大致浏览后有选择性的挑选文章阅读!
本文以ACM协会的文献为例,搜索的关键词是 “对抗生成网络+眼底” ,即 “GAN+fundus”
二、逻辑梳理
本文需求可以看做三块内容:爬虫+翻译+存储 在使用百度的通用翻译 API 之前需要完成以下工作:
“使用百度账号登录百度翻译开放平台(
http://api.fanyi.baidu.com)注册成为开发者,获得APPID;进行开发者认证(如仅需标准版可跳过);开通通用翻译API服务:开通链接参考技术文档和Demo编写代码”
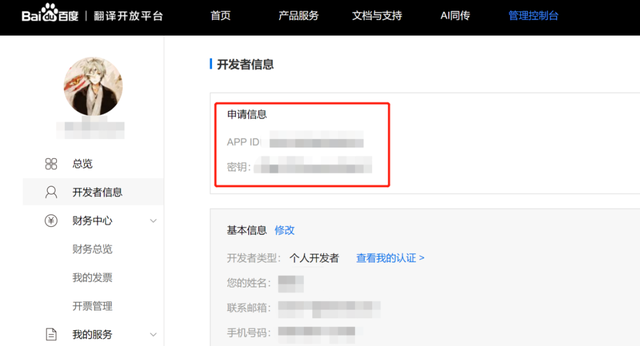
完成后在个人页面在即可看到 ID 和密钥,这个很重要!
关于如何使用Python爬取翻译结果的细节本文就不再赘述!我已经将通用翻译 API 的 demo代码写好,已经对输出做简单修改,拿走就能用!
import requests import random import json from hashlib import md5 appid = 'xxx' appkey = 'xxx' from_lang = 'en' to_lang = 'zh' endpoint = 'http://api.fanyi.baidu.com' path = '/api/trans/vip/translate' url = endpoint + path
query = 'Hello World! This is 1st paragraph.nThis is 2nd paragraph.' def make_md5(s, encoding='utf-8'): return md5(s.encode(encoding)).hexdigest()
salt = random.randint(32768, 65536)
sign = make_md5(appid + query + str(salt) + appkey) headers = {'Content-Type': 'application/x-www-form-urlencoded'}
payload = {'appid': appid, 'q': query, 'from': from_lang, 'to': to_lang, 'salt': salt, 'sign': sign} r = requests.post(url, params=payload, headers=headers)
result = r.json() for res in result['trans_result']:
print(res['dst'])
在本需求中可以考虑将上面的API重新包装成函数,将爬取的题目和摘要看做两个文本输入函数后,返回翻译的结果:
import requests import random import json from hashlib import md5 def make_md5(s, encoding='utf-8'): return md5(s.encode(encoding)).hexdigest() def Baidu_translate(query): appid = 'xxx' appkey = 'xxx' from_lang = 'en' to_lang = 'zh' endpoint = 'http://api.fanyi.baidu.com' path = '/api/trans/vip/translate' url = endpoint + path
try:
salt = random.randint(32768, 65536)
sign = make_md5(appid + query + str(salt) + appkey)
headers_new = {'Content-Type': 'application/x-www-form-urlencoded'}
payload = {'appid': appid, 'q': query, 'from': from_lang, 'to': to_lang, 'salt': salt, 'sign': sign}
r = requests.post(url, params=payload, headers=headers_new)
result = r.json()['trans_result'][0]['dst']
return result
except:
return '翻译出错'
函数中用 try 捕获错误避免中途因为提交的文本为空,而导致的报错终止程序
存储部分,通过 openpyxl 或者 xlwings 存储到 Excel 中就可以
爬虫部分,两个网站的逻辑非常类似,具体见下文
三、代码实现
首先爬取ACM的摘要,在首页搜索框中输入:GAN+fundus 跳转后可以发现,URL包含了关键词:
那么后面的搜索就可以直接用URL拼接:
keyword = 'GAN+fundus' url_init = r'https://dl.acm.org/action/doSearch?AllField=' url =url_init + keyword
搜索结果非常多,本文爬取第一页文章的摘要为例,后续读者当关键词锁定的文献比较少或者想获取全部文献,可以自行寻找URL翻页逻辑
同时我们发现,摘要显示不全,确认源代码和ajax动态加载不包含完整摘要,因此可以考虑进入各文献的详情页获取摘要:
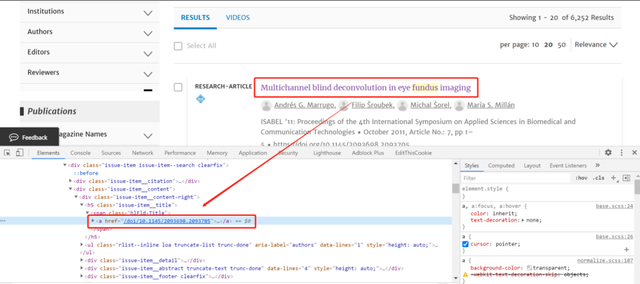
回到搜索结果页,对详情页分析可以发现每个文献可获取的href跟 dl.acm.org 拼接后即为详情页URL:
接下来就可以利用Xpath获取搜索页第一页全部文献的 href 并拼接成新URL:
import requests from lxml import html
keyword = 'GAN+fundus' url_init = r'https://dl.acm.org/action/doSearch?AllField=' url =url_init + keyword
html_data = requests.get(url).text
selector = html.fromstring(html_data)
articles = selector.xpath('//*[@id="pb-page-content"]/div/main/div[1]/div/div[2]/div/ul/li') for article in articles:
url_new = 'https://dl.acm.org' + article.xpath('div[2]/div[2]/div/h5/span/a/@href')[0]
print(url_new)
获得新的URL之后,重新用Xpath解析新的网页获取题目和摘要:
for article in articles:
url_new = 'https://dl.acm.org' + article.xpath('div[2]/div[2]/div/h5/span/a/@href')[0]
html_data_new = requests.get(url_new).text
selector_new = html.fromstring(html_data_new)
title = selector_new.xpath('//*[@id="pb-page-content"]/div/main/div[2]/article/div[1]/div[2]/div/div[2]/h1/text()')[0]
abstract = selector_new.xpath('//div[@class="abstractSection abstractInFull"]/p/text()')[0]
print('Title: ' + title)
print('Abstract: ' + abstract)
print('-' * 20)
题目和摘要可以成功输出,但现在还是英文形式。只需要将文本提交给上文中包装好的翻译函数,输出返回值就是中文翻译形式了。注意免费的API每秒只允许调用一次,可以考虑将题目和摘要组合成一个文本同时提交,或者中间休眠一秒:
for article in articles:
url_new = 'https://dl.acm.org' + article.xpath('div[2]/div[2]/div/h5/span/a/@href')[0]
html_data_new = requests.get(url_new).text
selector_new = html.fromstring(html_data_new)
title = selector_new.xpath('//*[@id="pb-page-content"]/div/main/div[2]/article/div[1]/div[2]/div/div[2]/h1/text()')[0]
abstract = selector_new.xpath('//div[@class="abstractSection abstractInFull"]/p/text()')[0]
title = 'Title: ' + title
translated_title = Baidu_translate(title)
print(title)
print(translated_title)
time.sleep(1)
abstract = 'Abstract: ' + abstract translated_abstract = Baidu_translate(abstract)
print(abstract)
print(translated_abstract)
time.sleep(1)
print('-' * 20)
题目和摘要成功翻译!接下来可以自定义对接意向的持久化存储了,以openpyxl为例,首先在代码的开头用 openpyxl 创建 Excel 文件并写入表头:
from openpyxl import Workbook
wb = Workbook()
sheet = wb.active
header = ['序号', '题目', '题目(译)', '摘要', '摘要(译)']
sheet.append(header)
path = 'xxx'
用变量 num 标记文章的顺序,并在每篇文章解析和翻译完后利用 sheet.append(list) 写入 Excel,循环结束后保存文件即完成全部存储:
num = 0 keyword = 'GAN+fundus' url_init = r'https://dl.acm.org/action/doSearch?AllField=' url =url_init + keyword
html_data = requests.get(url).text
selector = html.fromstring(html_data)
articles = selector.xpath('//*[@id="pb-page-content"]/div/main/div[1]/div/div[2]/div/ul/li') for article in articles:
num += 1 url_new = 'https://dl.acm.org' + article.xpath('div[2]/div[2]/div/h5/span/a/@href')[0]
html_data_new = requests.get(url_new).text
selector_new = html.fromstring(html_data_new)
title = selector_new.xpath('//*[@id="pb-page-content"]/div/main/div[2]/article/div[1]/div[2]/div/div[2]/h1/text()')[0]
abstract = selector_new.xpath('//div[@class="abstractSection abstractInFull"]/p/text()')[0]
title = 'Title: ' + title
translated_title = Baidu_translate(title)
print(title)
print(translated_title)
time.sleep(1)
abstract = 'Abstract: ' + abstract
translated_abstract = Baidu_translate(abstract)
print(abstract)
print(translated_abstract)
time.sleep(1)
print('-' * 20)
sheet.append([num, title, translated_title, abstract, translated_abstract])
wb.save(path + r'文献输出.xlsx')
最终实现效果如下,可以看到指定的文章标题、摘要都被翻译提取出来,我们可以大致浏览后有选择的查阅文章。
另外还有一个重要的计算机协会,IEEE(https://ieeexplore.ieee.org/Xplore/home.jsp),网页信息爬取逻辑和ACM非常类似,不再赘述
小结
综合各种办公自动化技术,我们可以实现各式各样的办公或科研需求,扎实的技术是最重要的前提。
例如本文的需求,其实我们还可以通过 openpyxl 或者 xlwings 存储到 Excel 中,实际上还可以 python-docx 写入 Word 中,甚至从文献中获取图片,借助 python-pptx 写入 PPT 中。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;

















 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330