


2022-02-20
阅读量:
7040
Pandas中快速转换数据类型的10个技巧(推荐!!!)
目录:
将字符串/int转换为int/float
将浮点数转换为int
转换混合数据类型的列
处理缺失值
将货币列转换为浮点数
将布尔值转换为0/1
一次性转换多个数据列
读取CSV文件时定义数据类型
创建一个自定义函数来转换数据类型
astype()与to_numeric()的比较
(本文翻译自:https://towardsdatascience.com/converting-data-to-a-numeric-type-in-pandas-db9415caab0b)
为了更好理解,我们以下面的数据作为例子来演示!
import pandas as pd
import numpy as npdef load_df():
return pd.DataFrame({
'string_col': ['1','2','3','4'],
'int_col': [1,2,3,4],
'float_col': [1.1,1.2,1.3,4.7],
'mix_col': ['a', 2, 3, 4],
'missing_col': [1.0, 2, 3, np.nan],
'money_col': ['£1,000.00','£2,400.00','£2,400.00','£2,400.00'],
'boolean_col': [True, False, True, True],
'custom': ['Y', 'Y', 'N', 'N']
})df = load_df()

查看数据类型:

(查看具体某一列的数据类型)

(查看数据详情)

正文:
1.将字符串/int转换为int/float
df['string_col'] = df['string_col'].astype('int')
df['string_col'] = df['string_col'].astype('int32')
df['string_col'] = df['string_col'].astype('int64')
df['string_col'] = df['string_col'].astype('float')
df['string_col'] = df['string_col'].astype('float16')
df['string_col'] = df['string_col'].astype('float32'
2.将浮点数转换为int
df['float_col'] = df['float_col'].astype('int')

df['float_col'] = df['float_col'].round(0).astype('int')

3.转换混合数据类型的列
当运行astype('int')时,我们得到一个ValueError

错误显示是值'a'的问题,因为它不能被转换为整数。为了解决这个问题,我们可以使用Pandas to_numeric()函数,参数为 errors='coerce'
df['mix_col'] = pd.to_numeric(df['mix_col'],errors='coerce') df['mix_col'].dtypes

在某些情况下,如果不希望输出的是浮点数,而是整数(例如转换ID列)。我们可以调用astype('Int64')。注意它有一个大写的I,与Numpy的'int64'不同。这样做的目的是把Numpy的NaN改为Pandas的NA,这样就可以把它变成一个整数。
df['mix_col'] = pd.to_numeric(df['mix_col'], errors='coerce').astype('Int64')
df['mix_col'].dtypes
另外,我们可以用另一个值替换Numpy nan(例如用0替换NaN)并调用astype('int')
df['mix_col'] = pd.to_numeric(df['mix_col'], errors='coerce').fillna(0).astype('int')
df['mix_col'].dtypes
4.处理缺失值
在Pandas中,缺失值被赋予NaN值,即 "Not a Number "的缩写。由于技术原因,这些NaN值总是属于float64.

当把一个有缺失值的列转换为整数时,我们也会得到一个ValueError,因为NaN不能被转换为一个整数
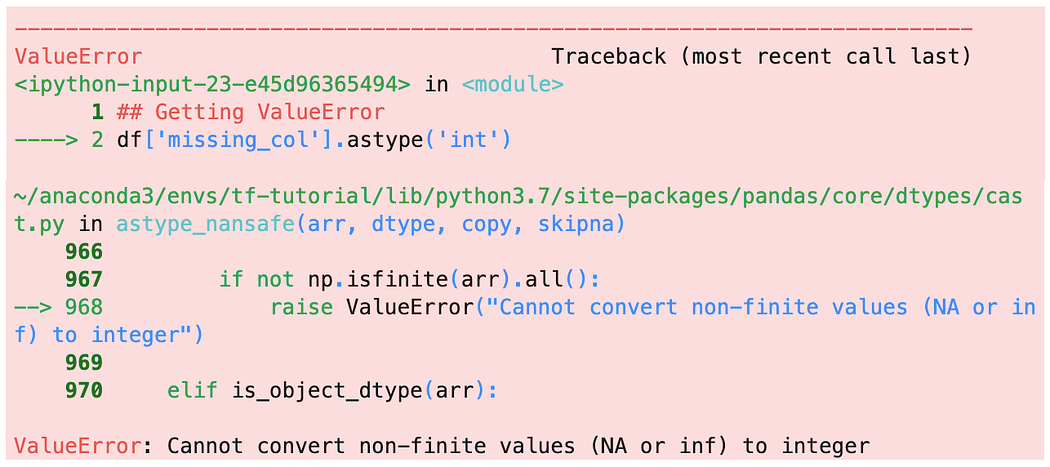
为了绕过这个错误,我们可以像上面那样调用astype('Int64')(注意它是大写的I),这样做的目的是将Numpy的NaN改为Pandas的NA,这样就可以成为一个整数。

另外,我们可以用另一个值替换Numpy的NaN(例如用0替换NaN),并调用astype('int')
df['missing_col'] = df['missing_col'].fillna(0).astype('int')
df.missing_col.dtypes
5.将货币列转换为浮点数
如果我们使用上面的方法,我们会得到所有的NaN或NA值,因为它们都是带有符号£和Ⅳ的字符串,它们不能被转换为数字。所以我们首先要做的是去除所有无效的符号,然后载转换数据类型。
df['money_replace'] = df['money_col'].str.replace('£', '').str.replace(',','')
df
df['money_replace'] = pd.to_numeric(df['money_replace'])
df['money_replace']
(我们也可以用正则表达式来替换这些符号)
df['money_regex'] = df['money_col'].str.replace('[\£\,]', '', regex=True)
df['money_regex'] = pd.to_numeric(df['money_replace'])
df['money_regex'](参数regex=True假定传入的模式是一个正则表达式)
6.将布尔值转换为0/1
使用场景:在建立一个机器学习模型,0/1是你的输入特征之一,需要它是数字的,用0和1来代表False和True,直接调用astype('int')即可
df['boolean_col'] = df['boolean_col'].astype('int')
df.boolean_col.dtypes
7.一次性转换多个数据列
DataFrame中astype()的方法,允许我们一次转换多个列的数据类型。当你有一堆你想改变的列时,它可以节省时间
df = df.astype({
'string_col': 'float16',
'int_col': 'float16'
})
df
df.string_col.dtypes
df.int_col.dtypes
8.读取CSV文件时定义数据类型
想在读取CSV文件时为每一列设置数据类型,你可以在用read_csv()加载数据时使用参数dtype
df = pd.read_csv(
'dataset.csv',
dtype={
'string_col': 'float16',
'int_col': 'float16'
}
)dtype参数接收一个字典,其中键代表列,值代表数据类型。这个方法和上面的区别是,这个方法在读取过程中进行转换,可以节省时间,而且更节省内存
9.创建一个自定义函数来转换数据类型
当数据的转换有点复杂时,我们可以创建一个自定义函数,并将其应用于每个值,以转换为适当的数据类型。
例如,money_col列,这里有一个我们可以使用的简单函数
def convert_money(value):
value = value.replace('£','').replace(',', '')
return float(value)
df['money_col'].apply(convert_money)我们也可以通过匿名函数来实现:
df['money_col'].apply(lambda v: v.replace('£','').replace(',','')).astype('float')

10.astype()与to_numeric()的比较
将数据类型从一个转换到另一个的最简单方法是使用astype()方法。Pandas DataFrame和Series都支持该方法。
如果你已经有一个数字数据类型(int8, int16, int32, int64, float16, float32, float64, float128和boolean),你也可以使用astype()来:
将其转换为另一种数字数据类型(int转为float,float转为int,等等)
用它来下调到一个较小的或上调到一个较大的字节大小
然而,astype()对混合类型的列不起作用。例如,mixed_col有a,missing_col有NaN。如果我们尝试使用astype(),我们会得到一个ValueError。
从Pandas 0.20.0开始,这个错误可以通过设置参数errors='ignore'来抑制,但是你的原始数据将被返回,不被触动。
Pandas to_numeric()函数可以更优雅地处理这些值。我们可以设置参数error='coerce',将无效的值强制为NaN
pd.to_numeric(df['mixed_col'], errors='coerce')
总结:astype()是最简单的方法,在转换方式上提供了更多的可能性,而to_numeric()在错误处理上有更强大的函数
 75.5484
75.5484
 7
7
 0
0

 关注作者
关注作者
 收藏
收藏

评论(0)
 发表评论
发表评论
暂无数据







推荐帖子
大傻叉1号
2024-10-08
0条评论
CDA139668
2024-04-17
0条评论
CDA助教老师
2023-10-23
0条评论