随机森林看起来是很好理解,但是要完全搞明白它的工作原理,需要很多机器学习方面相关的基础知识。
1)信息、熵以及信息增益的概念
这三个基本概念是决策树的根本,是决策树利用特征来分类时,确定特征选取顺序的依据。理解了它们,决策树你也就了解了大概。
对于机器学习中的决策树而言,如果带分类的事物集合可以划分为多个类别当中,则某个类(xi)的信息可以定义如下:
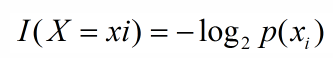
I(x)用来表示随机变量的信息,p(xi)指是当xi发生时的概率。
熵是用来度量不确定性的,当熵越大,X=xi的不确定性越大,反之越小。对于机器学习中的分类问题而言,熵越大即这个类别的不确定性更大,反之越小。
信息增益在决策树算法中是用来选择特征的指标,信息增益越大,则这个特征的选择性越好。
2)决策树
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。常见的决策树算法有C4.5、ID3和CART。
3)集成学习
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。
随机森林是集成学习的一个子类,它依靠于决策树的投票选择来决定最后的分类结果。你可以在这找到用python实现集成学习的文档:Scikit 学习文档。






 0
0




 发表评论
发表评论






