


2020-10-15
阅读量:
1962
数据清洗- Pandas 清洗“脏”数据(一)
准备工作
检查数据
处理缺失数据
添加默认值
删除不完整的行
删除不完整的列
规范化数据类型
必要的转换
重命名列名
保存结果
更多资源
准备工作
pip install pandas
#可以使用其他的别名, 但是,pd 是官方推荐的别名,也是大家习惯的别名import pandas as pd
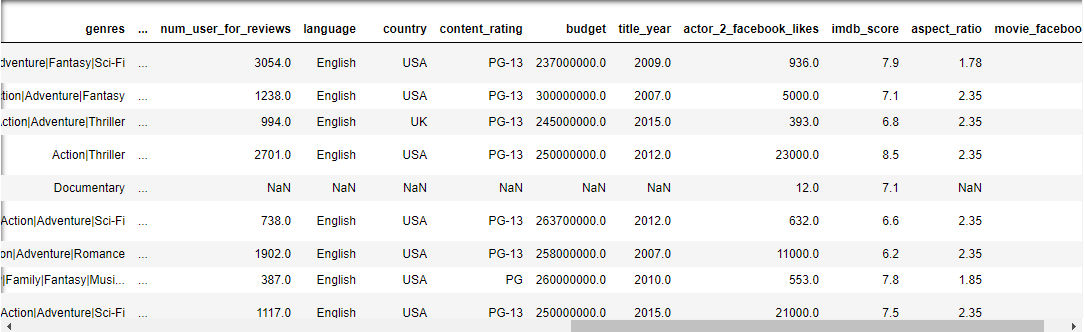
data = pd.read_csv('../data/tmdb_5000_credits.csv')
检查数据
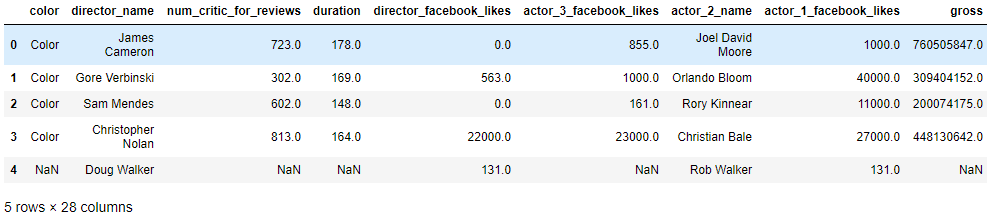
查看一列的一些基本统计信息:data.columnname.describe()
选择一列:data['columnname']
选择一列的前几行数据:data['columnsname'][:n]
选择多列:data[['column1','column2']]
Where 条件过滤:data[data['columnname'] >
condition]
处理缺失数据
从来没有填正确过
数据不可用
计算错误
为缺失数据赋值默认值
去掉/删除缺失数据行
去掉/删除缺失率高的列
添加默认值
data.country= data.country.fillna('')data.duration = data.duration.fillna(data.duration.mean())
删除不完整的行
data.dropna()
data.dropna(how='all')
data.drop(thresh=5)
data.dropna(subset=['title_year'])
删除不完整的列
data.drop(axis=1, how='all')
data.drop(axis=1. how='any')
规范化数据类型
data = pd.read_csv('../data/moive_metadata.csv', dtype={'duration': int})data = pd.read_csv('./data/moive_metadata.csv', dtype={'title_year':str})必要的变换
错别字
英文单词时大小写的不统一
输入了额外的空格
data['movie_title'].str.upper()
data['movie_title'].str.strip()
重命名列名
data,rename(columns = {‘title_year’:’release_date’, ‘movie_facebook_likes’:’facebook_likes’})data = data.rename(columns = {‘title_year’:’release_date’, ‘movie_facebook_likes’:’facebook_likes’})保存结果
data.to_csv(‘cleanfile.csv’ encoding=’utf-8’)
更多资源
用户环境的不同、
所使用语言的差异
用户输入的差别
概要
了解数据
分析数据问题
清洗数据
整合代码
了解数据
import pandas as pd
df = pd.read_csv('../data/patient_heart_rate.csv')
df.head()
分析数据问题
没有列头
一个列有多个参数
列数据的单位不统一
缺失值
空行
重复数据
非 ASCII 字符
有些列头应该是数据,而不应该是列名参数
清洗数据
import pandas as pd
# 增加列头
column_names= ['id', 'name', 'age', 'weight','m0006','m0612','m1218','f0006','f0612','f1218']
df = pd.read_csv('../data/patient_heart_rate.csv', names = column_names)
df.head()
# 切分名字,删除源数据列
df[['first_name','last_name']] = df['name'].str.split(expand=True)
df.drop('name', axis=1, inplace=True)
# 获取 weight 数据列中单位为 lbs 的数据
rows_with_lbs = df['weight'].str.contains('lbs').fillna(False)
df[rows_with_lbs]
# 将 lbs 的数据转换为 kgs 数据
for i,lbs_row in df[rows_with_lbs].iterrows():
weight = int(float(lbs_row['weight'][:-3])/2.2)
df.at[i,'weight'] = '{}kgs'.format(weight)
删:删除数据缺失的记录(数据清洗- Pandas 清洗“脏”数据(一)/[数据清洗]-Pandas 清洗“脏”数据(一))
赝品:使用合法的初始值替换,数值类型可以使用 0,字符串可以使用空字符串“”
均值:使用当前列的均值
高频:使用当前列出现频率最高的数据
源头优化:如果能够和数据收集团队进行沟通,就共同排查问题,寻找解决方案。
# 删除全空的行 df.dropna(how='all',inplace=True)


# 删除重复数据行 df.drop_duplicates(['first_name','last_name'],inplace=True)
删除
替换
仅仅提示一下
# 删除非 ASCII 字符
df['first_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)
df['last_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)

# 切分 sex_hour 列为 sex 列和 hour 列
sorted_columns = ['id','age','weight','first_name','last_name']
df = pd.melt(df,
id_vars=sorted_columns,var_name='sex_hour',value_name='puls_rate').sort_values(sorted_columns)
df[['sex','hour']] = df['sex_hour'].apply(lambda x:pd.Series(([x[:1],'{}-{}'.format(x[1:3],x[3:])])))[[0,1]]
df.drop('sex_hour', axis=1, inplace=True)
# 删除没有心率的数据
row_with_dashes = df['puls_rate'].str.contains('-').fillna(False)
df.drop(df[row_with_dashes].index,
inplace=True)
整合代码
import pandas as pd
# 增加列头
column_names= ['id', 'name', 'age', 'weight','m0006','m0612','m1218','f0006','f0612','f1218']
df = pd.read_csv('../data/patient_heart_rate.csv', names = column_names)
# 切分名字,删除源数据列
df[['first_name','last_name']] = df['name'].str.split(expand=True)
df.drop('name', axis=1, inplace=True)
# 获取 weight 数据列中单位为 lbs 的数据
rows_with_lbs = df['weight'].str.contains('lbs').fillna(False)
df[rows_with_lbs]
# 将 lbs 的数据转换为 kgs 数据
for i,lbs_row in df[rows_with_lbs].iterrows():
weight = int(float(lbs_row['weight'][:-3])/2.2)
df.at[i,'weight'] = '{}kgs'.format(weight)
# 删除全空的行
df.dropna(how='all',inplace=True)
# 删除重复数据行
df.drop_duplicates(['first_name','last_name'],inplace=True)
# 删除非 ASCII 字符
df['first_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)
df['last_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)
# 切分 sex_hour 列为 sex 列和 hour 列
sorted_columns = ['id','age','weight','first_name','last_name']
df = pd.melt(df,
id_vars=sorted_columns,var_name='sex_hour',value_name='puls_rate').sort_values(sorted_columns)
df[['sex','hour']] = df['sex_hour'].apply(lambda x:pd.Series(([x[:1],'{}-{}'.format(x[1:3],x[3:])])))[[0,1]]
df.drop('sex_hour', axis=1, inplace=True)
# 删除没有心率的数据
row_with_dashes = df['puls_rate'].str.contains('-').fillna(False)
df.drop(df[row_with_dashes].index,
inplace=True)
# 重置索引,不做也没关系,主要是为了看着美观一点
df = df.reset_index(drop=True)
print(df)日期的处理
字符编码的问题
预览数据
导入 Pandas
读取 csv 数据到 DataFrame(要确保数据已经下载到指定路径)
import pandas as pd
df = pd.read_csv('../data/Artworks.csv').head(100)
df.head(10)
统计日期数据
df['Date'].value_counts()

日期数据问题
问题一,时间范围(1976-77)
问题二,估计(c. 1917,1917 年前后)
问题三,缺失数据(Unknown)
问题四,无意义数据(n.d.)
处理问题一
row_with_dashes = df['Date'].str.contains('-').fillna(False)
for i, dash in df[row_with_dashes].iterrows():
df.at[i,'Date'] = dash['Date'][0:4]
df['Date'].value_counts()处理问题二
row_with_cs = df['Date'].str.contains('c').fillna(False)
for i,row in df[row_with_cs].iterrows():
df.at[i,'Date'] = row['Date'][-4:]
df[row_with_cs]处理问题三四
df['Date'] = df['Date'].replace('Unknown','0',regex=True)
df['Date'] = df['Date'].replace('n.d.','0',regex=True)
df['Date']
代码整合
mport pandas as pd
df = pd.read_csv('../data/Artworks.csv').head(100)
df.head(10)
df['Date'].value_counts()
row_with_dashes = df['Date'].str.contains('-').fillna(False)
for i, dash in df[row_with_dashes].iterrows():
df.at[i,'Date'] = dash['Date'][0:4]
df['Date'].value_counts()
row_with_cs = df['Date'].str.contains('c').fillna(False)
for i,row in df[row_with_cs].iterrows():
df.at[i,'Date'] = row['Date'][-4:]
df['Date'].value_counts()
df['Date'] = df['Date'].replace('Unknown','0',regex=True)
df['Date'] = df['Date'].replace('n.d.','0',regex=True)
df['Date'].value_counts() 51.9468
51.9468
 4
4
 0
0

 关注作者
关注作者
 收藏
收藏

评论(0)
 发表评论
发表评论
暂无数据






