概括地说,泛化能力(generalization ability)是指机器学习算法对新鲜样本的适应能力。学习的目的是学到隐含在数据对背后的规律,对具有同一规律的学习集以外的数据,经过训练的网络也能给出合适的输出,该能力称为泛化能力。
在机器学习方法中,泛化能力通俗来讲就是指学习到的模型对未知数据的预测能力。在实际情况中,我们通常通过测试误差来评价学习方法的泛化能力。如果在不考虑数据量不足的情况下出现模型的泛化能力差,那么其原因基本为对损失函数的优化没有达到全局最优。
1.泛化能力
在机器学习方法中,泛化能力通俗来讲就是指学习到的模型对未知数据的预测能力。在实际情况中,我们通常通过测试误差来评价学习方法的泛化能力。如果在不考虑数据量不足的情况下出现模型的泛化能力差,那么其原因基本为对损失函数的优化没有达到全局最优。
2.泛化误差
首先给出泛化误差的定义, 如果学到的模型是 f^ , 那么用这个模型对未知数据预测的误差即为泛化误差
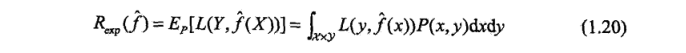
泛化误差反映了学习方法的泛化能力,如果一种方法学习的模型比另一种方法学习的模型具有更小的泛化误差,那么这种方法就更有效, 事实上,泛化误差就是所学到的模型的期望误差。
3.提高泛化能力
提高泛化能力的方式大致有三种:1.增加数据量。2.正则化。3.凸优化。
4.L1正则化,L2正则化
L1正则化的几何解释如图:

L1正则化给出的最优解w∗是使解更加靠近某些轴,而其它的轴则为0.所以L1正则化能使得到的参数稀疏化。
L1正则化的参数先验是服从拉布拉斯分布的,拉布拉斯的概率密度分布函数为:

L2正则化的解释如图:

L2 正则化给出的最优解w∗是使解更加靠近原点,也就是说L2正则化能降低参数范数的总和。
L2正则化的参数先验服从高斯分布,高斯分布的概率密度分布函数为:

CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330