作者:俊欣
来源:关于数据分析与可视化
今天来分享一个高效率的数据清洗的方法,毕竟我们平常在工作和生活当中经常会遇到需要去处理杂七杂八的数据集,有一些数据集中有缺失值、有些数据集中有极值、重复值等等。这次用到的数据集样本在文末有获取的办法。
01、导入库和读取数据
我们首先导入所需要用到的库,并且读取数据
import pandas as pd import numpy as np
df = pd.read_csv("DirectMarketing.csv")
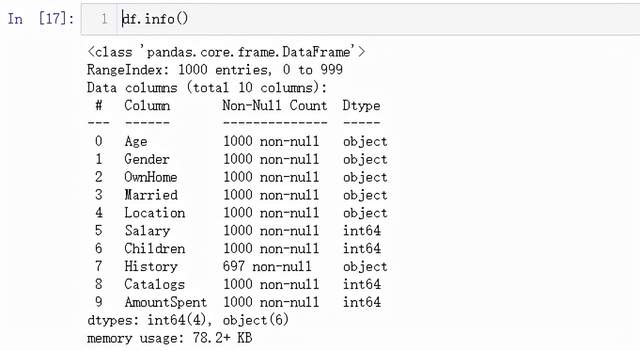
我们先来大致地看一下数据集中各个特征值的情况,通过info()这个方法
df.info()
我们看到上面的“History”这一列,只有697条数据不是空值,那就意味着还有另外3条数据是空值,与之对应的方式有将含有缺失值的数据删掉,或者将缺失值的部分替换为是中位数或者是平均数,
df.dropna(axis = 0, inplace = True)
要是数据集中存在大量的缺失值,只是简简单单地移除掉怕是会影响到数据的完整性,如果是数值类型的特征值,就用用平均值或者是中位数来替换,如果是离散类型的缺失值,就用众数来替换
def fill_missing_values_num(df, col_name): val = df[col_name].median()
df[col_name].fillna(val, inplace = True) return df
def fill_missing_values_cate(df, col_name): val = df[col_name].value_counts().index.tolist()[0]
df[col_name].fillna(val, inplace = True) return df
而可能存在重复值的部分,pandas当中有drop_ducplicates()方法来进行处理
df.drop_duplicates(inplace = True)
最后我们封装成一个函数,对于缺失值的处理小编这里选择用中位数填充的方式来处理
def fill_missing_values_and_drop_duplicates(df, col_name): val = df[col_name].value_counts().index.tolist()[0]
df[col_name].fillna(val, inplace = True) return df.drop_duplicates()
经常使用pandas的人可能都有这种体验,它经常会将数据集中的变量类型直接变成object,这里我们可以直接使用“convert_dtypes”来进行批量的转换,它会自动推断数据原来的类型,并实现转换,并且打印出来里面各列的数据类型,封装成一个函数
def convert_dtypes(df): print(df.dtypes) return df.convert_dtypes()
04、极值的检测
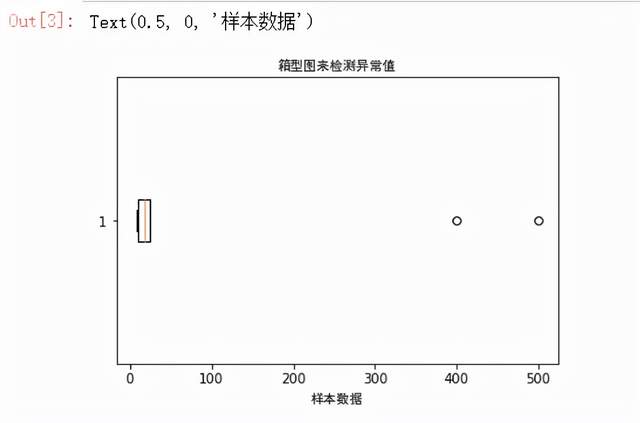
对于极值的检测有多种方式,例如我们可以通过箱型图的方式来查看
sample = [11, 500, 20, 24, 400, 25, 10, 21, 13, 8, 15, 10] plt.boxplot(sample, vert=False) plt.title("箱型图来检测异常值",fontproperties="SimHei") plt.xlabel('样本数据',fontproperties="SimHei")
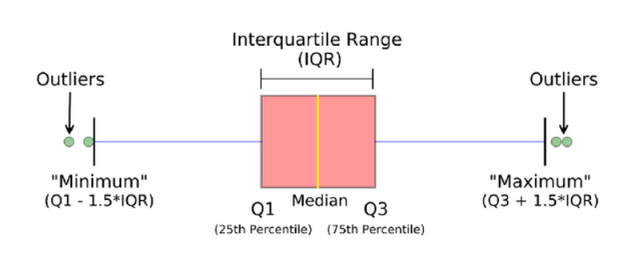
我们可以通过箱型图来明显的看出当中有两个异常值,也就是400和500这两个,箱型图由最大值、上四分位数(Q3)、中位数(Q2)、下四分位数和最小值五个统计量组成,其中Q1和Q3之间的间距称为是四分位间距(interquartile range,IQR),而通常若是样本中的数据大于Q3+1.5IQR和小于Q1-1.5IQR定义为异常值
当然了除此之外,还可以通过z-score的方法来检测,Z-score是以标准差为单位去度量某个数据偏离平均数的距离,计算公式为
我们用python来实现一下当中的步骤
outliers = [] def detect_outliers_zscore(data, threshold): mean = np.mean(data) std = np.std(data) for i in data: z_score = (i-mean)/std if (np.abs(z_score) > threshold): outliers.append(i) return outliers# Driver code
而对待异常值的方式,首先最直接的就是将异常值给去掉,我们检测到异常值所在的行数,然后删掉该行,当然当数据集当中的异常值数量很多的时候,移除掉必然会影响数据集的完整性,从而影响建模最后的效果
def remove_outliers1(df, col_name): low = np.quantile(df[col_name], 0.05)
high = np.quantile(df[col_name], 0.95) return df[df[col_name].between(low, high, inclusive=True)]
其次我们可以将异常值替换成其他的值,例如上面箱型图提到的上四分位数或者是下四分位数
def remove_outliers2(df, col_name): low_num = np.quantile(df[col_name], 0.05) high_num = np.quantile(df[col_name], 0.95) df.loc[df[col_name] > high_num, col_name] = high_num df.loc[df[col_name] < low_num , col_name] = low_num return df
因此回到上面用到的样本数据集,我们将之前数据清洗的函数统统整合起来,用pipe()的方法来串联起来,形成一个数据清洗的标准模板
def fill_missing_values_and_drop_duplicates(df, col_name): val = df[col_name].value_counts().index.tolist()[0]
df[col_name].fillna(val, inplace = True) return df.drop_duplicates() def remove_outliers2(df, col_name): low_num = np.quantile(df[col_name], 0.05)
high_num = np.quantile(df[col_name], 0.95)
df.loc[df[col_name] > float(high_num), col_name] = high_num return df def convert_dtypes(df): print(df.dtypes) return df.convert_dtypes()
df_cleaned = (df.pipe(fill_missing_values_and_drop_duplicates, 'History').
pipe(remove_outliers2, 'Salary').
pipe(convert_dtypes))
06、写在最后
所以我们之后再数据清洗的过程当中,可以将这种程序化的清洗步骤封装成一个个函数,然后用pipe()串联起来,用在每一个数据分析的项目当中,更快地提高我们工作和分析的效率。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;

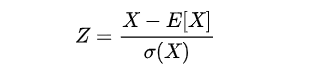











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330