作者:伍正祥
来源:AI入门学习
一、图形概述
平行坐标是一种通常的可视化方法, 用于对 高维几何多元数据的可视化。为了表示在高维空间的一个点集, 在N条平行的线的背景下,一个在高维空间的点被表示为一条拐点在N条平行坐标轴的折线,在第K个坐标轴上的位置就表示这个点在第K个维的值。
平行坐标是信息可视化的一种重要技术。 为了克服传统的笛卡尔直角坐标系容易耗尽空间、 难以表达三维以上数据的问题, 平行坐标将高维数据的各个变量用一系列相互平行的坐标轴表示, 变量值对应轴上位置。 为了反映变化趋势和各个变量间相互关系,往往将描述不同变量的各点连接成折线。所以平行坐标图的实质是将 维欧式空间的一个点Xi(xi1,xi2,...,xim) 映射到 维平面上的一条曲线。
平行坐标图可以表示超高维数据。 平行坐标的一个显著优点是其具有良好的数学基础, 其射影几何解释和对偶特性使它很适合用于可视化数据分析。下面我们看看具体的应用案例。
二、案例学习
Millward Brown每年都会总结全球范围内最具价值的品牌,Valerio Pellegrini根据2010至2015年的前100位品牌的排名变化,下图是利用平行坐标图进行可视化的结果,从图中可以看出来,谷歌、IBM、苹果、微软的排名都比较稳定,变动不大,而处于中下的公司,每年的排名波动则比较大,并且每年都有新进品牌。非常清晰的实现了多样本、多维度的对比分析。
100 MOST VALUABLE BRANDS 2010-15
下面的平行坐标图也是对1990至2013年,全球移民目的地和来源地的排名进行了可视化。
《全球移民路线图:美国为移民首选目的地》网易数读
下面的图,表达了1978年—2017年,大陆各省人均GDP的名次变化,图中包含的信息量非常大。
1)40年来,北京、上海、天津一直占据top 3,只不过换了个位置
2)天津一度占据榜首
3)黑龙江和甘肃高开低走,就像瀑布一样一泻千里
4)福建低开高走,上升迅猛,都说福建人会做生意,此数据显示,不假
5)贵州打开跌停板,近几年摆脱垫底,估计是贵阳发展大数据的原因
6)海南冲高回落,几乎又回到了原点
还包含了更多的信息,比如每个大BOSS任期内,是否存在重大扶持的省份等……
下图是1978年—2017年,大陆各省总体GDP的名次变化,同样包含特别多的信息,大家可以分析下。
(1978-2017年全国各省区GDP排名,不含香港、澳门、台湾,数据来源国家统计局及各省统计年鉴,制图@张靖/星球研究所)
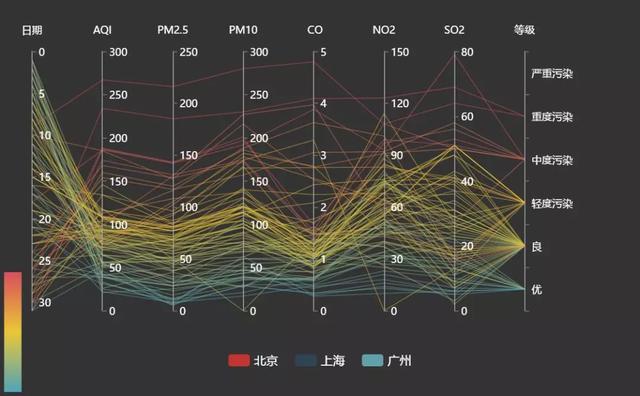
在平行坐标图中,每个变量都有自己的轴线,所有轴线彼此平行放置,各自可有不同的刻度和测量单位,一系列的直线穿越所有轴线来表示不同数值。
另外,虽然轴线排列没有固定的顺序,但是因为相邻变量会比非相邻的变量更容易进行比较,所以轴线排列的顺序可能会影响读者理解数据。
在平行坐标图里,各轴的单位一般是不相同的,所以不能进行跨轴的数据比较。但是在上文提到的关于不同年份的排名时,由于是对相同变量的可视化,所以可以进行跨轴比较。因而,在读图时,我们要注意各轴的测量单位。
三、绘图指南
1、R语言绘图
说实话,R语言的这个包绘图比较丑,大家有没有更好的包推荐,上面的案例,基本上都有组合P图的痕迹,直接画的软件还没发现比较好的。
#安装与加载包
#install.packages('lattice')
library(lattice)
data(iris)
parallelplot(
~ iris[1:4],
data = iris,
groups = Species,
horizontal.axis = FALSE,#是否要垂直展示
scales = list(x = list(rot = 90))
)
2、线上Echarts绘图
网址链接:http://echarts.baidu.com/examples/
改变图中的代码,即可完成想要的图
想从事业务型数据分析师,您可以点击>>>“数据分析师”了解课程详情;
想从事大数据分析师,您可以点击>>>“大数据就业”了解课程详情;
想成为人工智能工程师,您可以点击>>>“人工智能就业”了解课程详情;
想了解Python数据分析,您可以点击>>>“Python数据分析师”了解课程详情;
想咨询互联网运营,你可以点击>>>“互联网运营就业班”了解课程详情;
想了解更多优质课程,请点击>>>
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330