大数据存储平台之异构存储实践深度解读
经常做数据处理的伙伴们肯定会有这样一种体会:最近一周内的数据会被经常使用到,而比如最近几周的数据使用率会有下降,每周仅仅被访问几次;在比如3月以前的数据使用率会大幅下滑,存储的数据可能一个月才被访问几次。

这就产生了一种热和冷数据,对需要频繁访问的数据我们称之为“热”数据,反之我们称之为”冷”数据,而处于中间的数据我们称之为”温”数据。
在数据被视为公司资产的时代,每个公司基本都会保存最近数年的数据,而这些数据尤其是冷数据的累积也给存储平台带来了甜蜜的负担。下面就来分享下如何解决这些“负担”。
首先如何定义数据为冷热数据呢,eBay公司根据数据年龄和使用频率来定义不失为一种办法,下图为eBay关于数据温度的定义。

从hadoop2.6开始,HDFS更好的支持了这种冷热数据的分离存储,我们可以按HDFS路径指定其存储策略,目前HDFS支持的存储策略有:HOT、WARM、COLD、All_SSD、One_SSD、Lazy_Persist,我们着重介绍SSD相关的存储策略,具体如下:
All_SSD - 用于将所有副本存储在SSD中
One_SSD - 用于将其中一个副本存储在SSD中。剩余的副本存储在DISK中
Lazy_Persist - 用于在内存中写入单个副本的块。该副本首先写入RAM_DISK,然后在DISK中延续
创建文件或目录时,其存储策略未指定。可以使用“hdfs dfsadmin -setStoragePolicy ”命令指定存储策略。文件或目录的有效存储策略由以下规则解决。
如果文件或目录特定于存储策略,则返回。
对于未指定的文件或目录,如果是根目录,则返回默认存储策略。否则,返回其父级的有效存储策略。
我们在实践过程中,因为有一部分实时分析的需求,一部分是历史数据的保存,历史数据很少参与计算,只需偶尔查询会用到。那么对于历史数据来说,我们可以使用一批计算能力较弱,而硬盘较多、容量较大的SATA盘,而实时分析的场景,需要高性能的计算力和硬盘吞吐能力,我们选用SSD硬盘来支撑,此外HDFS还提供了内存存储类型,但我们的内存还是有限,暂未使用到。实际上,我们的每台服务器的12块硬盘slot中有3个是SSD,其余9个是SATA。我们实践结果表明,使用这种策略的效果比以前好了4倍以上。
要使用存储策略,我们需要在在每个数据节点上hdfs-site.xml中参数dfs.datanode.data.dir配置的由逗号分隔的存储位置使用的存储类型进行标记。例如:
使用[DISK]file:///dfs/dn来标识这个存储位置为普通硬盘
使用[SSD]file:/// dfs/dn来标识这个存储位置为SSD硬盘
此外,默认情况下的存储格式为DISK。
下面介绍设置存储策略命令:
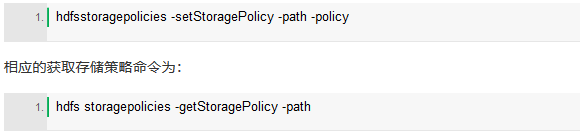
总结下:我们可以在一个限定的Hadoop集群中进行设置不同的磁盘使用不同的存储策略,还可以利用API将数据存储到不同的存储层。HDFS设计的详细存储类型和存储策略如下表,有兴趣的同学可以看看:
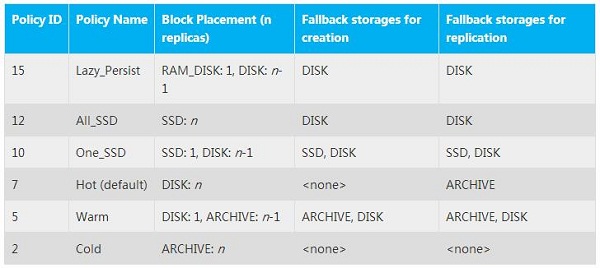
注:HDFS新加的ARCHIVE存储类型, 它是一种支持PB级的高容量存储但很少的 计算能力,用于归档数据使用,从上图可以看出冷数据适合使用archive存储类型。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330