文章来源: Python猫
作者:豌豆花下猫

zip() 是 Python 中最好用的内置类型之一,它可以接收多个可迭代对象参数,再返回一个迭代器,可以把不同可迭代对象的元素组合起来。
我之前写迭代器系列的时候,在《Python进阶:设计模式之迭代器模式》中简单地介绍过它,前几天翻译了 Python 3.10 采纳的 PEP-618 ,介绍了它将会迎来的变更。
但是,还有不少同学并不知道 zip(),或者不能熟练掌握它的用法,因此本文打算来做一个更为详细的梳理。
内容主要分三部分:
用法部分:介绍它的基础用法、高级用法、骚操作用法
进阶部分:介绍它的实现原理,关注几个实现的细节
发散部分:聚焦它的不足,以及解决方法
1、zip() 的 n 种用法
基本用法:像拉链一样,将多个可迭代对象组合起来,然后可以用 for 循环依次取出,或者一次性将结果存入列表、元组或者字典之类的容器中。
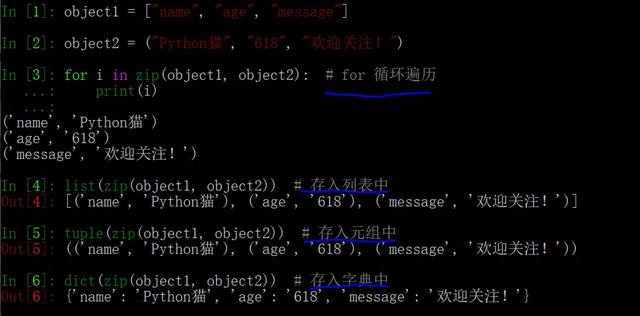
它的结果是一个迭代器,迭代器生成的元素是元组,第 i 个元组的元素分别来自可迭代对象参数的第 i 个元素,如上图所示。
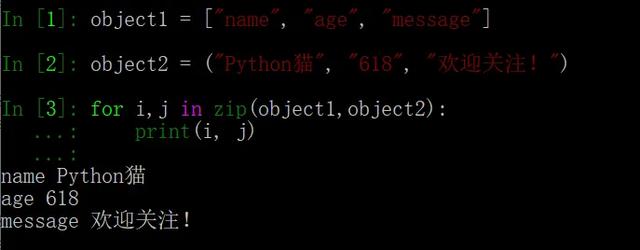
另外,for 循环还可以把元组内的元素依次取出,这样会很方便:
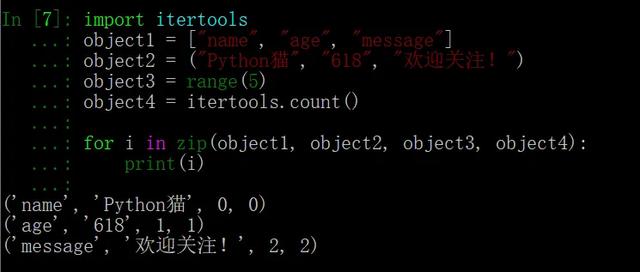
它的参数并不要求是同一类的可迭代对象,因此可以有非常多的组合方式,例如:
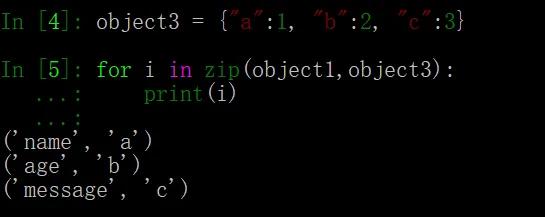
但是,如果把字典作为 zip() 的参数,会是什么结果呢?字典是 key-value 键值对形式,跟列表之类的单一元素结构不同。
实验一下,可以看出,zip() 默认只会遍历字典的 key 值:
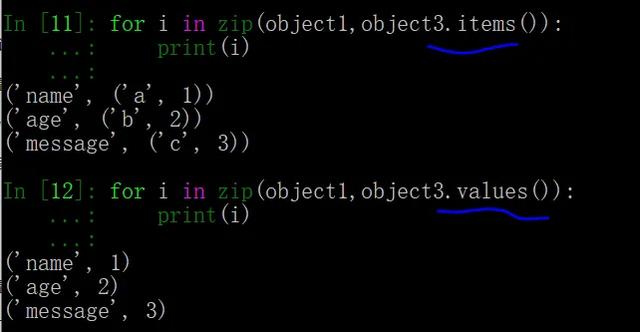
如果想要取出字典的 value 值,或者取出 key-value 键值对,那么可以使用字典自带的遍历方法 values() 和 items():
使用 zip(),还可以比较方便地对二维列表实现行列转换:
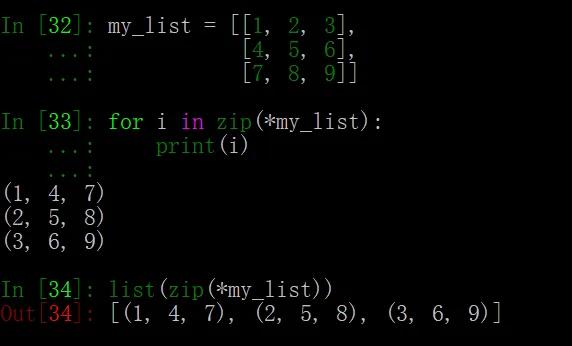
上例中的星号(*)操作符可以解包(unpacking),即将 my_list 的元素(也是列表)解成多个参数给 zip(),从而将 3 个列表重新组合。
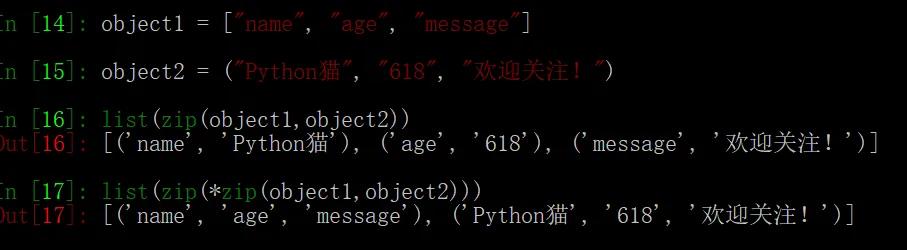
解包操作符对于 zip 对象同样适用,因为 zip() 本身是一次行列转换的操作,若将它解包后作为参数给 zip(),等于再做一次行列转换,也就是回到了原点(除了最后的结果是元组):
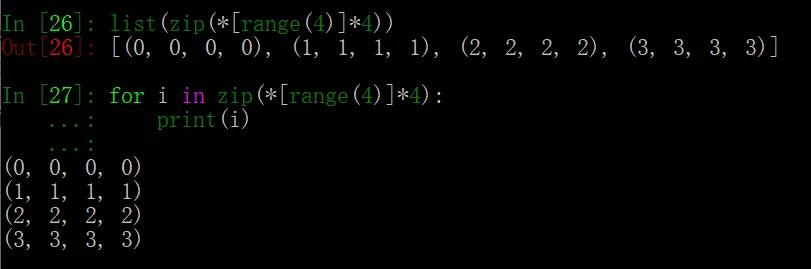
最后再介绍一种用法:创建 n*n 的方阵,每行的数字相同。
2、zip() 的原理解析
官方文档中给出了 zip() 的 Python 伪代码(并非是 Python 解释器内置的实现,只为了展示基本的代码逻辑):
def zip(*iterables):
# zip('ABCD', 'xy') --> Ax By
sentinel = object()
iterators = [iter(it) for it in iterables]
while iterators:
result = []
for it in iterators:
elem = next(it, sentinel)
if elem is sentinel:
return
result.append(elem)
yield tuple(result)
在这段简短的代码中,可以分析出几点关键的信息:
zip 接收可变数量的可迭代对象参数,这些参数会经过 iter() 处理成迭代器。推论:若出现非可迭代对象,此处会报错
while 循环在判断列表是否为空,而列表中的元素是将参数转化而成的迭代器。推论:若入参存在有效的可迭代对象,则 while 循环始终为真;若没有入参,则什么都不做
next() 会依次读取迭代器中的下一个元素,它的第二个参数会作为迭代器耗尽时的返回值。推论:每一轮依次取出这些迭代器的一个元素,当某个迭代被耗尽时,则退出死循环,这就意味着未耗尽的迭代器会被直接舍弃
3、zip() 的问题与解决
zip() 最明显的问题是它会舍弃掉未耗尽的迭代器:
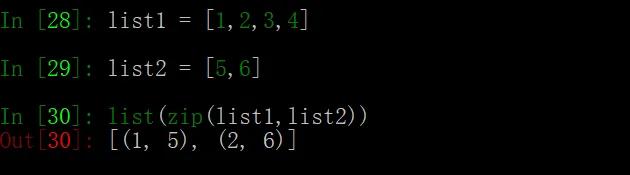
这是一种木桶效应,最终的结果由最短的木板来决定。
有一种解决思路是取长板,同时补足短板(用 None 值填充),这就是 itertools 中的 zip_longest 方法:
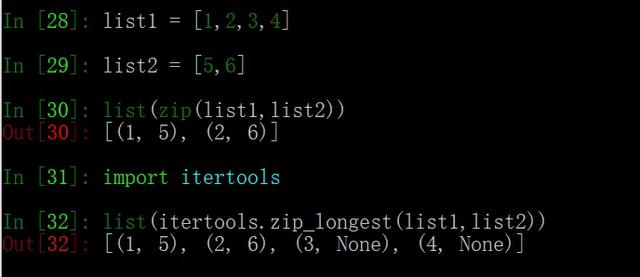
它填充了冗余数据,同时最大限度地保证了原始数据的完整性。
但是,如果我们不希望有冗余数据,只希望得到按最长方式对齐的数据呢?
Python 官方最近采纳了 PEP-618.它就是为了应对这个问题。当出现迭代器长度不一致时,它既不向短板妥协,也不向长板妥协,而是抛出 ValueError。它认为入参值错误,也就是严格要求入参的数据完整性。
该 PEP 会被合入到一年后的 Python 3.10 版本,关于更多的内容细节,可查阅这篇PEP-618 译文 。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330