数据


关于NMF,在隐语义模型和NMF(非负矩阵分解)已经有过介绍。

运行后输出:

可视化物品的主题分布:

结果:

从距离的角度来看,item 5和item 6比较类似;从余弦相似度角度看,item 2、5、6 比较相似,item 1、3比较相似。
可视化用户的主题分布:

结果:

从距离的角度来看,Fred、Ben、Tom的口味差不多;从余弦相似度角度看,Fred、Ben、Tom的口味还是差不多。
现在对于用户A,如何向其推荐物品呢?
方法1: 找出与用户A最相似的用户B,将B评分过的、评分较高、A没评分过的的若干物品推荐给A。
方法2: 找出用户A评分较高的若干物品,找出与这些物品相似的、且A没评分的若干物品推荐给A。
方法3: 找出用户A最感兴趣的k个主题,找出最符合这k个主题的、且A没评分的若干物品推荐给A。
方法4: 由NMF得到的两个矩阵,重建评分矩阵。例如:

运行结果:

对于Tom(评分矩阵的第2行),其未评分过的物品是item 2、item 3、item 4。item 2的推荐值是2.19148602,item 3的推荐值是1.73560797,item 4的推荐值是0,若要推荐一个物品,推荐item 2。
NMF是将非负矩阵V分解为两个非负矩阵W和H:
V=W×H
在本文上面的实现中,V对应评分矩阵,W是用户的主题分布,H是物品的主题分布。
对于有评分记录的新用户,如何得到其主题分布?
方法1: 有评分记录的新用户的评分数据放入评分矩阵中,使用NMF处理新的评分矩阵。
方法2: 物品的主题分布矩阵H保持不变,将V更换为新用户的评分组成的行向量,求W即可。
下面尝试一下方法2。
设新用户Bob的评分记录为:

运行结果是:

关于SVD的一篇好文章:强大的矩阵奇异值分解(SVD)及其应用。
相关分析与上面类似,这里就直接上代码了。

运行结果:

可视化一下:

0代表没有评分,但是上面的方法(如何推荐这一节的方法4)又确实把0看作了评分,所以最终得到的只是一个推荐值(而且总体都偏小),而无法当作预测的评分。在How do I use the SVD in collaborative filtering?有这方面的讨论。
SVD的目标是将m*n大小的矩阵A分解为三个矩阵的乘积:
[latex]
A = U S V^{T}
[/latex]
U和V都是正交矩阵,大小分别是m*m、n*n。S是一个对角矩阵,大小是m*n,对角线存放着奇异值,从左上到右下依次减小,设奇异值的数量是r。
取k,k<<r。
取得UU的前k列得到UkUk,SS的前k个奇异值对应的方形矩阵得到SkSk,VTVT的前k行得到VTkVkT,于是有
[latex]
A_{k} = U_{k} S_{k} V^{T}_{k}
[/latex]
AkAk可以认为是AA的近似。
这个算法来自下面这篇论文:
Vozalis M G, Margaritis K G. Applying SVD on Generalized Item-based Filtering[J]. IJCSA, 2006, 3(3): 27-51.
1、 设评分矩阵为R,大小为m*n,m个用户,n个物品。R中元素rijrij代表着用户uiui对物品ijij的评分。
2、 预处理R,消除掉其中未评分数据(即值为0)的评分。
计算R中每一行的平均值(平均值的计算中不包括值为0的评分),令Rfilled−in=RRfilled−in=R,然后将Rfilled−inRfilled−in中的0设置为该行的平均值。
计算R中每一列的平均值(平均值的计算中不包括值为0的评分)riri,Rfilled−inRfilled−in中的所有元素减去对应的riri,得到正规化的矩阵RnormRnorm。(norm,即normalized)。
3、 对RnormRnorm进行奇异值分解,得到:
[latex]
R_{norm} = U S V^{T}
[/latex]
4、 设正整数k,取得UU的前k列得到UkUk,SS的前k个奇异值对应的方形矩阵得到SkSk,VTVT的前k行得到VTkVkT,于是有
[latex]
R_{red} = U_{k} S_{k} V^{T}_{k}
[/latex]
red,即dimensionality reduction中的reduction。可以认为k是指最重要的k个主题。定义RredRred中元素rrijrrij用户i对物品j在矩阵RredRred中的值。
5、 [latex] U_{k} S_{k}^{\frac{1}{2}}[/latex],是用户相关的降维后的数据,其中的每行代表着对应用户在新特征空间下位置。[latex] S_{k}^{\frac{1}{2}}V^{T}_{k}[/latex],是物品相关的降维后的数据,其中的每列代表着对应物品在新特征空间下的位置。
S12k∗VTkSk12∗VkT中的元素mrijmrij代表物品j在新空间下维度i中的值,也可以认为是物品j属于主题i的程度。(共有k个主题)。
6、 获取物品之间相似度。
根据S12k∗VTkSk12∗VkT计算物品之间的相似度,例如使用余弦相似度计算物品j和f的相似度: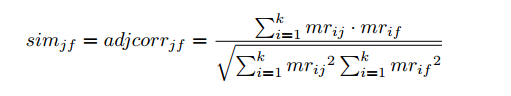
相似度计算出来后就可以得到每个物品最相似的若干物品了。
7、 使用下面的公式预测用户a对物品j的评分:
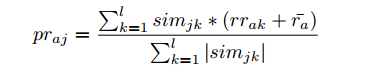
这个公式里有些变量的使用和上面的冲突了(例如k)。
ll是指取物品j最相似的ll个物品。
mrijmrij代表物品j在新空间下维度i中的值,也可以认为是物品j属于主题i的程度。
simjksimjk是物品j和物品k的相似度。
RredRred中元素rrakrrak是用户a对物品k在矩阵RredRred中对应的评分。ra¯ra¯是指用户a在评分矩阵RR中评分的平均值(平均值的计算中不包括值为0的评分)。

数据分析咨询请扫描二维码
CDA数据分析师在中国航信高科技产业园进行了面向测试度量的数据分析培训课程,培训人数近2 ...
2024-05-01CDA数据分析师走进深圳迈瑞生物医疗电子股份有限公司,在迈瑞总部展开了为期两天的培训,本次课程参训人员线上及线下近百人, ...
2024-05-01CDA数据分析师在合肥市对合肥阳光新能源科技有限公司开展了为期8天的企业内训。 合肥阳光新能源科技 ...
2024-05-01CDA数据分析师走进海尔大学,进行了《数据治理与数据中台建设的道与术》专题培训,培训现场爆满,近百人参加了此次培训。 ...
2024-05-01在中国银行苏州分行培训中心开始数据分析师培训,此次培训课程共10天内容,包括Excel、MySQL、概率论与数理统计、SPSS等内容, ...
2024-05-01从实际的业务需求出发,结合行业的典型应用特点,围绕实际的商业问题,探讨数据挖掘、机器学习模型在金融领域的应用,包括获客、信用评分、细分画像、交叉销售、反欺诈、违规识别、时序预测、运筹优化、流程挖掘九个方面,形成 ...
2024-05-01本次培训课程为线上+线下的模式,由于学员编程能力不一、部分学员没有编程基础,故提供统计学、python基 ...
2024-05-01华夏银行信用卡中心-机器学习培训 1、课程亮点 取材于业界一流企业和顶级咨询公司的行业实践;已经被证明是人人 ...
2024-05-01主 题:数据中台建设及数据分析应用主题分享 1. 数据中台市场洞察 2. 主流数据中台产品比较 3. 某企业数据中 ...
2024-05-01围绕“数据驱动”战略,全力打造我行 300 人数字化人才梯队,着力培养数字化管理人才、大数据专业团队 ...
2024-05-01在当今数据驱动的商业环境中,数据分析成为了企业决策的重要依据。通过对大量数据的收集、处理和分析,企业能够更好地理解市场 ...
2024-04-29在人工智能(AI)的世界里,提示词(Prompt)是一种强大的工具,它能够引导AI按照用户的需求产生特定的输出。本文将深入探讨AI ...
2024-04-29CDA立足未来职场,拓展前沿视野——对外经贸大学保险学院举办“三全育人大讲堂”分享行业最新动态。 ...
2024-04-294月2日,CDA数据分析师创始发起人兼协会理事长赵坚毅博士受邀在浙江万里学院举办了一场以“数字化能力在职场中的作用” ...
2024-04-29随机森林(Random Forests)现在机器学习中比较火的一个算法,是一种基于Bagging的集成学习方法,能够很好地处理分类和回归的问 ...
2022-12-23方差分析是数据分析中常用的一种统计分析方法,接下来让我们简单了解一下方差分析的基本思想和原理吧。 方差分析(Analysis ...
2022-12-23来源:关于数据分析与可视化 关于streamlit-aggrid 数据排序 表格样式的调整 数据 ...
2022-08-03作者:麦叔 定义 「把上面晦涩的概念汇成一句话就是:」 ❝ 回调函数就是一个被作为参 ...
2022-08-03现今,高学历人群日益增多,物以稀为贵的高学历光环淡去。无论本科生还是研究生,甚至博士生,求职竞争力都大不如前,就业压力越来越大。
2022-06-01某家企业10个人面试,有9个本科生……如何脱颖而出,除得体的举止和良好的沟通力外,证书成重要筹码,这也是很多人考证的关键所在。
2022-04-14





