WePay机器学习反欺诈实践:Python+scikit-learn+随机森林
什么是shell selling?
虽然欺诈几乎涉及各种领域,但相对于传统的买方或卖方仅仅担心对方是否是骗子,支付平台需要担心的是交易双方。如果其中任何一方存在信用诈骗,真正的持卡人发现和撤销费用,平台自身就要进行账单偿还。
shell selling是在这种情况下特别受关注的欺诈类型的一种。基本上,当交易双方都带有欺骗性质时,这种模式便会发生,比如说有一个犯罪分子用偷来的一个信用卡账户来支付两笔支付。
shell selling可能很难发现,因为这些欺骗者姿态很低调。他们通常没有多少“真正”的客户,所以你不能依靠用户反馈结果,用这种方式你会碰到更多传统的欺骗者。当一个商人在一个很短的时间段里获得了来自同一个IP的一堆付款时,这很明显,但主导这种欺诈罪行的情况往往比这还要复杂很多。他们常常使用各种各样的技术来隐藏自己的身份和逃避侦测。
由于shell selling是一个普遍的难题,而且很难被发现,所以我们决定建立一个机器学习算法来帮助抓住它。
在WePay,我们采用Python建立整个机器学习的流程,采用流行的scikit-learn开源学习机器学习工具包。如果你还没有使用过scikit-learn,我强烈建议你尝试。对于欺诈模型这类需要不断重新训练和快速部署的任务,它有很多优点:
scikit-learn使用一个统一的API来跨不同机器学习算法实现模型拟合与预测,使得不同算法之间的代码复用真正有效。
网络服务(web services)的评分可以利用Django或Flask直接进行基于Python的服务器托管,从而使部署更为简单。我们只需要安装scikit-learn,复制导出模型文件和必要的数据处理管道代码到网络服务实例用于启动。
整个模型的开发和部署周期完全用Python独立编写。这给了我们一个超过其他流行机器学习语言像R或SAS的优势,后者需要模型在投入生产之前被转换成另一种语言。除了通过消除不必要的步骤简化了开发,这还给予我们更多的灵活性来尝试不同的算法,因为通常情况下,这个转换过程并不好处理,它们在另一个环境中的麻烦会多于价值。
算法:随机森林(Random Forest)
回到shell selling,我们测试了几种算法,然后选定能给以我们最好的性能的算法:随机森林。
随机森林是Leo Breiman 和 Adele Cutler开发的一种基于树形结构的集成方法,由Breiman于2001年在机器学习期刊的评议文章中首次提出[1]。随机森林在训练数据的随机子集上训练许多决策树,然后使用单个树的预测均值作为最终的预测。随机子集是从原始的训练数据抽样,通过在记录级有放回抽样(bootstrap)和在特征级随机二次抽样得到。
我们尝试的算法的召回率,随机森林提供了最佳的精度,紧随其后的是神经网络和另外一种集成方法AdaBoost。相比于其他算法,随机森林针对我们碰到的各类欺诈数据有许多的优势:
基于集成方法的树可以同时很好地处理非线性和非单调性,这在欺诈信号中相当普遍。相比之下,神经网络对非线性处理地相当不错,但同时受到非单调性的羁绊,而逻辑回归都无法处理。对于使用后两种方法来处理的非线性和/或非单调性,我们需要广泛的和适当的特征转换。
随机森林需要最小的特征预备和特征转换,它不需要神经网络和逻辑回归要求的标准化输入变量,也不需要聚类和风险评级转换为非单调变量。
随机森林相比其他算法拥有最好的开箱即用的性能。另一个基于树的方法,梯度提升决策树(GBT),可以达到类似的性能,但需要更多的参数调优。
随机森林输出特征的重要性体现在作为模型训练的副产品,这对于特征选择是非常有用的[2]。
随机森林与其他算法相比具有更好的过拟合(overfitting)容错性,并且处理大量的变量也不会有太多的过拟合[1],因为过拟合可以通过更多的决策树来削弱。此外,变量的选择和减少也不像其他算法那么重要。
下图是随机森林与其竞争对手的对比情况:

训练算法
我们的机器学习流程遵循一个标准程序,包括数据抽取、数据清洗、特征推导、特征工程和转换、特征选择、模型训练和模型性能评价:
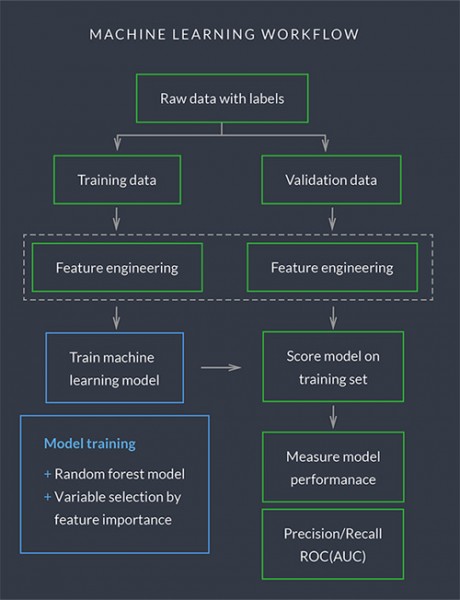
洞察
经过大量的训练,我们的随机森林算法对于shell selling的识别已经成为现实,并且积极地阻止欺诈。当然我们还需要大量的工作去选择、训练和部署该算法,但是它已经使得我们的风险流程更加健壮,且有能力使用更少的人工来检查抓住更多的欺诈。在同一欺诈召回率,这一模型的精度是不断调整和优化规则的2 – 3倍。
使用这种算法,除了得到明显的好处以外,我们对于数据和建模过程中使用的方法也有了更多的理解:
通过特征选择的过程,我们发现对这种欺诈行为最有预测力的特征是速度型的变量。这些包括用户的交易量、设备、真正的IP和信用卡。我们还发现,设备ID、银行账户和信用卡等账户相关特性都是很有用的,如多个账户登录到一个设备,以及多重提款到一个银行账户。
风险等级的分类变量,如电子邮件域,应用程序ID、用户的国家,以及一天中的时间风险评级,也证明了高度预测性。
数字足迹诸如浏览器语言、操作系统字体、屏幕分辨率、用户代理、flash版本等对于反欺诈是有点用的。稍微有更多预测性的是在人们隐藏他们的数字足迹过程当中,例如VPN隧道或虚拟机和TOR的使用。
我们还发现模型性能迅速恶化。这真的不是一个惊喜——骗子不断改变他们的方法来避免检测,所以即使是最好的模型,如果不改变也终将过时。但是我们非常惊讶这发生的速度有多快。对shell selling而言,在模型训练后仅仅第一个月精度便下降一半。因此, 经常刷新模型来保持高检测精度对于欺诈检测的成功是至关重要的。
不幸的是,频繁刷新暴露出他们自己的问题。虽然刷新模型尽可能经常是理想的,但是在使用最近的事务数据来训练模型时必须格外小心。欺诈标签可以需要一个月成熟,所以事实上使用最近的数据也会污染模型。和我们最初的假设不同,利用最新数据在线学习并不会总能得到最好的结果。
随机森林是一个生产高性能模型的优异的机器学习算法,然而,它通常被用来作为一个黑盒方法。这是一个问题,因为我们并不是试图要完全削减人类的全部过程,而且很有可能无法做到即使我们愿意。人类分析师总是希望得到原因代码,告诉他们为什么事情被标记之后来引导他们的案件审查。但随机森林,就其本身而言,不能随时提供原因代码。解释模型数据是困难的,而且还可能涉及挖掘“森林”的结构,这可以显著提高评分的时间。实际上,为了应对这个问题,WePay的数据科学团队发明了一种新的私有方法可以从随机森林算生成原因代码,我们为这种方法申请了临时专利。
结论
风险管理技术是WePay的核心。风险管理不仅仅是技术,它还体现了人类和技术无缝合作的伙伴关系。它在很大程度上仍然是人类不得不思考的方式,骗子可以攻击一个支付系统,编写规则来阻止它们,而且还是一个经验丰富的专业人员,当它下跌到 “明显欺诈”和“显然合法” 之间的灰色地带时,它必须像经常处理的那样,做出判断是否阻止交易。
这就是为什么我们如此兴奋于机器学习和人工智能。我们并非试图取代人类,只是希望机器智能更加聪明更好地工作,而我们可以集中人类智慧关注其他的大难题。

数据分析咨询请扫描二维码
CDA数据分析师在中国航信高科技产业园进行了面向测试度量的数据分析培训课程,培训人数近2 ...
2024-05-01CDA数据分析师走进深圳迈瑞生物医疗电子股份有限公司,在迈瑞总部展开了为期两天的培训,本次课程参训人员线上及线下近百人, ...
2024-05-01CDA数据分析师在合肥市对合肥阳光新能源科技有限公司开展了为期8天的企业内训。 合肥阳光新能源科技 ...
2024-05-01CDA数据分析师走进海尔大学,进行了《数据治理与数据中台建设的道与术》专题培训,培训现场爆满,近百人参加了此次培训。 ...
2024-05-01在中国银行苏州分行培训中心开始数据分析师培训,此次培训课程共10天内容,包括Excel、MySQL、概率论与数理统计、SPSS等内容, ...
2024-05-01从实际的业务需求出发,结合行业的典型应用特点,围绕实际的商业问题,探讨数据挖掘、机器学习模型在金融领域的应用,包括获客、信用评分、细分画像、交叉销售、反欺诈、违规识别、时序预测、运筹优化、流程挖掘九个方面,形成 ...
2024-05-01本次培训课程为线上+线下的模式,由于学员编程能力不一、部分学员没有编程基础,故提供统计学、python基 ...
2024-05-01华夏银行信用卡中心-机器学习培训 1、课程亮点 取材于业界一流企业和顶级咨询公司的行业实践;已经被证明是人人 ...
2024-05-01主 题:数据中台建设及数据分析应用主题分享 1. 数据中台市场洞察 2. 主流数据中台产品比较 3. 某企业数据中 ...
2024-05-01围绕“数据驱动”战略,全力打造我行 300 人数字化人才梯队,着力培养数字化管理人才、大数据专业团队 ...
2024-05-01在当今数据驱动的商业环境中,数据分析成为了企业决策的重要依据。通过对大量数据的收集、处理和分析,企业能够更好地理解市场 ...
2024-04-29在人工智能(AI)的世界里,提示词(Prompt)是一种强大的工具,它能够引导AI按照用户的需求产生特定的输出。本文将深入探讨AI ...
2024-04-29CDA立足未来职场,拓展前沿视野——对外经贸大学保险学院举办“三全育人大讲堂”分享行业最新动态。 ...
2024-04-294月2日,CDA数据分析师创始发起人兼协会理事长赵坚毅博士受邀在浙江万里学院举办了一场以“数字化能力在职场中的作用” ...
2024-04-29随机森林(Random Forests)现在机器学习中比较火的一个算法,是一种基于Bagging的集成学习方法,能够很好地处理分类和回归的问 ...
2022-12-23方差分析是数据分析中常用的一种统计分析方法,接下来让我们简单了解一下方差分析的基本思想和原理吧。 方差分析(Analysis ...
2022-12-23来源:关于数据分析与可视化 关于streamlit-aggrid 数据排序 表格样式的调整 数据 ...
2022-08-03作者:麦叔 定义 「把上面晦涩的概念汇成一句话就是:」 ❝ 回调函数就是一个被作为参 ...
2022-08-03现今,高学历人群日益增多,物以稀为贵的高学历光环淡去。无论本科生还是研究生,甚至博士生,求职竞争力都大不如前,就业压力越来越大。
2022-06-01某家企业10个人面试,有9个本科生……如何脱颖而出,除得体的举止和良好的沟通力外,证书成重要筹码,这也是很多人考证的关键所在。
2022-04-14





