用SPSS做判别分析的流程介绍
如何用SPSS做判别分析呢?下面我们就说说用SPSS的整个操作流程。
1.Discriminant Analysis判别分析主对话框
如图 1-1 所示
图 1-1 Discriminant Analysis 主对话框
(1)选择分类变量及其范围
在主对话框中左面的矩形框中选择表明已知的观测量所属类别的变量(一定是离散变量),
按上面的一个向右的箭头按钮,使该变量名移到右面的Grouping Variable 框中。
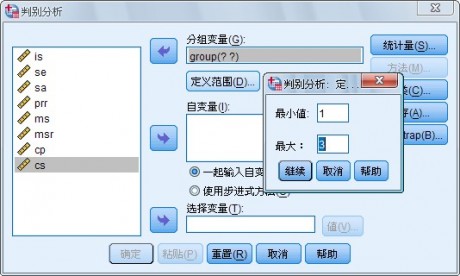
此时矩形框下面的Define Range 按钮加亮,按该按钮屏幕显示一个小对话框如图1-2 所示,供指定该分类变量的数值范围。
图 1-2 Define Range 对话框
在Minimum 框中输入该分类变量的最小值在Maximum 框中输入该分类变量的最大值。按Continue 按钮返回主对话框。
(2)指定判别分析的自变量
图 1-3 展开 Selection Variable 对话框的主对话框
在主对话框的左面的变量表中选择表明观测量
特征的变量,按下面一个箭头按钮。
把选中的变量移到Independents 矩形框中,作为参与判别分析的变量。
(3) 选择观测量
如果希望使用一部分观测量进行判别函数的推导而且有一个变量的某个值可以作为这些观测量的标识,
则用Select 功能进行选择,操作方法是单击Select 按钮展开Selection Variable。选择框如图1-3 所示。
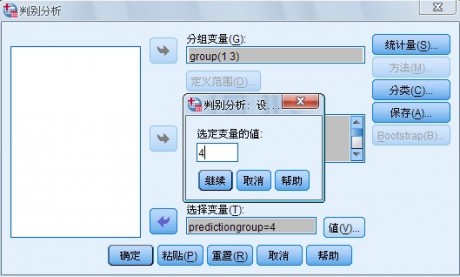
并从变量列表框中选择变量移入该框中再单击Selection Variable 选择框右侧的Value按钮,
展开Set Value(子对话框)对话框,如图1-4 所示,键入标识参与分析的观测量所具有的该变量值,
一般均使用数据文件中的所有合法观测量此步骤可以省略。
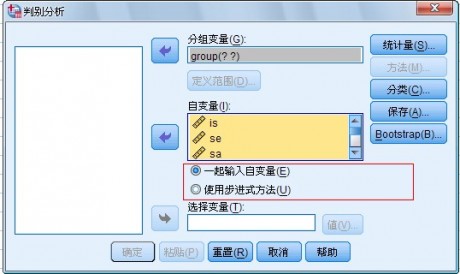
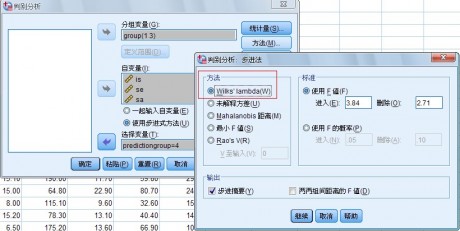
(4) 选择分析方法
在主对话框中自变量矩形框下面有两个选择项,被选中的方法前面的圆圈中加有黑点。这两个选择项是用于选择判别分析方法的
l Enter independent together 选项,当认为所有自变量都能对观测量特性提供丰富的信息时,使用该选择项。选择该项将不加选择地使用所有自变量进行判别分析,建立全模型,不需要进一步进行选择。
l Use stepwise method 选项,当不认为所有自变量都能对观测量特性提供丰富的信息时,使用该选择项。因此需要判别贡献的大小,再进行选择当鼠标单击该项时Method 按钮加亮,可以进一步选择判别分析方法。
2.Method对话框 如图 1-5 所示:
图 1-5 Stepwise Method 对话框
单击“Method”按钮展开Stepwise Method对话框。
(1)Method 栏选择进行逐步判别分析的方法
可供选择的判别分析方法有:
l Wilks’lambda 选项,每步都是Wilk 的概计量最小的进入判别函数
l Unexplained variance 选项,每步都是使各类不可解释的方差和最小的变量进入判别函数。
l Mahalanobis’distance 选项,每步都使靠得最近的两类间的Mahalanobis 距离最大的变量进入判别函数
l Smallest F ratio 选项,每步都使任何两类间的最小的F 值最大的变量进入判刑函数
l Rao’s V 选项,每步都会使Rao V 统计量产生最大增量的变量进入判别函数。可以对一个要加入到模型中的变量的V 值指定一个最小增量。选择此种方法后,应该在该项下面的V-to-enter 后的矩形框中输入这个增量的指定值。当某变量导致的V值增量大于指定值的变量后进入判别函数。
(2) Criteria 栏选择逐步判别停止的判据
可供选择的判据有:
l Use F value 选项,使用F值,是系统默认的判据当加人一个变量(或剔除一个变量)后,对在判别函数中的变量进行
方差分析。当计算的F值大于指定的Entry 值时,该变量保留在函数中。默认值是Entry为3.84:当该变量使计算的F值小于指定的Removal 值时,该变量从函数中剔除。默认值是Removal为2.71。即当被加入的变量F 值为3.84 时才把该变量加入到模型中,否则变量不能进入模型;或者,当要从模型中移出的变量F值<2.71时,该变量才被移出模型,否则模型中的变量不会被移出.设置这两个值时应该注意Entry值〉Removal 值。
l Use Probability of F选项,用F检验的概率决定变量是否加入函数或被剔除而不是用F值。加入变量的F值概率的默认值是0.05(5%);移出变量的F 值概率是0.10(10%)。Removal值(移出变量的F值概率) >Entry值(加入变量的F值概率)。
(3) Display栏显示选择的内容
对于逐步选择变量的过程和最后结果的显示可以通过Display 栏中的两项进行选择:
l Summary of steps 复选项,要求在逐步选择变量过程中的每一步之后显示每个变量的统计量。
l F for Pairwise distances 复选项,要求显示两两类之间的两两F 值矩阵。
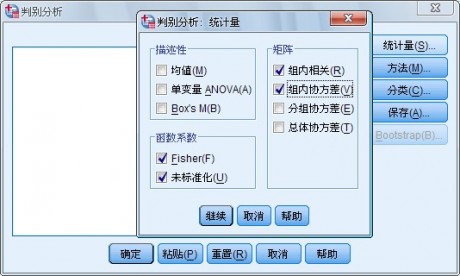
3.Statistics对话框 指定输出的统计量如图1-6 所示:
图 1-6 Statistics 对话框
可以选择的输出统计量分为以下3 类:
(l) 描述统计量
在 Descriptives 栏中选择对原始数据的描述统计量的输出:
l Means 复选项,可以输出各类中各自变量的均值MEAN、标准差std Dev 和各自变量总样本的均值和标准差。
l Univariate ANOV 复选项,对各类中同一自变量均值都相等的假设进行检验,输出单变量的
方差分析结果。
l Box’s M 复选项,对各类的协方差矩阵相等的假设进行检验。如果样本足够大,表明差异不显著的p 值表明矩阵差异不明显。
(2) Function coefficients 栏:选择判别函数系数的输出形式
l Fisherh’s 复选项,可以直接用于对新样本进行判别分类的费雪系数。对每一类给出一组系数。并给出该组中判别分数最大的观测量。
l Unstandardized 复选项,未经标准化处理的判别系数。
(3) Matrices 栏:选择自变量的系数矩阵
l Within-groups correlation matrix复选项,即类内相关矩阵,
它是根据在计算相关矩阵之前将各组(类)协方差矩阵平均后计算类内相关矩阵。
l Within-groups covariance matrix复选项,即计算并显示合并类内协方差矩阵,
是将各组(类)协方差矩阵平均后计算的。区别于总协方差阵。
l Separate-groups covariance matrices复选项,对每类输出显示一个协方差矩阵。
l Total covariance matrix复选项,计算并显示总样本的协方差矩阵。
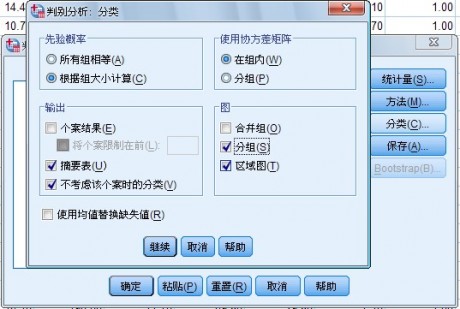
4.Classification 对话框指定分类参数和判别结果 如图1-7 所示
图 1-7 Classification 对话框
在主对话框中单击Classify 按钮展开相应的对话框
(1) 在 Prior Probabilities栏中选择
先验概率,两者选其一
l All groups equal 选项,各类
先验概率相等。若分为m类,则各类
先验概率均为1/m。
l Compute from groups sizes选项,由各类的样本量计算决定,即各类的
先验概率与其样本量成正比。
(2) Use Covariance Matrix 栏:选择分类使用的协方差矩阵
l Within-groups选项,指定使用合并组内协方差矩阵进行分类。
l Separate-groups选项,指定使用各组协方差矩阵进行分类。
由于分类是根据判别函数,而不是根据原始变量,因此该选择项不是总等价于二次判别。
(3) Plots 栏选择要求输出的统计图
l Combined-groups复选项,
生成一张包括各类的散点图。
l Separate-groups复选项,根据前两个判别函数值对每一类生成一张激点图,共分为几类就生成几张
散点图。如果只有一个判别函数就输出
直方图。
l Territorial map复选项,生成用于根据函数值把观测量分到各组中去的边界图。此种统计图把一张图的平面划分出与类数相同的区域。每一类占据一个区各类的均值在各区中用*号标出。如果仅有一个判别函数,则不作此图。
(4) Display 栏选择生成到输出窗中的分类结果
l Casewise results复选项,要求输出每个观测量包括判别分数、实际类、预测类(根据判别函数求得的分类结果)和后验概率等。选择此项还可以选择其附属选择项:Limits cases to复选项,并在后面的小矩形框中输入观测量数n 选择。此项则仅对前n个观测量输出分类结果。观测数量大时可以选择此项。
l Summary table复选项,要求输出分类的小结,给出正确分类观测量数(原始类和根据判别函数计算的预测类相同)和错分观测量数和错分率。
l Leave-one-out classification复选项,输出对每个观测量进行分类的结果,所依据的判别是由除该观测量以外的其他观测量导出的。也称为交互校验结果
(5) 在Classification对话框的最下面有一个选择项,用以选择对缺失值的处理方法。选中 Replace missing value with mean复选项,即用该变量的均值代替缺失值。该选择项前面的小矩形框中出现“.”时表示选定所示的处理方法.
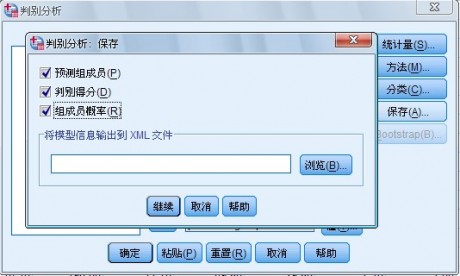
5.Save对话框,指定生成并保存在数据文件中的新变量。如图1-8 所示:
图 1-8 Save 对话框
(1) Predicted group membership复选项,要求建立一个新变量,预测观测量的分类。是根据判别分数把观测量按后验概率最大指派所属的类。每运行一次Discriminant过程,就建立一个表明使用判别函数预测各观测量属于哪一类的新变量。第1 次运行建立新变量的变量名为dis_l,如果在工作数据文件中不把前一次建立的新变量删除,第n次运行Descriminant 过程建立的新变量默认的变量名为dis_n。
(2) Discriminant score复选项,要求建立表明判别分数的新变量。该分数是由未标准化的判别系数乘自变量的值,将这些乘积求和后加上常数得来。每次运行Discriminant过程都给出一组表明判别分数的新变量,建立几个判别函数就有几个判别分数变量。参与分析的观测量共分为m类,则建立m个典则判别函数。指定该选择项,就可以生成m-l 个表明判别分数的新变量。
(3) Probabilities of group membership复选项,要求建立新变量,表明观测量属于某一类的概率。有m类,对一个观测量就会给出m个概率值,因此建立m 个新变量.
6.选择好各选择项之后,点击“OK”按钮,提交运行Discriminant过程。
附:判别分析
判别分析又称“分辨法”,是在分类确定的条件下,根据某一研究对象的各种
特征值判别其类型归属问题的一种多变量
统计分析方法。
其基本原理是按照一定的判别准则,建立一个或多个判别函数,用研究对象的大量资料确定判别函数中的待定系数,并计算判别指标。据此即可确定某一样本属于何类。
当得到一个新的样品数据,要确定该样品属于已知类型中哪一类,这类问题属于判别分析问题。
根据判别中的组数,可以分为两组判别分析和多组判别分析;
根据判别函数的形式,可以分为线性判别和非线性判别;
根据判别式处理变量的方法不同,可以分为逐步判别、序贯判别等;
根据判别标准不同,可以分为距离判别、Fisher判别、Bayes判别法等。
判别函数
判别分析通常都要设法建立一个判别函数,然后利用此函数来进行批判,判别函数主要有两种,即线性判别函数(Linear Discriminant Function)和典则判别函数(Canonical Discriminate Function)。
线性判别函数是指对于个总体,如果各组样品互相独立,且服从多元
正态分布,就可建立线性判别函数,形式如下:
Yi=a0+a1x1+a2x2+a3x3+…+anxn (i=1、2、…k)
其中,是K判别组数;是Yi判别指标(又称判别分数或判别值),根据所用的方法不同,可能是概率,也可能是坐标值或分值;x1…xn是自变量或预测变量,即反映研究对象
特征的变量;a0….an是各变量系数,也称判别系数。建立函数必须使用一个训练样品。所谓训练样品就是已知实际分类且各指标的观察值也已测得的样品,它对判别函数的建立非常重要。
典则判别函数是原始自变量的线性组合,通过建立少量的典则变量可以比较方便地描述各类之间的关系,例如可以用话
散点图和平面区域图直观地表示各类之间的相对关系等。
判别函数的建立方法
建立判别函数的方法一般由四种:全模型法、向前选择法、向后选择法和逐步选择法。
1)全模型法是指将用户指定的全部变量作为判别函数的自变量,而不管该变量是否对研究对象显著或对判别函数的贡献大小。此方法适用于对研究对象的各变量有全面认识的情况。如果未加选择的使用全变量进行分析,则可能产生较大的
偏差。
2)向前选择法是从判别模型中没有变量开始,每一步把一个队判别模型的判断能力贡献最大的哦变量引入模型,直到没有被引入模型的变量都不符合进入模型的条件时,变量引入过程结束。当希望较多变量留在判别函数中时,使用向前选择法。
3)向后选择法与向前选择法完全相反。它是把用户所有指定的变量建立一个全模型。每一步把一个对模型的判断能力贡献最小的变量剔除模型,知道模型中的所用变量都不符合留在模型中的条件时,剔除工作结束。在希望较少的变量留在判别函数中时,使用向后选择法。
4)逐步选择法是一种选择最能反映类间差异的变量子集,建立判别函数的方法。它是从模型中没有任何变量开始,每一步都对模型进行检验,将模型外对模型的判别贡献最大的变量加入到模型中,同时也检查在模型中是否存在“由于新变量的引入而对判别贡献变得不太显著”的 变量,如果有,则将其从模型中出,以此类推,知道模型中的所有变量都符合引入模型的条件,而模型外所有变量都不符合引入模型的条件为之,则整个过程结束。
判别方法
判别方法是确定待判样品归属于哪一组的方法,可分为参数法和非参数法,也可以根据资料的性质分为定性资料的判别分析和定量资料的判别分析。此处给出的分类主要是根据采用的判别准则分出几种常用方法。除最大似然法外,其余几种均适用于连续性资料。
1)最大似然法:用于自变量均为分类变量的情况,该方法建立在独立事件概率乘法定理的基础上,根据训练样品信息求得自变量各种组合情况下样品被封为任何一类的概率。当新样品进入是,则计算它被分到每一类中去的条件概率(似然值),概率最大的那一类就是最终评定的归类。
2)距离判别:其基本思想是有训练样品得出每个分类的重心坐标,然后对新样品求出它们离各个类别重心的距离远近,从而归入离得最近的类。最常用的距离是马氏距离,偶尔也采用欧式距离。距离判别的特点是直观、简单,适合于对自变量均为连续变量的情况下进行分类,且它对变量的分布类型无严格要求,特别是并不严格要求总体协方差阵相等。
3)Fisher判别:亦称典则判别,是根据线性Fisher函数值进行判别,通常用于线性判别问题,使用此准则要求各组变量的均值有显著性差异。该方法的基本思想是投影,即将原来在R维空间的自变量组合投影到维度较低的D维空间去,然后在D维空间中再进行分类。投影的原则是使得每一类的差异尽可能小,而不同类间投影的离差尽可能大。Fisher判别的优势在于对分布、方差等都没有任何限制,应用范围比较广。另外,用该判别方法建立的判别方差可以直接用手工计算的方法进行新样品的判别,这在许多时候是非常方便的。
4)Bayes判别:许多时候用户对各类别的比例分布情况有一定的先验信息,比如客户对投递广告的反应绝大多数都是无回音,如果进行判别,自然也应当是无回音的居多。此时,Bayes判别恰好适用。Bayes判别就是根据总体的
先验概率,使误判的平均损失达到最小二进行的判别。其最大优势是可以用于多组判别问题。但是适用此方法必须满足三个假设条件,即各种变量必须服从多元
正态分布、各组协方差矩阵必须相等、各组变量均值均有显著性差异。
判别函数效果的验证方法
对于判别分析,用户往往很关心建立的判别函数用于判别
分析时的准确度如何。通常的效果验证方法如自身验证、外部数据验证、样品二分法、交互验证、Bootstrap法。