在文本挖掘中,主题模型是比较特殊的一块,它的思想不同于我们常用的机器学习算法,因此这里我们需要专门来总结文本主题模型的算法。本文关注于潜在语义索引算法(LSI)的原理。
1. 文本主题模型的问题特点
在数据分析中,我们经常会进行非监督学习的聚类算法,它可以对我们的特征数据进行非监督的聚类。而主题模型也是非监督的算法,目的是得到文本按照主题的概率分布。从这个方面来说,主题模型和普通的聚类算法非常的类似。但是两者其实还是有区别的。
聚类算法关注于从样本特征的相似度方面将数据聚类。比如通过数据样本之间的欧式距离,曼哈顿距离的大小聚类等。而主题模型,顾名思义,就是对文字中隐含主题的一种建模方法。比如从“人民的名义”和“达康书记”这两个词我们很容易发现对应的文本有很大的主题相关度,但是如果通过词特征来聚类的话则很难找出,因为聚类方法不能考虑到到隐含的主题这一块。
那么如何找到隐含的主题呢?这个一个大问题。常用的方法一般都是基于统计学的生成方法。即假设以一定的概率选择了一个主题,然后以一定的概率选择当前主题的词。最后这些词组成了我们当前的文本。所有词的统计概率分布可以从语料库获得,具体如何以“一定的概率选择”,这就是各种具体的主题模型算法的任务了。
当然还有一些不是基于统计的方法,比如我们下面讲到的LSI。
2. 潜在语义索引(LSI)概述
潜在语义索引(Latent Semantic Indexing,以下简称LSI),有的文章也叫Latent Semantic Analysis(LSA)。其实是一个东西,后面我们统称LSI,它是一种简单实用的主题模型。LSI是基于奇异值分解(SVD)的方法来得到文本的主题的。而SVD及其应用我们在前面的文章也多次讲到,比如:奇异值分解(SVD)原理与在降维中的应用和矩阵分解在协同过滤推荐算法中的应用。如果大家对SVD还不熟悉,建议复习奇异值分解(SVD)原理与在降维中的应用后再读下面的内容。
这里我们简要回顾下SVD:对于一个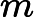
 m×n的矩阵
m×n的矩阵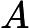 A,可以分解为下面三个矩阵:
A,可以分解为下面三个矩阵:
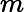
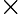
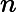

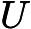
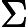
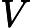
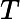 Am×n=Um×mΣm×nVn×nT
Am×n=Um×mΣm×nVn×nT
有时为了降低矩阵的维度到k,SVD的分解可以近似的写为:

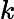 Am×n≈Um×kΣk×kVk×nT
Am×n≈Um×kΣk×kVk×nT
如果把上式用到我们的主题模型,则SVD可以这样解释:我们输入的有m个文本,每个文本有n个词。而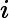
 Aij则对应第i个文本的第j个词的特征值,这里最常用的是基于预处理后的标准化TF-IDF值。k是我们假设的主题数,一般要比文本数少。SVD分解后,
Aij则对应第i个文本的第j个词的特征值,这里最常用的是基于预处理后的标准化TF-IDF值。k是我们假设的主题数,一般要比文本数少。SVD分解后, Uil对应第i个文本和第l个主题的相关度。Vjm对应第j个词和第m个词义的相关度。Σlm对应第l个主题和第m个词义的相关度。
Uil对应第i个文本和第l个主题的相关度。Vjm对应第j个词和第m个词义的相关度。Σlm对应第l个主题和第m个词义的相关度。
也可以反过来解释:我们输入的有m个词,对应n个文本。而Aij则对应第i个词档的第j个文本的特征值,这里最常用的是基于预处理后的标准化TF-IDF值。k是我们假设的主题数,一般要比文本数少。SVD分解后,Uil对应第i个词和第l个词义的相关度。Vjm对应第j个文本和第m个主题的相关度。Σlm对应第l个词义和第m个主题的相关度。
这样我们通过一次SVD,就可以得到文档和主题的相关度,词和词义的相关度以及词义和主题的相关度。
3. LSI简单实例
这里举一个简单的LSI实例,假设我们有下面这个有10个词三个文本的词频TF对应矩阵如下:
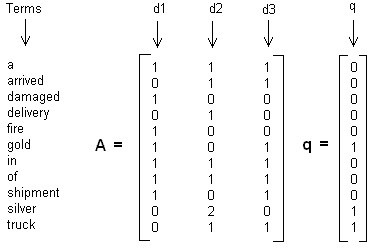
这里我们没有使用预处理,也没有使用TF-IDF,在实际应用中最好使用预处理后的TF-IDF值矩阵作为输入。
我们假定对应的主题数为2,则通过SVD降维后得到的三矩阵为:

从矩阵Uk我们可以看到词和词义之间的相关性。而从Vk可以看到3个文本和两个主题的相关性。大家可以看到里面有负数,所以这样得到的相关度比较难解释。
4. LSI用于文本相似度计算
在上面我们通过LSI得到的文本主题矩阵可以用于文本相似度计算。而计算方法一般是通过余弦相似度。比如对于上面的三文档两主题的例子。我们可以计算第一个文本和第二个文本的余弦相似度如下 :
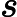

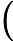
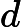



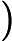



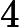

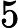

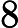


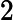
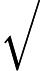
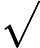 sim(d1,d2)=(−0.4945)∗(−0.6458)+(0.6492)∗(−0.7194)(−0.4945)2+0.64922(−0.6458)2+(−0.7194)2
sim(d1,d2)=(−0.4945)∗(−0.6458)+(0.6492)∗(−0.7194)(−0.4945)2+0.64922(−0.6458)2+(−0.7194)2
5. LSI主题模型总结
LSI是最早出现的主题模型了,它的算法原理很简单,一次奇异值分解就可以得到主题模型,同时解决词义的问题,非常漂亮。但是LSI有很多不足,导致它在当前实际的主题模型中已基本不再使用。
主要的问题有:
1) SVD计算非常的耗时,尤其是我们的文本处理,词和文本数都是非常大的,对于这样的高维度矩阵做奇异值分解是非常难的。
2) 主题值的选取对结果的影响非常大,很难选择合适的k值。
3) LSI得到的不是一个概率模型,缺乏统计基础,结果难以直观的解释。
对于问题1),主题模型非负矩阵分解(NMF)可以解决矩阵分解的速度问题。对于问题2),这是老大难了,大部分主题模型的主题的个数选取一般都是凭经验的,较新的层次狄利克雷过程(HDP)可以自动选择主题个数。对于问题3),牛人们整出了pLSI(也叫pLSA)和隐含狄利克雷分布(LDA)这类基于概率分布的主题模型来替代基于矩阵分解的主题模型。
回到LSI本身,对于一些规模较小的问题,如果想快速粗粒度的找出一些主题分布的关系,则LSI是比较好的一个选择,其他时候,如果你需要使用主题模型,推荐使用LDA和HDP。

数据分析咨询请扫描二维码
CDA数据分析师在中国航信高科技产业园进行了面向测试度量的数据分析培训课程,培训人数近2 ...
2024-05-01CDA数据分析师走进深圳迈瑞生物医疗电子股份有限公司,在迈瑞总部展开了为期两天的培训,本次课程参训人员线上及线下近百人, ...
2024-05-01CDA数据分析师在合肥市对合肥阳光新能源科技有限公司开展了为期8天的企业内训。 合肥阳光新能源科技 ...
2024-05-01CDA数据分析师走进海尔大学,进行了《数据治理与数据中台建设的道与术》专题培训,培训现场爆满,近百人参加了此次培训。 ...
2024-05-01在中国银行苏州分行培训中心开始数据分析师培训,此次培训课程共10天内容,包括Excel、MySQL、概率论与数理统计、SPSS等内容, ...
2024-05-01从实际的业务需求出发,结合行业的典型应用特点,围绕实际的商业问题,探讨数据挖掘、机器学习模型在金融领域的应用,包括获客、信用评分、细分画像、交叉销售、反欺诈、违规识别、时序预测、运筹优化、流程挖掘九个方面,形成 ...
2024-05-01本次培训课程为线上+线下的模式,由于学员编程能力不一、部分学员没有编程基础,故提供统计学、python基 ...
2024-05-01华夏银行信用卡中心-机器学习培训 1、课程亮点 取材于业界一流企业和顶级咨询公司的行业实践;已经被证明是人人 ...
2024-05-01主 题:数据中台建设及数据分析应用主题分享 1. 数据中台市场洞察 2. 主流数据中台产品比较 3. 某企业数据中 ...
2024-05-01围绕“数据驱动”战略,全力打造我行 300 人数字化人才梯队,着力培养数字化管理人才、大数据专业团队 ...
2024-05-01在当今数据驱动的商业环境中,数据分析成为了企业决策的重要依据。通过对大量数据的收集、处理和分析,企业能够更好地理解市场 ...
2024-04-29在人工智能(AI)的世界里,提示词(Prompt)是一种强大的工具,它能够引导AI按照用户的需求产生特定的输出。本文将深入探讨AI ...
2024-04-29CDA立足未来职场,拓展前沿视野——对外经贸大学保险学院举办“三全育人大讲堂”分享行业最新动态。 ...
2024-04-294月2日,CDA数据分析师创始发起人兼协会理事长赵坚毅博士受邀在浙江万里学院举办了一场以“数字化能力在职场中的作用” ...
2024-04-29随机森林(Random Forests)现在机器学习中比较火的一个算法,是一种基于Bagging的集成学习方法,能够很好地处理分类和回归的问 ...
2022-12-23方差分析是数据分析中常用的一种统计分析方法,接下来让我们简单了解一下方差分析的基本思想和原理吧。 方差分析(Analysis ...
2022-12-23来源:关于数据分析与可视化 关于streamlit-aggrid 数据排序 表格样式的调整 数据 ...
2022-08-03作者:麦叔 定义 「把上面晦涩的概念汇成一句话就是:」 ❝ 回调函数就是一个被作为参 ...
2022-08-03现今,高学历人群日益增多,物以稀为贵的高学历光环淡去。无论本科生还是研究生,甚至博士生,求职竞争力都大不如前,就业压力越来越大。
2022-06-01某家企业10个人面试,有9个本科生……如何脱颖而出,除得体的举止和良好的沟通力外,证书成重要筹码,这也是很多人考证的关键所在。
2022-04-14





