8个经过证实的方法:提高机器学习模型的准确率
提升一个模型的表现有时很困难。如果你们曾经纠结于相似的问题,那我相信你们中很多人会同意我的看法。你会尝试所有曾学习过的策略和算法,但模型正确率并没有改善。你会觉得无助和困顿,这是90%的数据科学家开始放弃的时候。
不过,这才是考验真本领的时候!这也是普通的数据科学家跟大师级数据科学家的差距所在。你是否曾经梦想过成为大师级的数据科学家呢?
如果是的话,你需要这 8 个经过证实的方法来重构你的模型。建立预测模型的方法不止一种。这里没有金科玉律。但是,如果你遵循我的方法(见下文),(在提供的数据足以用来做预测的前提下)你的模型会拥有较高的准确率。
我从实践中学习了到这些方法。相对于理论,我一向更热衷于实践。这种学习方式也一直在激励我。本文将分享 8 个经过证实的方法,使用这些方法可以建立稳健的机器学习模型。希望我的知识可以帮助大家获得更高的职业成就。.
模型的开发周期有多个不同的阶段,从数据收集开始直到模型建立。
不过,在通过探索数据来理解(变量的)关系之前,建议进行假设生成(hypothesis generation)步骤(如果想了解更多有关假设生成的内容,推荐阅读 why-and-when-is-hypothesis-generation-important )。我认为,这是预测建模过程中最被低估的一个步骤。
花时间思考要回答的问题以及获取领域知识也很重要。这有什么帮助呢?它会帮助你随后建立更好的特征集,不被当前的数据集误导。这是改善模型正确率的一个重要环节。
在这个阶段,你应该对问题进行结构化思考,即进行一个把此问题相关的所有可能的方面纳入考虑范围的思考过程。
现在让我们挖掘得更深入一些。让我们看看这些已被证实的,用于改善模型准确率的方法。
持有更多的数据永远是个好主意。相比于去依赖假设和弱相关,更多的数据允许数据进行“自我表达”。数据越多,模型越好,正确率越高。
我明白,有时无法获得更多数据。比如,在数据科学竞赛中,训练集的数据量是无法增加的。但对于企业项目,我建议,如果可能的话,去索取更多数据。这会减少由于数据集规模有限带来的痛苦。
训练集中缺失值与异常值的意外出现,往往会导致模型正确率低或有偏差。这会导致错误的预测。这是由于我们没能正确分析目标行为以及与其他变量的关系。所以处理好缺失值和异常值很重要。
仔细看下面一幅截图。在存在缺失值的情况下,男性和女性玩板球的概率相同。但如果看第二张表(缺失值根据称呼“Miss”被填补以后),相对于男性,女性玩板球的概率更高。
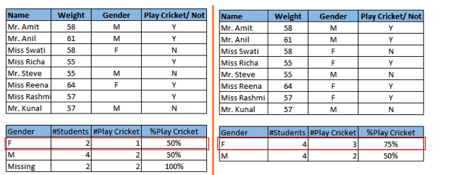
从上面的例子中,我们可以看出缺失值对于模型准确率的不利影响。所幸,我们有各种方法可以应对缺失值和异常值:
这一步骤有助于从现有数据中提取更多信息。新信息作为新特征被提取出来。这些特征可能会更好地解释训练集中的差异变化。因此能改善模型的准确率。
假设生成对特征工程影响很大。好的假设能带来更好的特征集。这也是我一直建议在假设生成上花时间的原因。特征工程能被分为两个步骤:
A) 把变量的范围从原始范围变为从 0 到 1 。这通常被称作数据标准化。比如,某个数据集中第一个变量以米计算,第二个变量是厘米,第三个是千米,在这种情况下,在使用任何算法之前,必须把数据标准化为相同范围。
B) 有些算法对于正态分布的数据表现更好。所以我们需要去掉变量的偏向。对数,平方根,倒数等方法可用来修正偏斜。
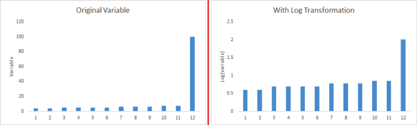
C) 有些时候,数值型的数据在分箱后表现更好,因为这同时也处理了异常值。数值型数据可以通过把数值分组为箱变得离散。这也被称为数据离散化。
创建新特征:从现有的变量中衍生出新变量被称为特征创建。这有助于释放出数据集中潜藏的关系。比如,我们想通过某家商店的交易日期预测其交易量。在这个问题上日期可能和交易量关系不大,但如果研究这天是星期几,可能会有更高的相关。在这个例子中,某个日期是星期几的信息是潜在的。我们可以把这个信息提取为新特征,优化模型。
特征选择是寻找众多属性的哪个子集合,能够最好的解释目标变量与各个自变量的关系的过程。
你可以根据多种标准选取有用的特征,例如:
所在领域知识:根据在此领域的经验,可以选出对目标变量有更大影响的变量。
可视化:正如这名字所示,可视化让变量间的关系可以被看见,使特征选择的过程更轻松。
统计参数:我们可以考虑 p 值,信息价值(information values)和其他统计参数来选择正确的参数。
PCA:这种方法有助于在低维空间表现训练集数据。这是一种降维技术。 降低数据集维度还有许多方法:如因子分析、低方差、高相关、前向后向变量选择及其他。
使用正确的机器学习算法是获得更高准确率的理想方法。但是说起来容易做起来难。
这种直觉来自于经验和不断尝试。有些算法比其他算法更适合特定类型数据。因此,我们应该使用所有有关的模型,并检测其表现。
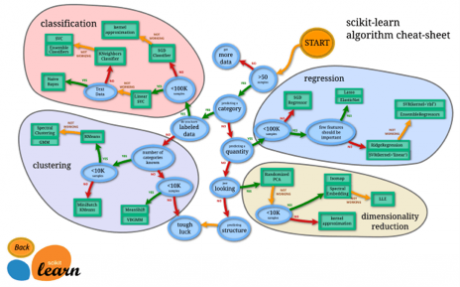
来源:Scikit-Learn 算法选择图
我们都知道机器学习算法是由参数驱动的。这些参数对学习的结果有明显影响。参数调整的目的是为每个参数寻找最优值,以改善模型正确率。要调整这些参数,你必须对它们的意义和各自的影响有所了解。你可以在一些表现良好的模型上重复这个过程。
例如,在随机森林中,我们有 max_features, number_trees, random_state, oob_score 以及其他参数。优化这些参数值会带来更好更准确的模型。
想要详细了解调整参数带来的影响,可以查阅《Tuning the parameters of your Random Forest model》。下面是随机森林算法在scikit learn中的全部参数清单:
RandomForestClassifier(n_estimators=10,criterion='gini',max_depth=None,min_samples_split=2,min_samples_leaf=1,min_weight_fraction_leaf=0.0,max_features='auto',max_leaf_nodes=None,bootstrap=True,oob_score=False,n_jobs=1,random_state=None,verbose=0,warm_start=False,class_weight=None)
在数据科学竞赛获胜方案中最常见的方法。这个技术就是把多个弱模型的结果组合在一起,获得更好的结果。它能通过许多方式实现,如:
Bagging (Bootstrap Aggregating)
Boosting
想了解更多这方面内容,可以查阅《Introduction to ensemble learning》。
使用集成方法改进模型正确率永远是个好主意。主要有两个原因:
1)集成方法通常比传统方法更复杂;
2)传统方法提供好的基础,在此基础上可以建立集成方法。
到目前为止,我们了解了改善模型准确率的方法。但是,高准确率的模型不一定(在未知数据上)有更好的表现。有时,模型准确率的改善是由于过度拟合。
如果想解决这个问题,我们必须使用交叉验证技术(cross validation)。交叉验证是数据建模领域最重要的概念之一。它是指,保留一部分数据样本不用来训练模型,而是在完成模型前用来验证。
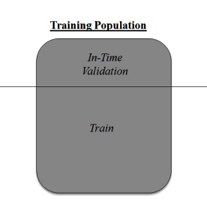
这种方法有助于得出更有概括性的关系。想了解更多有关交叉检验的内容,建议查阅《Improve model performance using cross validation》。
预测建模的过程令人疲惫。但是,如果你能灵活思考,就可以轻易胜过其他人。简单地说,多考虑上面这8个步骤。获得数据集以后,遵循这些被验证过的方法,你就一定会得到稳健的机器学习模型。不过,只有当你熟练掌握了这些步骤,它们才会真正有帮助。比如,想要建立一个集成模型,你必须对多种机器学习算法有所了解。
本文分享了 8 个经过证实的方法。这些方法用来改善模型的预测表现。它们广为人知,但不一定要按照文中的顺序逐个使用。

数据分析咨询请扫描二维码
CDA数据分析师在中国航信高科技产业园进行了面向测试度量的数据分析培训课程,培训人数近2 ...
2024-05-01CDA数据分析师走进深圳迈瑞生物医疗电子股份有限公司,在迈瑞总部展开了为期两天的培训,本次课程参训人员线上及线下近百人, ...
2024-05-01CDA数据分析师在合肥市对合肥阳光新能源科技有限公司开展了为期8天的企业内训。 合肥阳光新能源科技 ...
2024-05-01CDA数据分析师走进海尔大学,进行了《数据治理与数据中台建设的道与术》专题培训,培训现场爆满,近百人参加了此次培训。 ...
2024-05-01在中国银行苏州分行培训中心开始数据分析师培训,此次培训课程共10天内容,包括Excel、MySQL、概率论与数理统计、SPSS等内容, ...
2024-05-01从实际的业务需求出发,结合行业的典型应用特点,围绕实际的商业问题,探讨数据挖掘、机器学习模型在金融领域的应用,包括获客、信用评分、细分画像、交叉销售、反欺诈、违规识别、时序预测、运筹优化、流程挖掘九个方面,形成 ...
2024-05-01本次培训课程为线上+线下的模式,由于学员编程能力不一、部分学员没有编程基础,故提供统计学、python基 ...
2024-05-01华夏银行信用卡中心-机器学习培训 1、课程亮点 取材于业界一流企业和顶级咨询公司的行业实践;已经被证明是人人 ...
2024-05-01主 题:数据中台建设及数据分析应用主题分享 1. 数据中台市场洞察 2. 主流数据中台产品比较 3. 某企业数据中 ...
2024-05-01围绕“数据驱动”战略,全力打造我行 300 人数字化人才梯队,着力培养数字化管理人才、大数据专业团队 ...
2024-05-01在当今数据驱动的商业环境中,数据分析成为了企业决策的重要依据。通过对大量数据的收集、处理和分析,企业能够更好地理解市场 ...
2024-04-29在人工智能(AI)的世界里,提示词(Prompt)是一种强大的工具,它能够引导AI按照用户的需求产生特定的输出。本文将深入探讨AI ...
2024-04-29CDA立足未来职场,拓展前沿视野——对外经贸大学保险学院举办“三全育人大讲堂”分享行业最新动态。 ...
2024-04-294月2日,CDA数据分析师创始发起人兼协会理事长赵坚毅博士受邀在浙江万里学院举办了一场以“数字化能力在职场中的作用” ...
2024-04-29随机森林(Random Forests)现在机器学习中比较火的一个算法,是一种基于Bagging的集成学习方法,能够很好地处理分类和回归的问 ...
2022-12-23方差分析是数据分析中常用的一种统计分析方法,接下来让我们简单了解一下方差分析的基本思想和原理吧。 方差分析(Analysis ...
2022-12-23来源:关于数据分析与可视化 关于streamlit-aggrid 数据排序 表格样式的调整 数据 ...
2022-08-03作者:麦叔 定义 「把上面晦涩的概念汇成一句话就是:」 ❝ 回调函数就是一个被作为参 ...
2022-08-03现今,高学历人群日益增多,物以稀为贵的高学历光环淡去。无论本科生还是研究生,甚至博士生,求职竞争力都大不如前,就业压力越来越大。
2022-06-01某家企业10个人面试,有9个本科生……如何脱颖而出,除得体的举止和良好的沟通力外,证书成重要筹码,这也是很多人考证的关键所在。
2022-04-14





